作为初学者,了解两种最常用的数据库类型是必不可少的:SQL和NoSQL。在本文中,我已尽力提供一个全面的指南,帮助初学者了解 SQL 和 NoSQL 之间的区别、它们的用例以及它们比另一个表现更好的场景。此处的信息将为您提供 SQL 和 NoSQL 数据库的概述,并重点介绍每种数据库的优缺点。到本文结束时,您将能够就为您的项目使用哪种类型的数据库做出明智的决定。无论您是软件开发人员、数据分析师,还是希望存储和管理数据的企业主,此信息都对您很有价值且相关。
那么,让我们深入探索 SQL 和 NoSQL 数据库的世界。
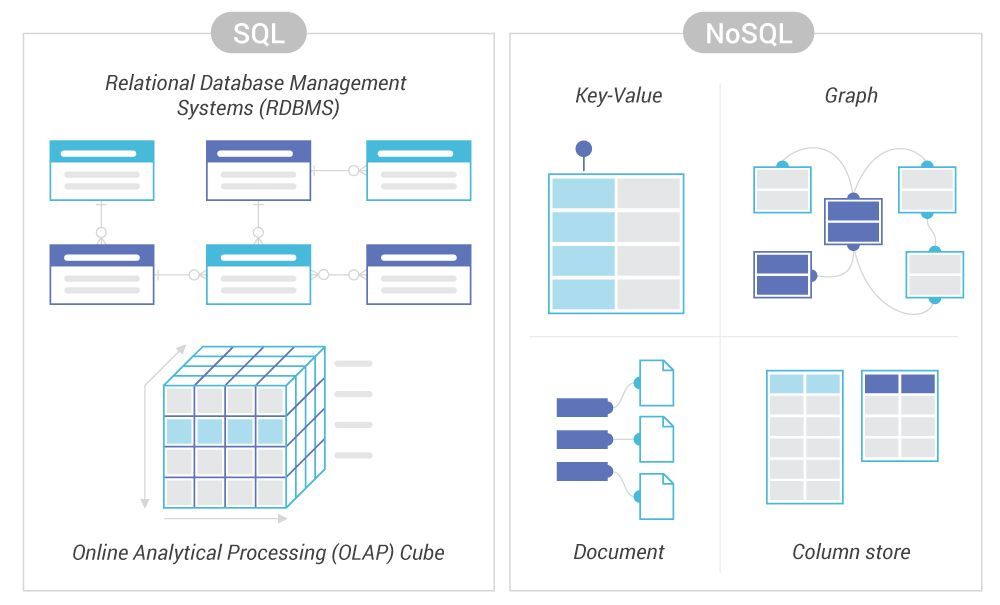
何时使用 SQL 或 NoSQL 没有硬性规定,特定项目的最佳选择将取决于项目的具体需求和约束。
SQL 数据库通常比 NoSQL 数据库使用更广泛。根据 DB-Engines的一项调查,在流行度和使用率上排名前五的数据库都是 SQL 数据库(Oracle、MySQL、Microsoft SQL Server、PostgreSQL 和 SQLite)。
这些只是几个示例,SQL 和 NoSQL 还有许多其他用例。
特定项目的最佳技术将取决于项目的具体需求和限制。
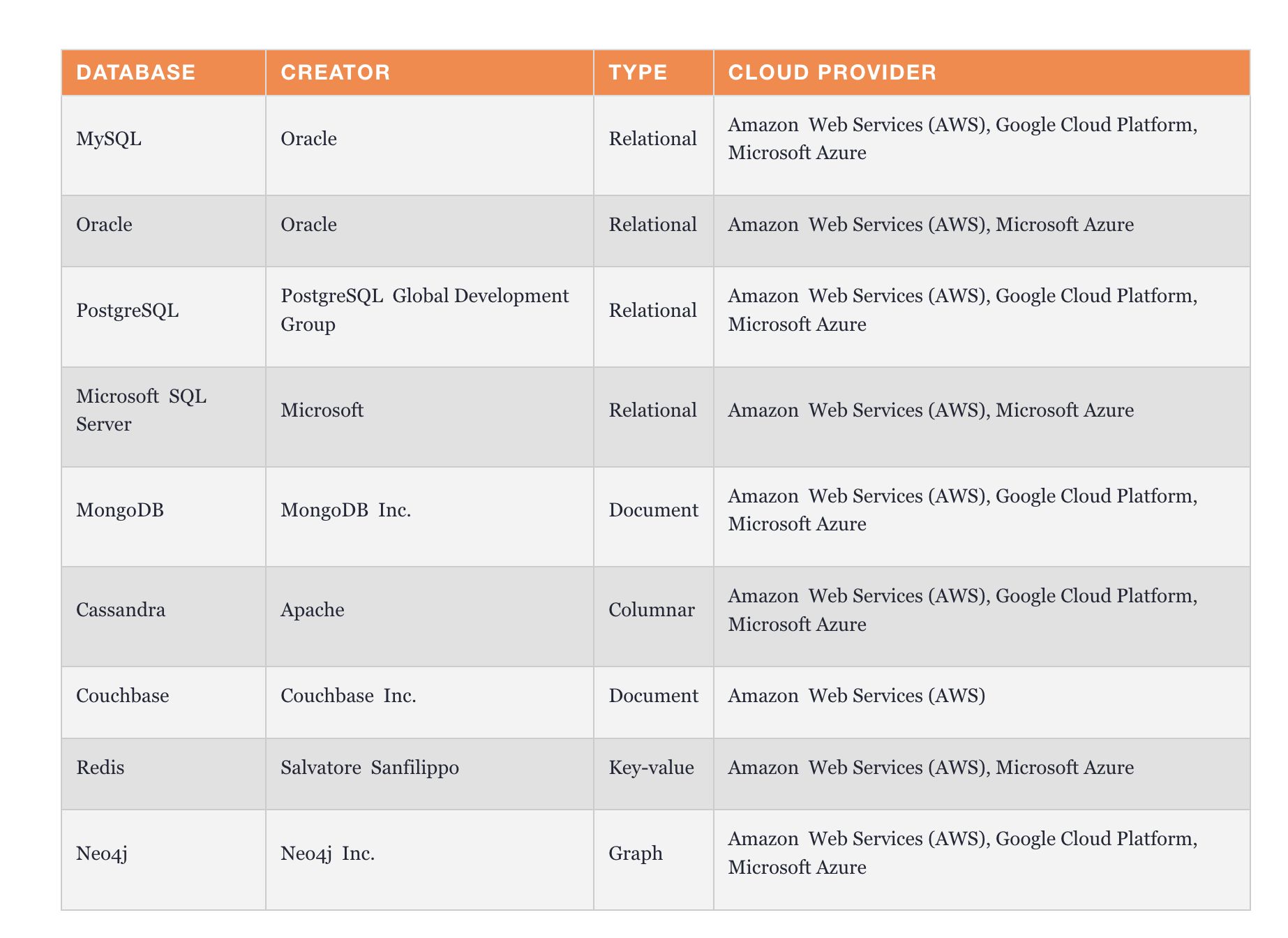
大多数主要的云提供商都提供各种 SQL 和 NoSQL 数据库作为服务。以下是一些主要云提供商提供的数据库类型的一些示例:
在为特定项目选择 SQL 和 NoSQL 时,需要牢记一些最佳实践(这不是最终列表):
为了帮助企业应用程序在 SQL 和 NoSQL 之间做出选择,您可以考虑使用数据库性能基准测试工具、数据库设计和建模工具以及数据库管理和监控工具等工具。这些类型的工具的一些示例包括:
我是企业 API 开发团队的一员,最初我们开始使用 SQL 数据库。后来当我们的组织采用 NoSQL 时,考虑到我们将扩展并且其他一切都会顺利的事实,我们搬到了那里。
然而,我们开始遇到规模、性能、索引等挑战。使用 NoSQL 数据库的挑战之一是它们通常缺乏关系数据库提供的强大的数据一致性保证。您需要记住分布式环境中的“最终一致性”。这意味着在某些情况下数据可能会变得不一致或过时,例如当多个客户端同时更新相同的数据时。
所以作为初学者,我们从来没有想过这个场景,逐渐开始学习和重新设计数据库架构,从记录走向文档。NoSQL 数据库旨在处理大量数据和高读写吞吐量,但优化其性能需要深入了解数据库的体系结构和配置设置。
需要从只关注关系的心态转变。数据库是存储数据的地方,遵循特定的数据结构。考虑从充满业务逻辑的存储过程转移到仅应用程序的业务逻辑:数据库内部将没有逻辑。在充分利用 NoSQL 的同时,必须更好地进行数据建模和设计索引。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption