query,根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的。
filter,根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。
# filter查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"corpName": "盒马鲜生"
}
},
{
"range": {
"fee": {
"lte": 4
}
}
}
]
}
}
}// Java实现filter操作
@Test
public void filter() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.termQuery("corpName","盒马鲜生"));
boolQuery.filter(QueryBuilders.rangeQuery("fee").lte(5));
builder.query(boolQuery);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
高亮查询就是你用户输入的关键字,以一定的特殊样式展示给用户,让用户知道为什么这个结果被检索出来。
高亮展示的数据,本身就是文档中的一个Field,单独将Field以highlight的形式返回给你。
ES提供了一个highlight属性,和query同级别的。
fragment_size:指定高亮数据展示多少个字符回来。
pre_tags:指定前缀标签,举个栗子< font color="red" >
post_tags:指定后缀标签,举个栗子< /font >
fields:指定哪几个Field以高亮形式返回
RESTful实现
# highlight查询 POST /sms-logs-index/sms-logs-type/_search { "query": { "match": { "smsContent": "盒马" } }, "highlight": { "fields": { "smsContent": {} }, "pre_tags": "<font color='red'>", "post_tags": "</font>", "fragment_size": 10 } }
/ Java实现高亮查询
@Test
public void highLightQuery() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件(高亮)
SearchSourceBuilder builder = new SearchSourceBuilder();
//2.1 指定查询条件
builder.query(QueryBuilders.matchQuery("smsContent","盒马"));
//2.2 指定高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("smsContent",10)
.preTags("<font color='red'>")
.postTags("</font>");
builder.highlighter(highlightBuilder);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取高亮数据,输出
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getHighlightFields().get("smsContent"));
}
} 
ES的聚合查询和MySQL的聚合查询类似,ES的聚合查询相比MySQL要强大的多,ES提供的统计数据的方式多种多样。
下图名字可以随便起
# ES聚合查询的RESTful语法
POST /index/type/_search
{
"aggs": {
"名字(agg)": {
"agg_type": {
"属性": "值"
}
}
}
}
去重计数,即Cardinality,第一步先将返回的文档中的一个指定的field进行去重,统计一共有多少条
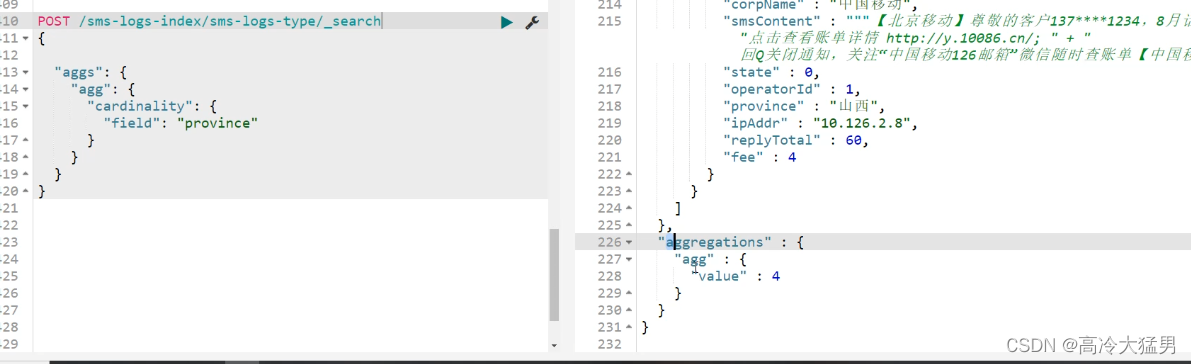
# 去重计数查询 北京 上海 武汉 山西
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"cardinality": {
"field": "province"
}
}
}
}
// Java代码实现去重计数查询
@Test
public void cardinality() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.cardinality("agg").field("province"));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Cardinality agg = resp.getAggregations().get("agg");
long value = agg.getValue();
System.out.println(value);
}
统计一定范围内出现的文档个数,比如,针对某一个Field的值在 0~100,100~200,200~300之间文档出现的个数分别是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range,date_range,ip_range
数值统计
# 数值方式范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"range": {
"field": "fee",
"ranges": [
{
"to": 5
},
{
"from": 5, # from有包含当前值的意思
"to": 10
},
{
"from": 10
}
]
}
}
}
}
# 时间方式范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"date_range": {
"field": "createDate",
"format": "yyyy",
"ranges": [
{
"to": 2000
},
{
"from": 2000
}
]
}
}
}
}# ip方式 范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"ip_range": {
"field": "ipAddr",
"ranges": [
{
"to": "10.126.2.9"
},
{
"from": "10.126.2.9"
}
]
}
}
}
}from表示包含当前值得意思 上图表示0-5 ,5-10 (包含5不含10),10以上(包含10)
// Java实现数值 范围统计
@Test
public void range() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.range("agg").field("fee")
.addUnboundedTo(5)
.addRange(5,10)
.addUnboundedFrom(10));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Range agg = resp.getAggregations().get("agg");
for (Range.Bucket bucket : agg.getBuckets()) {
String key = bucket.getKeyAsString();
Object from = bucket.getFrom();
Object to = bucket.getTo();
long docCount = bucket.getDocCount();
System.out.println(String.format("key:%s,from:%s,to:%s,docCount:%s",key,from,to,docCount));
}
}
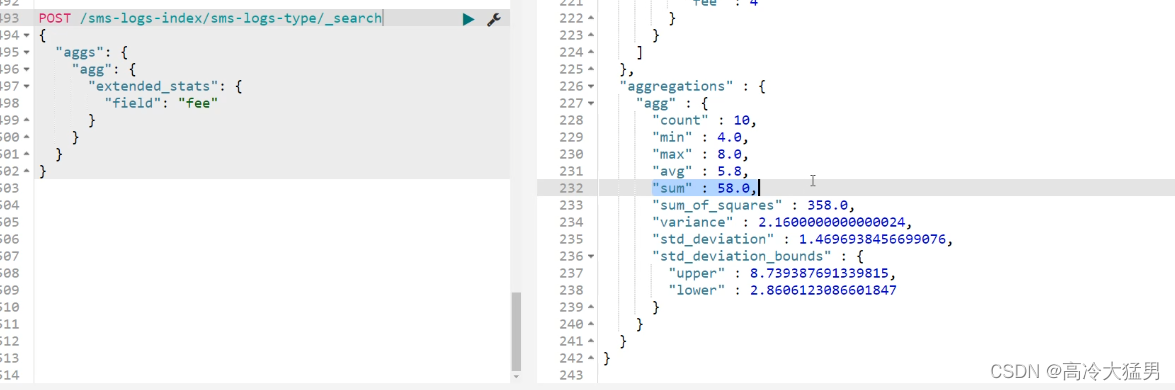
他可以帮你查询指定Field的最大值,最小值,平均值,平方和等
使用:extended_stats
# 统计聚合查询
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"extended_stats": {
"field": "fee"
}
}
}
} 
// Java实现统计聚合查询
@Test
public void extendedStats() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.extendedStats("agg").field("fee"));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
ExtendedStats agg = resp.getAggregations().get("agg");
double max = agg.getMax();
double min = agg.getMin();
System.out.println("fee的最大值为:" + max + ",最小值为:" + min);
}
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
什么是Linq聚合方法的ruby等价物。它的工作原理是这样的varfactorial=new[]{1,2,3,4,5}.Aggregate((acc,i)=>acc*i);每次将数组序列中的值传递给lambda时,变量acc都会累积。 最佳答案 这在数学以及几乎所有编程语言中通常称为折叠。它是更普遍的变形概念的一个实例。Ruby从Smalltalk中继承了这个特性的名称,它被称为inject:into:(像aCollectioninject:aStartValueinto:aBlock一样使用。)所以,在Ruby中,它称为inj