文章目录
makefile可以简单的认为是一个工程文件的编译规则,描述了整个工程的自动编译和链接的规则。
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释。
(1)显式规则
显式规则说明了,如何生成一个或多的的目标文件。这是由 Makefile 的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
(2)隐晦规则
由于我们的 make 命名有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写 Makefile,这是由 make 命令所支持的。
(3) 变量的定义
在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点像C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
(4)文件指示
其包括了三个部分,一个是在一个 Makefile 中引用另一个 Makefile,就像C语言中的 include 一样;另一个是指根据某些情况指定 Makefile 中的有效部分,就像C语言中的预编译 #if 一样;还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
(5)注释
Makefile 中只有行注释,和 UNIX 的 Shell 脚本一样,其注释是用“#”字符,这个就像 C/C++ 中的“//”一样。如果你要在你的 Makefile 中使用“#”字符,可以用反斜框进行转义,如:“#”。
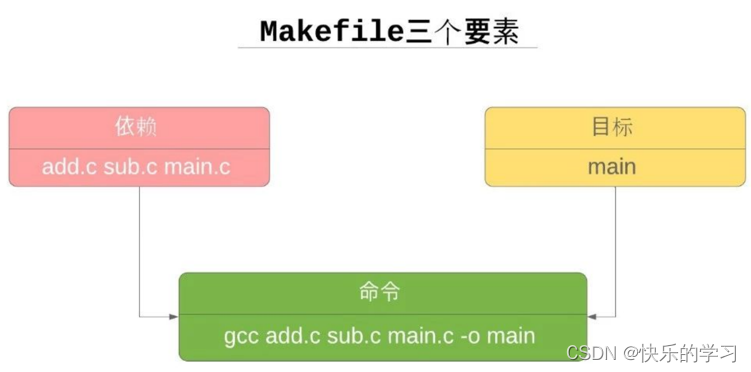
基本格式如下:
targets: prerequisites
command
targets:规则的目标,可以是 Object File(一般称它为中间文件),也可以是可执行文件,还可以是一个标签;
prerequisites:是我们的依赖文件,要生成 targets 需要的文件或者是目标。可以是多个,也可以是没有;
command:make 需要执行的命令(任意的 shell 命令)。可以有多条命令,每一条命令占一行。
具体流程可参考下图:
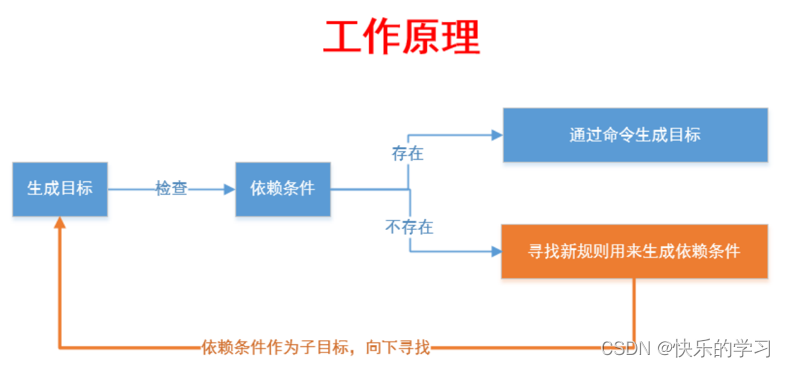
 Makefile执行的具体过程如下图:
Makefile执行的具体过程如下图:
 Makfile程序的编写首先要了解程序的编译过程,可参考下面的链接:
Makfile程序的编写首先要了解程序的编译过程,可参考下面的链接:
| 变量 | 解析 |
|---|---|
| = | 是最基本的赋值 |
| := | 是覆盖之前的值 |
| ?= | 是如果没有被赋值过就赋予等号后面的值 |
| += | 是添加等号后面的值 |
| obj-y := | 编译进内核的文件(夹)列表 |
| obj-m := | 编译成外部可加载模块的列表 |
| lib-y := 和 lib-m := | 编译成库文件 |
| always := | 总是需要被编译的模块 |
| targets := | 编译目标 |
| subdir-y := 和 subdir-m := | 表示需要递归进入的子目录 |
内核中常用的Makefile例子:
//例如: fs/ext2/Makefile
obj-$(CONFIG_EXT2_FS) += ext2.o
ext2-y := balloc.o dir.o file.o ialloc.o inode.o ioctl.o namei.o super.o symlink.o
ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o xattr_user.o xattr_trusted.o
CONFIG_EXT2_FS在/fs/ext2/Kconfig中,可以通过make menuconfig设置CONFIG_EXT2_FS=y
config EXT2_FS
tristate "Second extended fs support"
help
Ext2 is a standard Linux file system for hard disks.
在这个例子中,如果$(CONFIG_EXT2_FS_XATTR)表示’y’,则xattr.o xattr_user.o和xattr_trusted.o都将是复合对象ext2.o的一部分.
注意: 当然,当你将编译目标文件到内核时,以上语法同样有效.因此,如果CONFIG_EXT2_FS=y,Kbuild将建立一个ext2.o来输出各个部分,然后将其链接到 built-in.o中,正如您期望的那样。
| 变量 | 解析 |
|---|---|
| $0 | 当前脚本的文件名。 |
| $n(n≥1) | 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是 $1,第二个参数是 $2>。 |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| $@ | 表示目标文件。 |
| $? | 上个命令的退出状态,或函数的返回值。 |
| $$ | 当前 Shell 进程 ID。对于 Shell 脚本,就是这些脚本所在的进程 ID。 |
| $^ | 表示所有的依赖文件 |
| $< | 表示第一个依赖文件 |
# Makefile内容
.PHONY:all
all:first second third
@echo "\$$@ = $@"
@echo "\$$^ = $^"
@echo "\$$< = $<"
[root@localhost /]# make
first second third:
$@ = all
$^ = first second third
$< = first
# Makefile内容
%.o:%.c
gcc -o $@ $^
OBJ=$(wildcard *.c)
test:$(OBJ)
gcc -o $@ $^
当用通配符赋值给变量时需要用wildcard通配符函数,通过它可以得到我们所需的文件,这个函数类似我们在 Windows 或Linux命令行中的“*”
| 宏定义 | 含义 |
|---|---|
| AR | 归档维护程序的名称,默认值为 ar。 |
| ARFLAGS | 归档维护程序的选项。 |
| AS | 汇编程序的名称,默认值为 as。 |
| ASFLAGS | 汇编程序的选项。 |
| CC | C 编译器的名称,默认值为 cc。 |
| CCFLAGS | C 编译器的选项。 |
| CPP | C 预编译器的名称,默认值为 $(CC) -E。 |
| CPPFLAGS | C 预编译的选项。 |
| CXX | C++ 编译器的名称,默认值为 g++。 |
| CXXFLAGS | C++ 编译器的选项。 |
| FC | FORTRAN编译器的名称,默认值为 f77。 |
| FFLAGS | FORTRAN编译器的选项。 |
实例使用:
ccflags-y := -DDEBUG
ccflags-y := -DVERBOSE_DEBUG
opps-objs :=oops_test.o
obj-make := opps.o
KBUILD_CFLAGS +=-g
CC = gcc
CCFLAGS = -D_DEBUG -g -m486
test.o: test.c test.h
$(CC) -c $(CCFLAGS) test.c
在上面的例子中,CC和 CCFLAGS 就是 make 的变量。GNU make通常称之为变量,而其他 UNIX 的 make工具称之为宏。
当 make 看到条件语法时将⽴即对其进⾏分析,这包括 ifdef、ifeq、ifndef 和 ifneq 四种语句形式。
conditional-directive
text-if-true
else
text-if-false
endif
# Makefile内容
.PHONY: all
sharp = square
desk = square
table = circle
ifeq ($(sharp), $(desk))
result1 = "desk == sharp"
endif
ifneq "$(table)" 'square'
result2 = "table != square"
endif
all:
@echo $(result1)
@echo $(result2)
[root@localhost /]# make
desk == sharp
table != square
(1)VPATH变量
Makefile文件中的特殊变量“VPATH”就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当当前目录找不到的情况下,到所指定的目录中去找寻文件了。
VPATH = src:../headers
vapth使用方法中的需要包含“%”字符。“%”的意思是匹配零或若干字符,例如,“%.h”表示所有以“.h”结尾的文件。指定了要搜索的文件集,而< directories>则指定了的文件集的搜索的目录。例如:
vpath %.h ../headers
该语句表示,要求make在“…/headers”目录下搜索所有以“.h”结尾的文件。(如果某文件在当前目录没有找到的话)
(2).PHONY变量
因为,我们并不生成“clean”这个文件。“伪目标”并不是一个文件,只是一个标签,由于“伪目标”不是文件,所以make无法生成它的依赖关系和决定它是否要执行。我们只有通过显示地指明这个“目标”才能让其生效。当然,“伪目标”的取名不能和文件名重名,不然其就失去了“伪目标”的意义了。
当然,为了避免和文件重名的这种情况,我们可以使用一个特殊的标记“.PHONY”来显示地指明一个目标是“伪目标”,向make说明,不管是否有这个文件,这个目标就是“伪目标”。
.PHONY: clean
clean:
rm -rf *.o
# “.PHONY”表示,clean是个伪目标文件,当执行make clean时,直接执行clean下面的命令rm -rf *.o
(3)include变量
"include"指示符告诉 make 暂停读取当前的 Makefile,而转去读取"include"指定的一个或者多个文件,完成以后再继续当前 Makefile 的读取。
为什么要include其他文件呢?
对于一些通用的变量定义、通用规则,写在一个文件中,任意目录结构中的makefile想要使用这些通用的变量或规则时,include指定的文件就好了,而不用在每个makefile中又重写一遍。
对于源文件自动生成依赖文件(makefile之目录搜索&自动依赖)时,将这些个依赖关系保存成文件,在需要使用时include进来,这样少了人为的干预,同时也减少的错误的发生
我们就不希望mkdir出错而终止规则的运行。
为了做到这一点,忽略命令的出错,我们可以在Makefile的命令行前加一个减号“-”(在Tab键之后),标记为不管命令出不出错都认为是成功的。
“-include” 来代替 “include” 来忽略文件不存在或者是无法创建的错误提示,使用格式如下:-include
| 名称 | 功能 |
|---|---|
| .PHONY: | 这个目标的所有依赖被作为伪目标。伪目标是这样一个目标:当使用make命令行指定此目标时,这个目标所在的规则定义的命令、无论目标文件是否存在都会被无条件执行。 |
| .SUFFIXES: | 这个目标的所有依赖指出了一系列在后缀规则中需要检查的后缀名 |
| .DEFAULT: | Makefile中,这个特殊目标所在规则定义的命令,被用在重建那些没有具体规则的目标,就是说一个文件作为某个规则的依赖,却不是另外一个规则的目标时,make 程序无法找到重建此文件的规则,这种情况就执行 “.DEFAULT” 所指定的命令。 |
| .PRECIOUS: | 这个特殊目标所在的依赖文件在make的过程中会被特殊处理:当命令执行的过程中断时,make不会删除它们。而且如果目标的依赖文件是中间过程文件,同样这些文件不会被删除。 |
| .INTERMEDIATE: | 这个特殊目标的依赖文件在 make 执行时被作为中间文件对待。没有任何依赖文件的这个目标没有意义。 |
| .SECONDARY: | 这个特殊目标的依赖文件被作为中过程的文件对待。但是这些文件不会被删除。这个目标没有任何依赖文件的含义是:将所有的文件视为中间文件。 |
# Makefile内容
.PHONY:all clean
MKDIR=mkdir
RM=rm
RMFLAGS=-fr
CC=gcc
DIR_OBJS=objs
DIR_EXE=exes
DIRS=$(DIR_OBJS) $(DIR_EXE)
EXE=test
EXE:=$(addprefix $(DIR_EXE)/, $(EXE))
SRCS=$(wildcard *.c)
OBJS=$(SRCS:.c=.o)
OBJS:=$(addprefix $(DIR_OBJS)/, $(OBJS))
all:$(DIRS) $(EXE)
$(DIRS):
$(MKDIR) $@
$(EXE):$(OBJS)
$(CC) -o $@ $^
$(DIR_OBJS)/%.o:%.c
$(CC) -o $@ -c $^
clean:
$(RM) $(RMFLAGS) $(DIRS)
//直接添加方式
$(warning "this is test========================")
$(info $(KBUILD_CFLAGS))
$(error $(KBUILD_CFLAGS))
//使用echo命令打印
test:
@echo $(KBUILD_CFLAGS)
执行make test 即可打印echo内容
具体链接可参考:C语言、Makefile和shell中添加打印调试信息总结
objs := head.o init.o nand.o main.o
nand.bin : $(objs) //冒号前面的是表示目标文件, 冒号后面的是依赖文件,这里是将所有*.o文件编译出nand.bin可执行文件
arm-linux-ld -Tnand.lds -o nand_elf $^ //将*.o文件生成nand_elf链接文件
//-T:指向链接脚本, $^:指向所有依赖文件,
arm-linux-objcopy -O binary -S nand_elf $@ //将nand_elf链接文件生成nand.bin文件
//$@:指向目标文件:nand.bin
//-O :选项,其中binary就是表示生成的文件为.bin文件
arm-linux-objdump -D -m arm nand_elf > nand.dis //将nand.bin文件反汇编出nand.dis文件
//-D :反汇编nand.bin里面所有的段, -m arm:指定反汇编文件的架构体系,这里arm架构
%.o:%.c
arm-linux-gcc -Wall -c -O2 -o $@ $<
%.o:%.S
arm-linux-gcc -Wall -c -O2 -o $@ $<
clean:
rm -f nand.dis nand.bin nand_elf *.o
其中 objs 是代表的一个变量,表示obj文件,也可以是objects, OBJECTS, objs, OBJS, obj, 或是 OBJ,后面就可以使用$(objs)来使用这个变量了。
$@ 目标文件
$^ 所有的依赖文件
$< 第一个依赖文件
例如:
arm-linux-ld -Tnand.lds -o nand_elf $^
<<—— 等价于 ——>>
arm-linux-ld -o nand_elf head.o init.o nand.o main.o
%.o:%.c 表示所有的.o文件,依赖于对应的.c文件
%.o:%.S 表示所有的.o文件,依赖于对应的.S文件
obj-y = main.o
main-objs := a.o b.o c.o
//将a.c b.c c.c三个文件编译后链接生成main.o
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json