在操作数据过程中,可能会导致数据错误,甚至数据库奔溃,而有效的定时备份能很好地保护数据库。本篇文章主要讲述了几种方法进行 MySQL 定时备份数据库。
在MySQL中提供了命令行导出数据库数据以及文件的一种方便的工具mysqldump,我们可以通过命令行直接实现数据库内容的导出dump,首先我们简单了解一下mysqldump命令用法:
#MySQLdump常用
mysqldump -u root -p --databases 数据库1 数据库2 > xxx.sql
mysqldump -uroot -p123456 -A > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 -A -d > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 -A -t > /data/mysqlDump/mydb.sql
mysqldump -uroot-p123456 mydb > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 mydb -d > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 mydb -t > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 mydb t1 t2 > /data/mysqlDump/mydb.sql
mysqldump -uroot -p123456 --databases db1 db2 > /data/mysqlDump/mydb.sql
有两种方式还原,第一种是在 MySQL 命令行中,第二种是使用 SHELL 行完成还原
mysql -uroot -p123456 < /data/mysqlDump/mydb.sql
mysql> source /data/mysqlDump/mydb.sql
在 Linux中,通常使用BASH脚本对需要执行的内容进行编写,加上定时执行命令crontab实现日志自动化生成。
以下代码功能就是针对mysql进行备份,配合crontab,实现备份的内容为近一个月(31天)内的每天的mysql数据库记录。
编写BASH维护固定数量备份文件
在Linux中,使用vi或者vim编写脚本内容并命名为:mysql_dump_script.sh
#!/bin/bash
#保存备份个数,备份31天数据
number=31
#备份保存路径
backup_dir=/root/mysqlbackup
#日期
dd=`date +%Y-%m-%d-%H-%M-%S`
#备份工具
tool=mysqldump
#用户名
username=root
#密码
password=TankB214
#将要备份的数据库
database_name=edoctor
#如果文件夹不存在则创建
if [ ! -d $backup_dir ];
then
mkdir -p $backup_dir;
fi
#简单写法 mysqldump -u root -p123456 users > /root/mysqlbackup/users-$filename.sql
$tool -u $username -p$password $database_name > $backup_dir/$database_name-$dd.sql
#写创建备份日志
echo "create $backup_dir/$database_name-$dd.dupm" >> $backup_dir/log.txt
#找出需要删除的备份
delfile=`ls -l -crt $backup_dir/*.sql | awk '{print $9 }' | head -1`
#判断现在的备份数量是否大于$number
count=`ls -l -crt $backup_dir/*.sql | awk '{print $9 }' | wc -l`
if [ $count -gt $number ]
then
#删除最早生成的备份,只保留number数量的备份
rm $delfile
#写删除文件日志
echo "delete $delfile" >> $backup_dir/log.txt
fi
如上代码主要含义如下:
1.首先设置各项参数,例如number最多需要备份的数目,备份路径,用户名,密码等。
2.执行mysqldump命令保存备份文件,并将操作打印至同目录下的log.txt中标记操作日志。
3.定义需要删除的文件:通过ls命令获取第九列,即文件名列,再通过实现定义操作时间最晚的那个需要删除的文件。
4.定义备份数量:通过ls命令加上wc -l统计以sql结尾的文件的行数。
5.如果文件超出限制大小,就删除最早创建的sql文件
使用crontab定期执行备份脚本
在 Linux 中,周期执行的任务一般由cron这个守护进程来处理[ps -ef|grep cron]。cron读取一个或多个配置文件,这些配置文件中包含了命令行及其调用时间。cron的配置文件称为“crontab”,是“cron table”的简写。
cron服务
cron是一个 Liunx 下 的定时执行工具,可以在无需人工干预的情况下运行作业。
service crond start //启动服务
service crond stop //关闭服务
service crond restart //重启服务
service crond reload //重新载入配置
service crond status //查看服务状态
crontab语法
crontab命令用于安装、删除或者列出用于驱动cron后台进程的表格。用户把需要执行的命令序列放到crontab文件中以获得执行。每个用户都可以有自己的crontab文件。/var/spool/cron下的crontab文件不可以直接创建或者直接修改。该crontab文件是通过crontab命令创建的。
在crontab文件中如何输入需要执行的命令和时间。该文件中每行都包括六个域,其中前五个域是指定命令被执行的时间,最后一个域是要被执行的命令。每个域之间使用空格或者制表符分隔。
格式如下:
minute hour day-of-month month-of-year day-of-week commands
合法值 00-59 00-23 01-31 01-12 0-6 (0 is sunday)
除了数字还有几个个特殊的符号就是"*"、"/"和"-"、",",*代表所有的取值范围内的数字,"/"代表每的意思,"/5"表示每5个单位,"-"代表从某个数字到某个数字,","分开几个离散的数字。
-l 在标准输出上显示当前的crontab。
-r 删除当前的crontab文件。
-e 使用VISUAL或者EDITOR环境变量所指的编辑器编辑当前的crontab文件。当结束编辑离开时,编辑后的文件将自动安装。
创建cron脚本
第一步:写cron脚本文件,命名为mysqlRollBack.cron。15,30,45,59 * * * * echo "xgmtest....." >> xgmtest.txt 表示,每隔15分钟,执行打印一次命令
第二步:添加定时任务。执行命令 “crontab crontest.cron”。搞定
第三步:"crontab -l" 查看定时任务是否成功或者检测/var/spool/cron下是否生成对应cron脚本
注意:这操作是直接替换该用户下的crontab,而不是新增
定期执行编写的定时任务脚本(记得先给shell脚本执行权限)
0 2 * * * /root/mysql_backup_script.sh
随后使用crontab命令定期指令编写的定时脚本
crontab mysqlRollback.cron
再通过命令检查定时任务是否已创建:
附 crontab 的使用示例:
1.每天早上6点
0 6 * * * echo "Good morning." >> /tmp/test.txt //注意单纯echo,从屏幕上看不到任何输出,因为cron把任何输出都email到root的信箱了。
2.每两个小时
0 */2 * * * echo "Have a break now." >> /tmp/test.txt
3.晚上11点到早上8点之间每两个小时和早上八点
0 23-7/2,8 * * * echo "Have a good dream" >> /tmp/test.txt
4.每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
0 11 4 * 1-3 command line
5.1月1日早上4点
0 4 1 1 * command line SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root //如果出现错误,或者有数据输出,数据作为邮件发给这个帐号 HOME=/
6.每小时执行/etc/cron.hourly内的脚本
01 * * * * root run-parts /etc/cron.hourly
7.每天执行/etc/cron.daily内的脚本
02 4 * * * root run-parts /etc/cron.daily
8.每星期执行/etc/cron.weekly内的脚本
22 4 * * 0 root run-parts /etc/cron.weekly
9.每月去执行/etc/cron.monthly内的脚本
42 4 1 * * root run-parts /etc/cron.monthly
注意: "run-parts" 这个参数了,如果去掉这个参数的话,后面就可以写要运行的某个脚本名,而不是文件夹名。
10.每天的下午4点、5点、6点的5 min、15 min、25 min、35 min、45 min、55 min时执行命令。
5,15,25,35,45,55 16,17,18 * * * command
11.每周一,三,五的下午3:00系统进入维护状态,重新启动系统。
00 15 * * 1,3,5 shutdown -r +5
12.每小时的10分,40分执行用户目录下的innd/bbslin这个指令:
10,40 * * * * innd/bbslink
13.每小时的1分执行用户目录下的bin/account这个指令:
1 * * * * bin/account
以下是我的测试每分钟的截图效果,其对应代码如下:
* * * * * /root/mysql_backup_script.sh
效果截图:
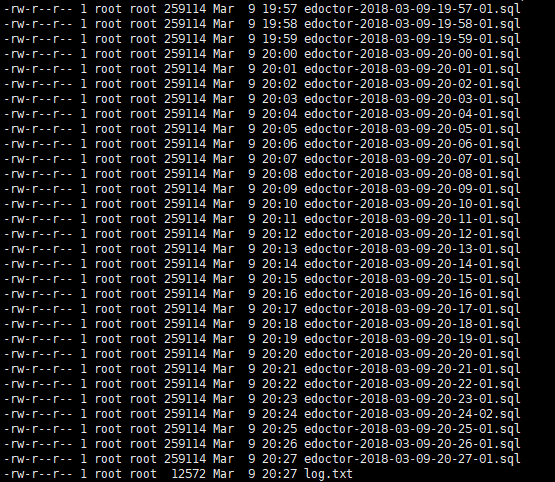
其中的log.txt记录备份的操作详细日志:
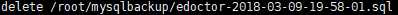
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
这是针对我无法破坏的现有公共(public)API,但我确实希望对其进行扩展。目前,该方法采用字符串或符号或任何其他在作为第一个参数传递给send时有意义的内容我想添加发送字符串、符号等列表的功能。我可以只使用is_a吗?数组,但还有其他发送列表的方法,这不是很像ruby。我将调用列表中的map,所以第一个倾向是使用respond_to?:map。但是字符串也会响应:map,所以这行不通。 最佳答案 如何将它们全部视为数组?String的行为与仅包含String的Array相同:deffoo(obj,arg)[*arg].eac
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。