这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案。小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果。之前在NER系列中我们已经介绍过Data Augmentation,不熟悉的童鞋看过来 中文NER的那些事儿4. 数据增强在NER的尝试。样本增强是通过提高标注样本的丰富度来提升模型泛化性,另一个方向半监督方案则是通过利用大量的相同领域未标注数据来提升模型的样本外预测能力。这一章我们来聊聊半监督方案中的一致性正则~
一致性正则~一个好的分类器应该对相似的样本点给出一致的预测,于是在训练中通过约束样本和注入噪声的样本要拥有相对一致的模型预测,来降低模型对局部扰动的敏感性,为模型参数拟合提供更多的约束。施工中的SimpleClassifcation提供了Temporal Ensemble的相关实现,可以支持多种预训练或者词袋模型作为backbone,欢迎来一起Debug >(*^3^)<
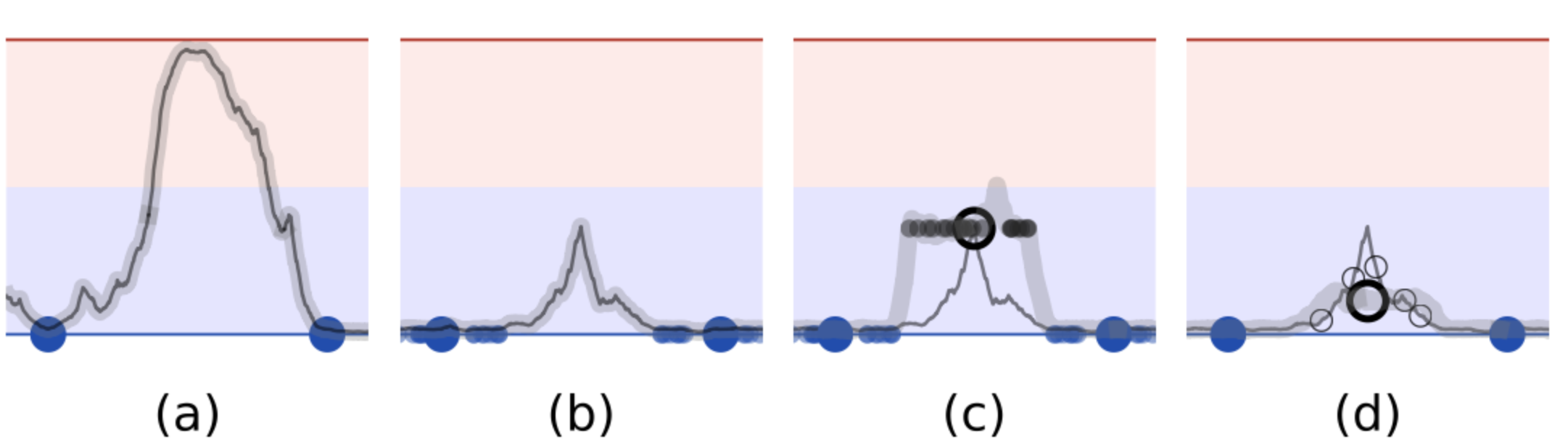
上图很形象的描述了一致性正则是如何利用标注和未标注数据来约束曲线拟合
a. 指用两个标注样本训练(大蓝点),因为样本少所以对模型拟合缺乏约束
b. 对标注样本注入噪音(小蓝点),并约束噪声样本和原始样本预测一致,通过拓展标注样本覆盖的空间,对模型拟合施加了更多的约束
c. 在对标注样本拟合之后,冻结模型,对未标注样本(空心点)进行一致性约束。因为一致性约束并不需要用到label因此可以充分利用未标注数据
d. 用未标注样本上一致性约束的loss来更新模型,使得模型对噪声更加鲁棒
以下三种方案采用了不同的噪声注入和Ensemble方式,前两个方案来自【REF1】Temporal Ensemble,第三个方案来自【REF2】Mean Teacher。因为合并了2篇paper,所以我们先整体过一下3种训练框架,再说训练技巧和一致性正则的一些insights。

如上图,针对每个样本,Π-MODEL会进行两次不同的增强,以及网络本身的随机drop out得到两个预测结果,一致性正则loss使用了MSE来计算两次预测结果的差异,既约束模型对输入样本的局部扰动要更加鲁棒。模型目标是有标注样本的cross- entropy,结合全样本的一致性正则loss
Π-MODEL的训练效率较低,因为每个样本都要计算两遍。

以上Π-MODEL在同一个epoch内对样本注入不同噪音的预测值进行约束,这部分约束会存在噪声较大,以及在epoch之间相对割裂的问题。因此作者引入Ensemble的思路在时间维度(epoch)做移动平均,来降低一致性loss的波动性。Temporal Ensemble通过约束各个epoch预测值的加权移动平均值\(Z\),和当前epoch预测值\(z\)的相对一致,来实现一致性正则,当\(\alpha=0\)的时候Temporal就退化成了Π-MODEL。
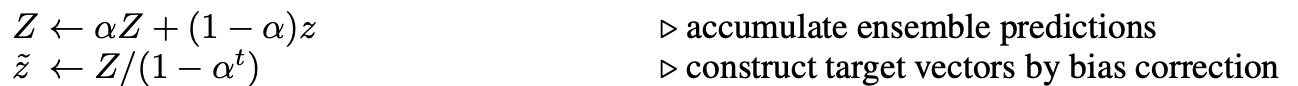
因此Temporal需要引入Sample_size * label_size的额外变量\(Z\),来存储每个样本在各个epoch上预测值的加权移动平均,如果你的样本非常大,则Temporal额外存储预测的变量会是很大的内存开销,以下为temporal部分的相关实现~
with tf.variable_scope('temporal_ensemble'):
temporal_ensemble = tf.get_variable(initializer=tf.zeros_initializer,
shape=(self.params['sample_size'], self.params['label_size']),
dtype=tf.float32, name='temporal_ensemble', trainable=False)
self.Z = tf.nn.embedding_lookup(temporal_ensemble, features['idx']) # batch_size * label_size
self.Z = self.alpha * self.Z + (1 - self.alpha) * preds
self.assign_op = tf.scatter_update(temporal_ensemble, features['idx'], self.Z)
add_layer_summary('ensemble', self.Z)
所以对比Π-MODEL,Temporal的一致性约束更加平滑,整体效果更好,以及计算效率更高因为每个样本只需要做一次预测,不过因为移动平均的引入会占用更多的内存~
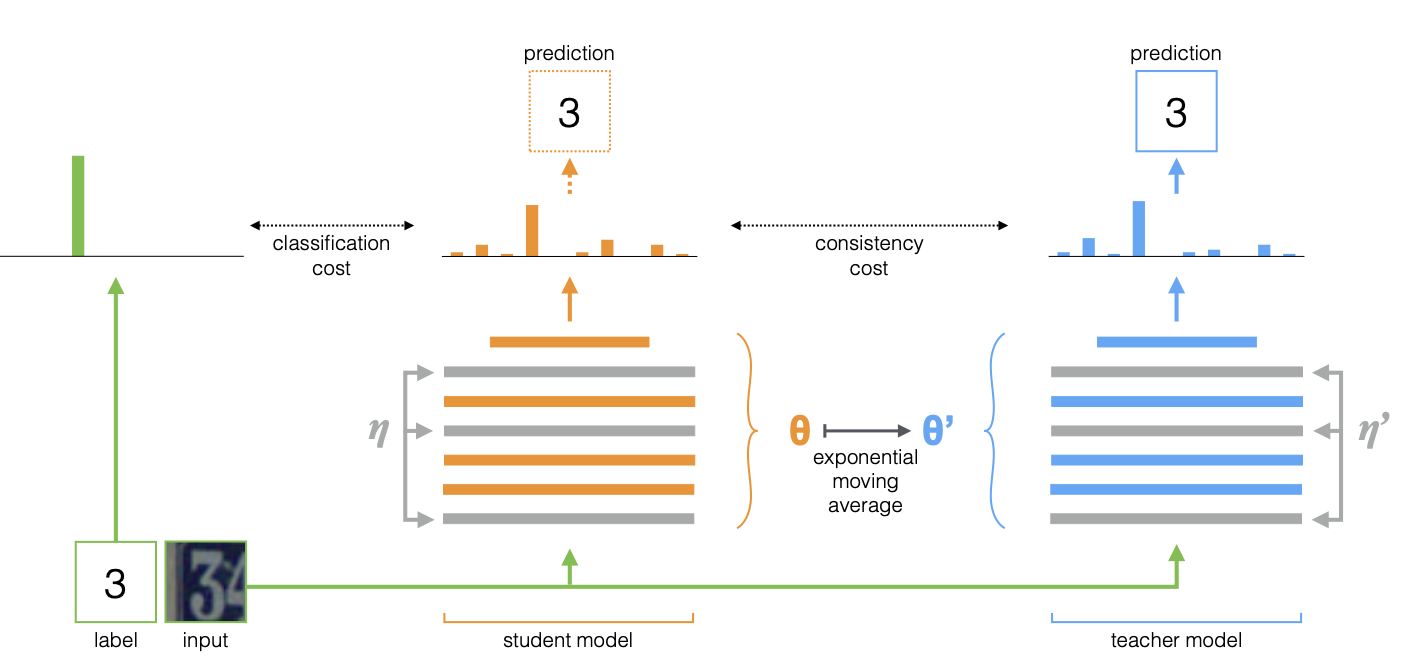
Mean Teacher是在Temporal的基础上调整了Ensemble实现的方案。Temporal是对每个样本的模型预测做Ensemble,所以每个epoch每个样本的移动平均才被更新一次,而Mean Teacher是对模型参数做Ensemble,这样每个step,student模型的更新都会反应在当前teacher模型上。
和Temporal无比相似的公式,差异只在于上面的Z是模型输出,下面的\(\theta\)是模型参数, 同样当\(\alpha=0\)的时候,Mean Teacher也退化成Π-MODEL。
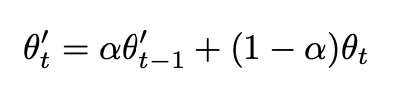
所以训练过程如下
效果上Mean Teacher要优于Temporal,不过在计算效率上和Π-MODEL一样都需要预测两遍,所以要比Temporal慢不少,以及因为要存储模型参数的移动平均,所以内存占用也让人很头疼,所以Mean Teacher这块并没做相关的实现,对大模型并不太友好~
以上的噪声注入和Ensemble需要搭配一些特定的训练技巧。
在训练初期,模型应该以有监督目标为主,逐步增加一致性loss的权重,在temporal ensemble上更容易解释,因为当epoch=0时,\(\hat{z}\)是拿不到前一个epoch的预测结果的,因此一致性loss权重为0。代码中支持了线性,cosine,sigmoid等三种权重预热方案,原文中使用的是sigmoid
def ramp_up(cur_epoch, max_epoch, method):
"""
根据训练epoch来调整无标注loss部分的权重,初始epoch无标注loss权重为0
"""
def linear(cur_epoch, max_epoch):
return cur_epoch / max_epoch
def sigmoid(cur_epoch, max_epoch):
p = 1.0 - cur_epoch / max_epoch
return tf.exp(-5.0 * p ** 2)
def cosine(cur_epoch, max_epoch):
p = cur_epoch / max_epoch
return 0.5 * (tf.cos(np.pi * p) + 1)
if cur_epoch == 0:
weight = tf.constant(0.0)
else:
if method == 'linear':
weight = linear(cur_epoch, max_epoch)
elif method == 'sigmoid':
weight = sigmoid(cur_epoch, max_epoch)
elif method == 'cosine':
weight = cosine(cur_epoch, max_epoch)
else:
raise ValueError('Only linear, sigmoid, cosine method are supported')
return tf.cast(weight, tf.float32)
因为以上方案多用于半监督任务,因此需要根据无标注样本的占比来调整一致性正则部分的权重。最简单的就是直接用有标注样本占比来对以上的weight做rescale,有标注占比越高,一致性loss的权重约高,避免模型过度关注正则项。
针对一致性正则的损失函数到底使用MSE还是KL,两篇paper都进行了对比,虽然从理论上KL更合逻辑,因为是对预测的概率分布进行一致性约束,但整体上MSE的效果更好。我猜测和NN倾向于给出over confident的预测相关,尤其是Bert一类的大模型会集中给出0.9999这种预测概率,在KL计算时容易出现极端值
以上两种ensemble的策略除了能提升半标注样本的效果之外,还有以下的额外效果加成
模糊标签:作者在全标注的样本上也尝试了self-ensemble的效果,对预测结果也有提升,猜测这源于一致性正则在一定程度上可能改进边缘/模糊label的样本效果
降噪:作者把x%的训练样本赋予随机label,然后对比常规训练和temporarl ensemble的效果。结果如下temporal对局部的标注噪音有很好的降噪效果。正确样本的监督loss帮助模型学习文本表征到label的mapping,而在正确样本附近的误标注样本会被一致性正则约束,从而降低错误标签对模型的影响。
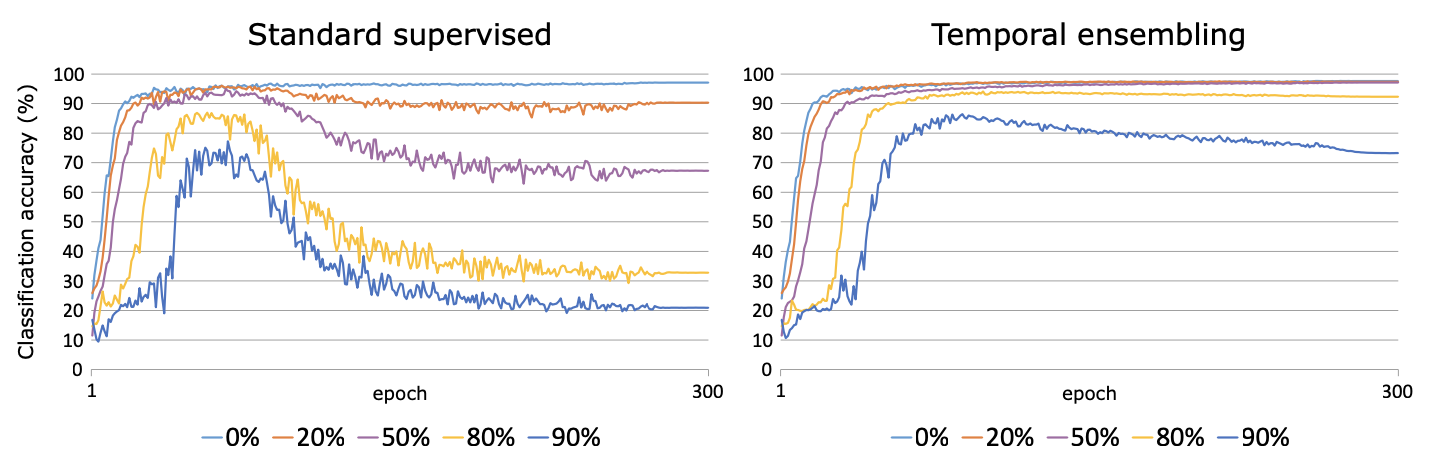
这里在头条15分类的数据集上进行了测试。分别在Fasttext和Bert上进行了测试,左是原始模型,右加入Temporal Ensemble。考虑NLP的样本层面的增强效果对比CV相对有限,这里的随机增强只用了Encoder层的Drop out,原论文是CV领域所以增强还包括crop/flip这类图像增强。
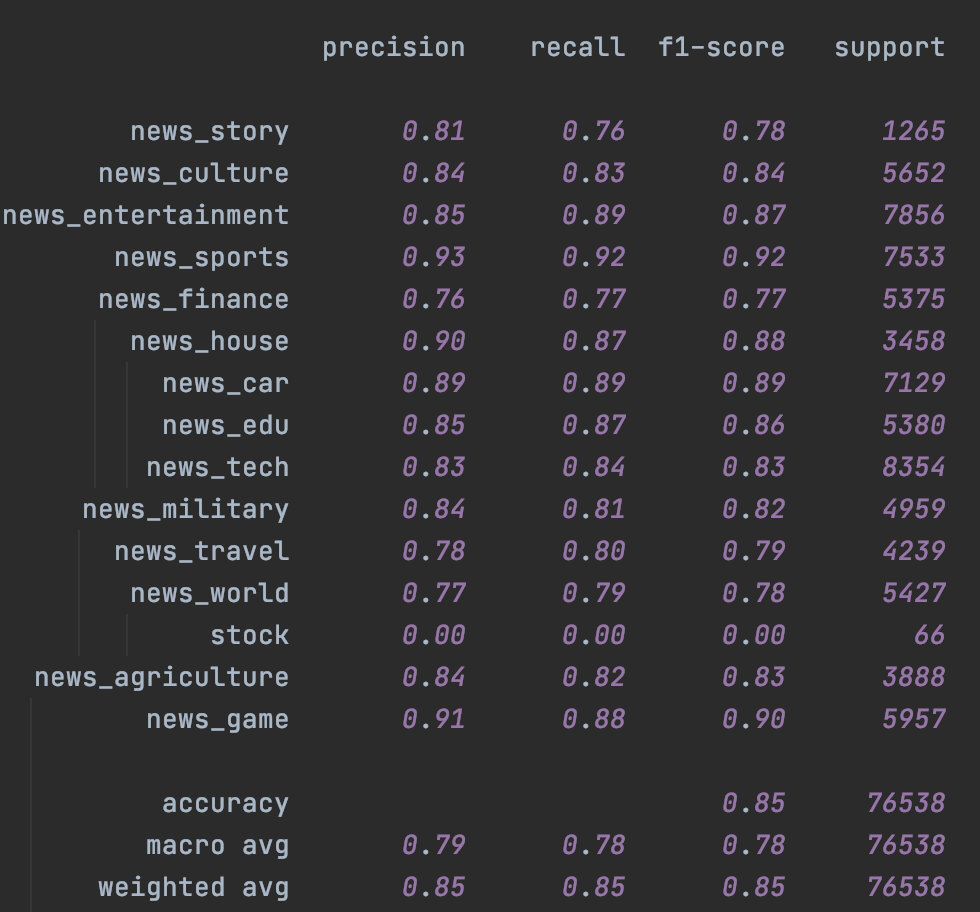
首先是Fasttext,受限于词袋模型本身的能力,即便是不加入未标注样本,只是加入Temporal一致性损失都带来了整体效果上的提升,具体参数设置详见checkpoint里面的train.log
 |
 |
|---|
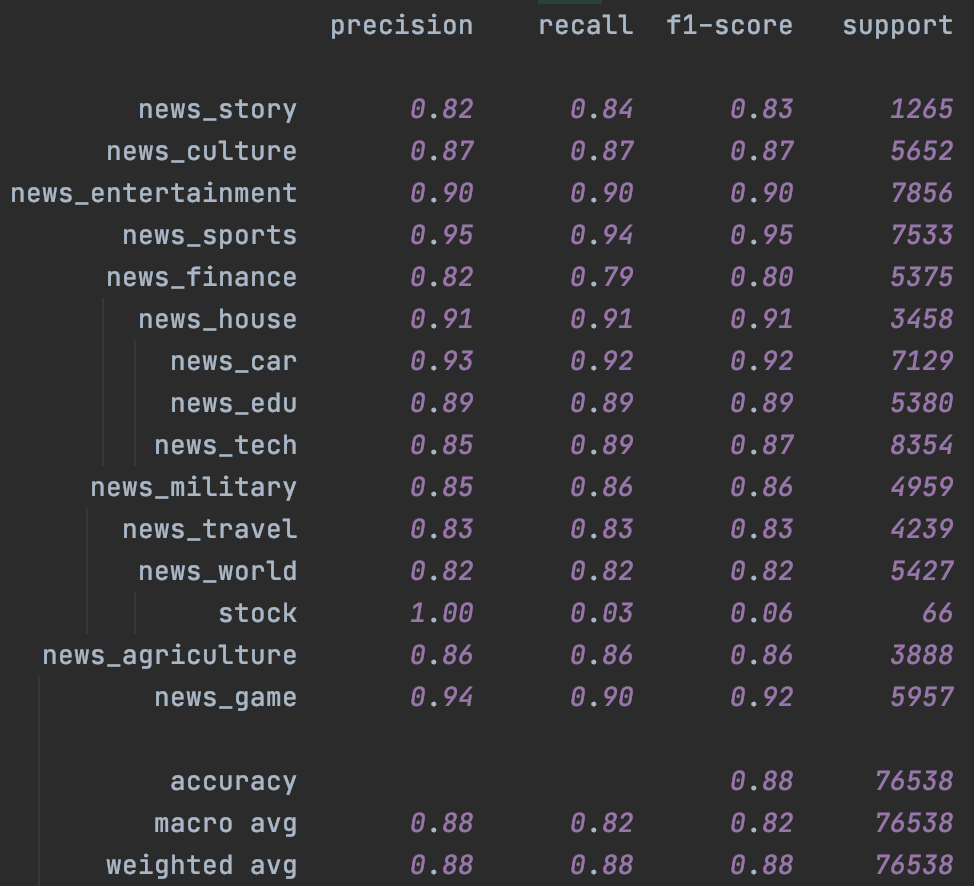
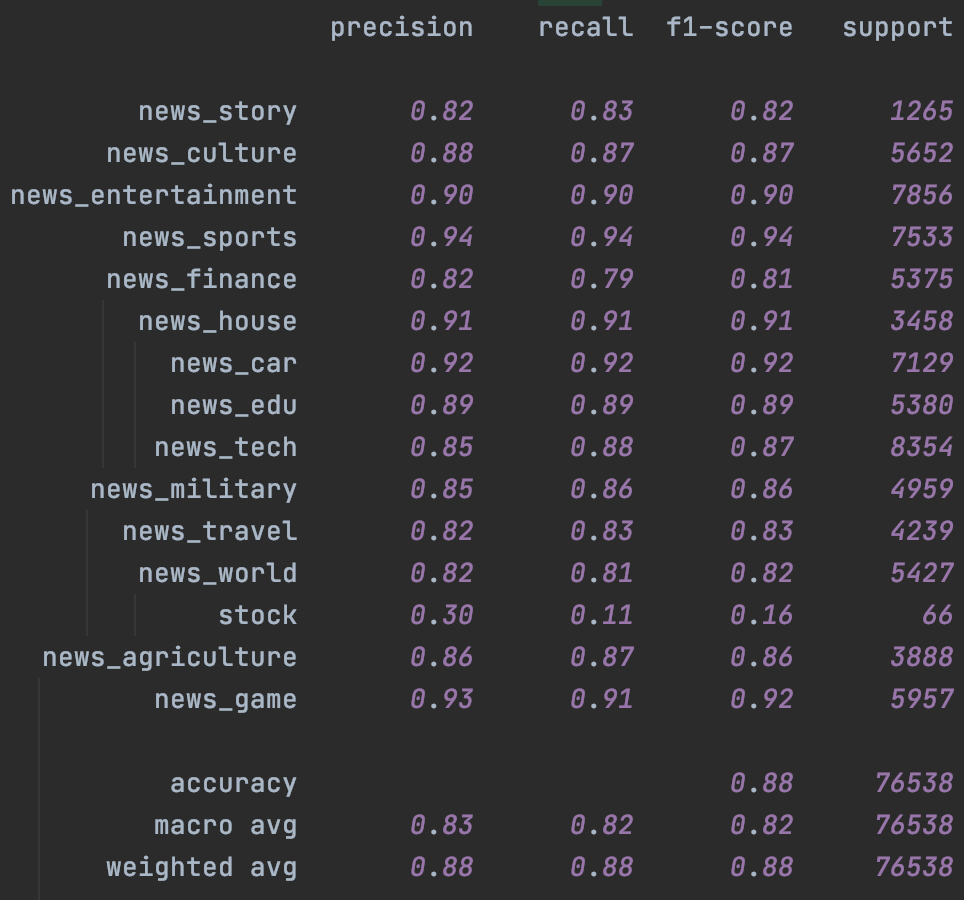
其次是Bert,这里加入了chinanews的无标注样本,不过效果比较有限,主要提升是在样本很少的stock分类上。这里一定程度和缺少有效的样本增强有关,后面结合隐藏层增强我们会再试下temporal~
 |
 |
|---|
Reference
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳