作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据分析 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
文章目录
数据准备

1.导入所需模块
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
import os
for dirname, _, filenames in os.walk('/home/mw/input/'):
for filename in filenames:
print(os.path.join(dirname, filename))

2.导入数据
df=pd.read_csv('/home/mw/input/1119442/hotel_bookings.csv')
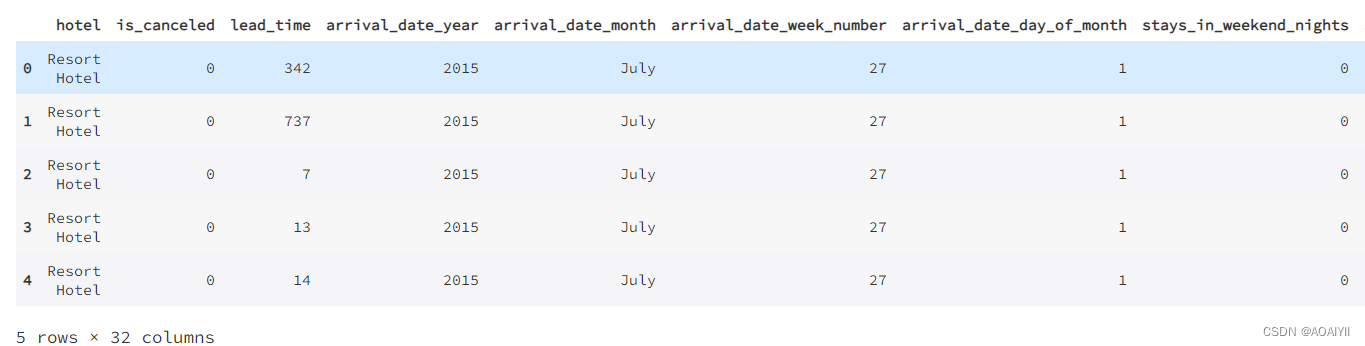
df.head()
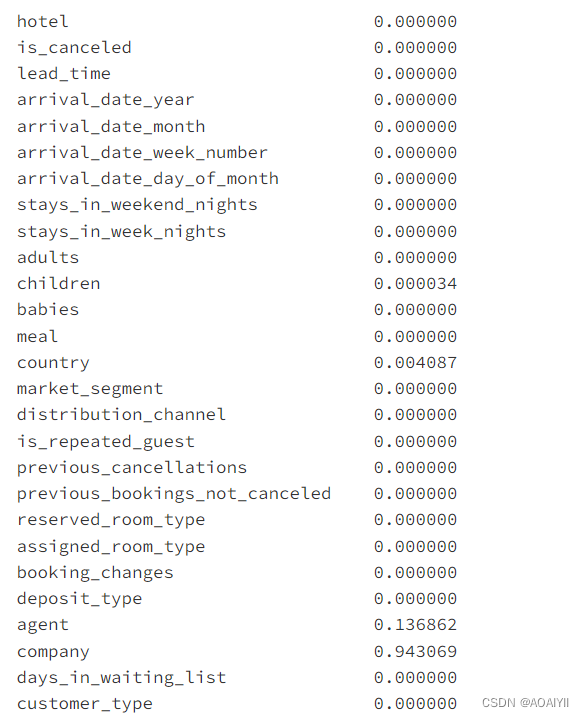
3.查看每列空值占比
df.isnull().mean()
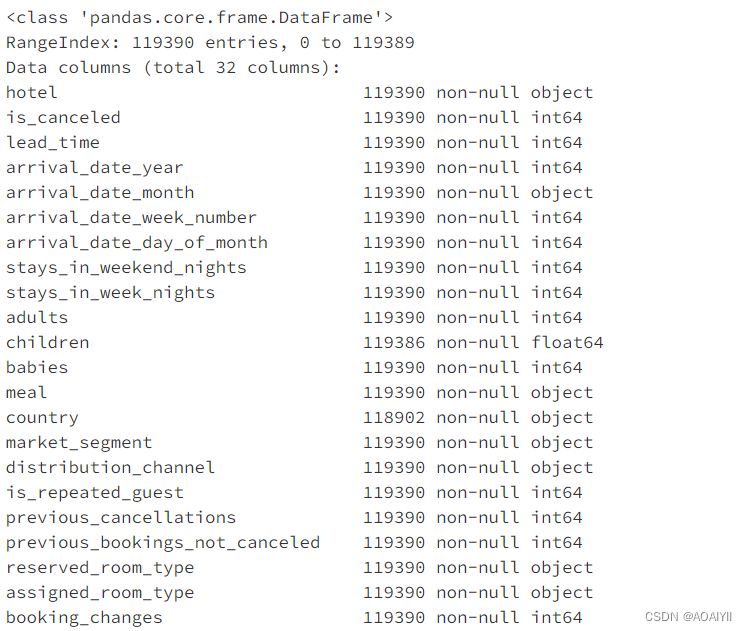
4.查看数据基本信息
df.info()
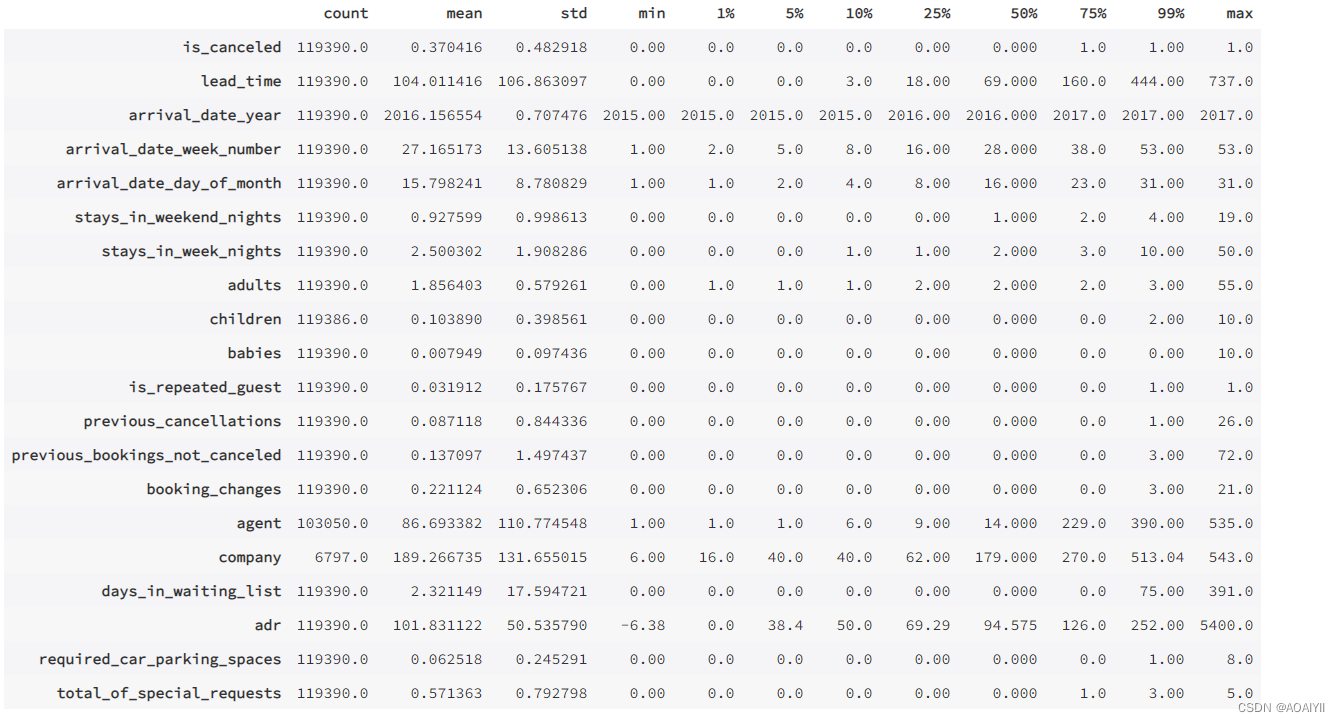
5.使用describe()函数,计算数据集中每列的总数、均值、标准差、最小值、25%、50%、75%分位数以及最大值并转置。
df.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.99]).T
plt.figure(figsize=(15,8))
sns.countplot(x='hotel'
,data=df
,hue='is_canceled'
,palette=sns.color_palette('Set2',2)
)
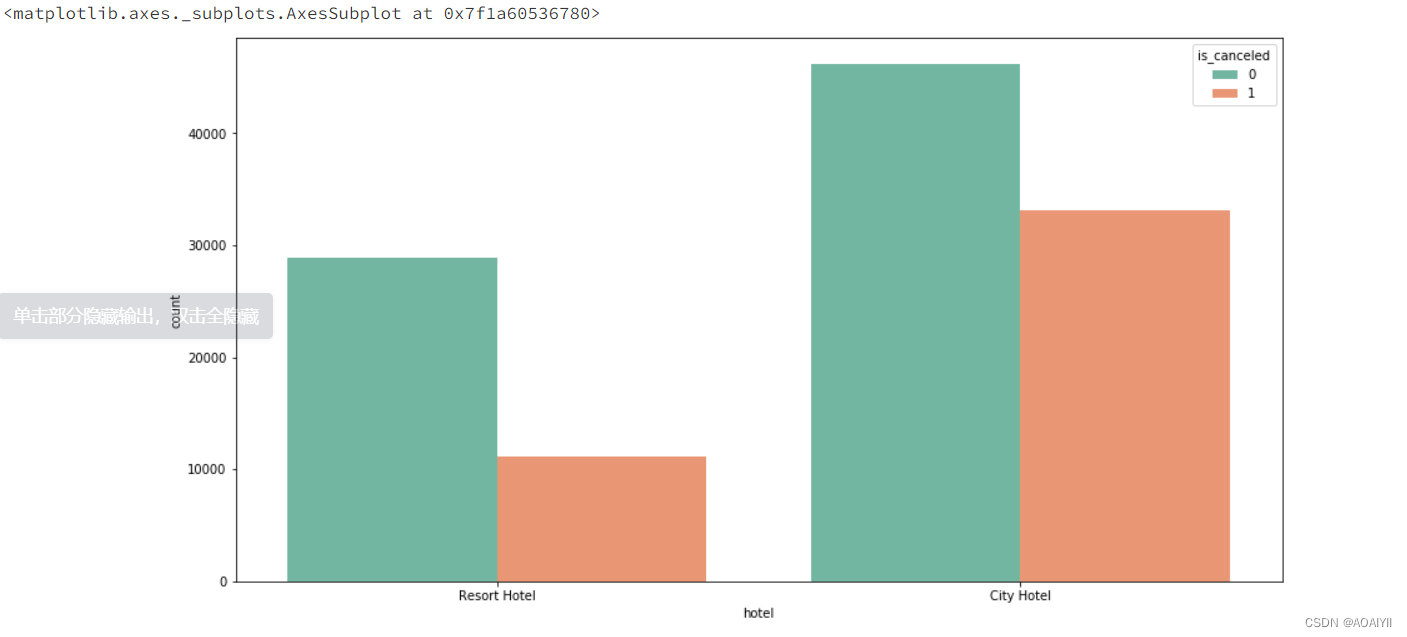
hotel_cancel=(df.loc[df['is_canceled']==1]['hotel'].value_counts()/df['hotel'].value_counts()).sort_values(ascending=False)
print('酒店取消率'.center(20),hotel_cancel,sep='\n')

City Hotel的预定量与取消量都高于Resort Hotel,但Resort Hotel取消率为27.8%,而City Hotel的取消率达到了41.7%
city_hotel=df[(df['hotel']=='City Hotel') & (df['is_canceled']==0)]
resort_hotel=df[(df['hotel']=='Resort Hotel') & (df['is_canceled']==0)]
for i in [city_hotel,resort_hotel]:
i.index=range(i.shape[0])
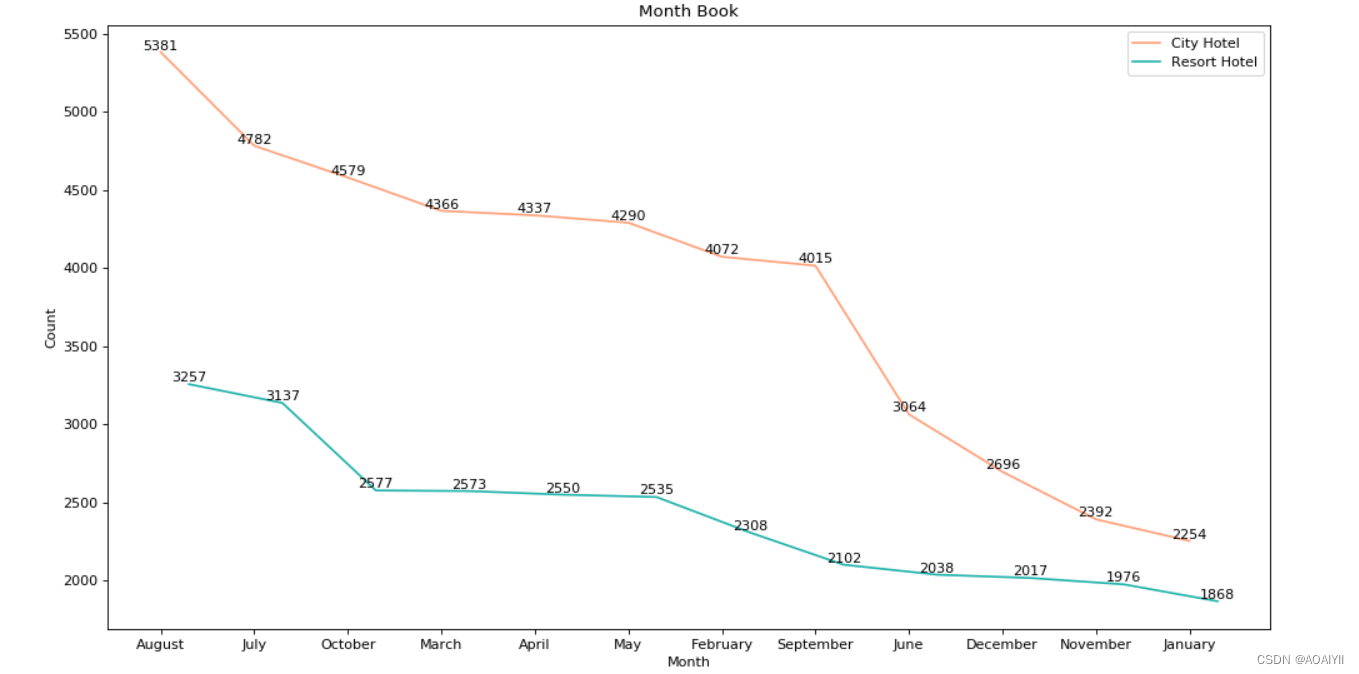
city_month=city_hotel['arrival_date_month'].value_counts()
resort_month=resort_hotel['arrival_date_month'].value_counts()
name=resort_month.index
x=list(range(len(city_month.index)))
y=city_month.values
x1=[i+0.3 for i in x]
y1=resort_month.values
width=0.3
plt.figure(figsize=(15,8),dpi=80)
plt.plot(x,y,label='City Hotel',color='lightsalmon')
plt.plot(x1,y1,label='Resort Hotel',color='lightseagreen')
plt.xticks(x,name)
plt.legend()
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Month Book')
for x,y in zip(x,y):
plt.text(x,y+0.1,'%d' % y,ha = 'center',va = 'bottom')
for x,y in zip(x1,y1):
plt.text(x,y+0.1,'%d' % y,ha = 'center',va = 'bottom')
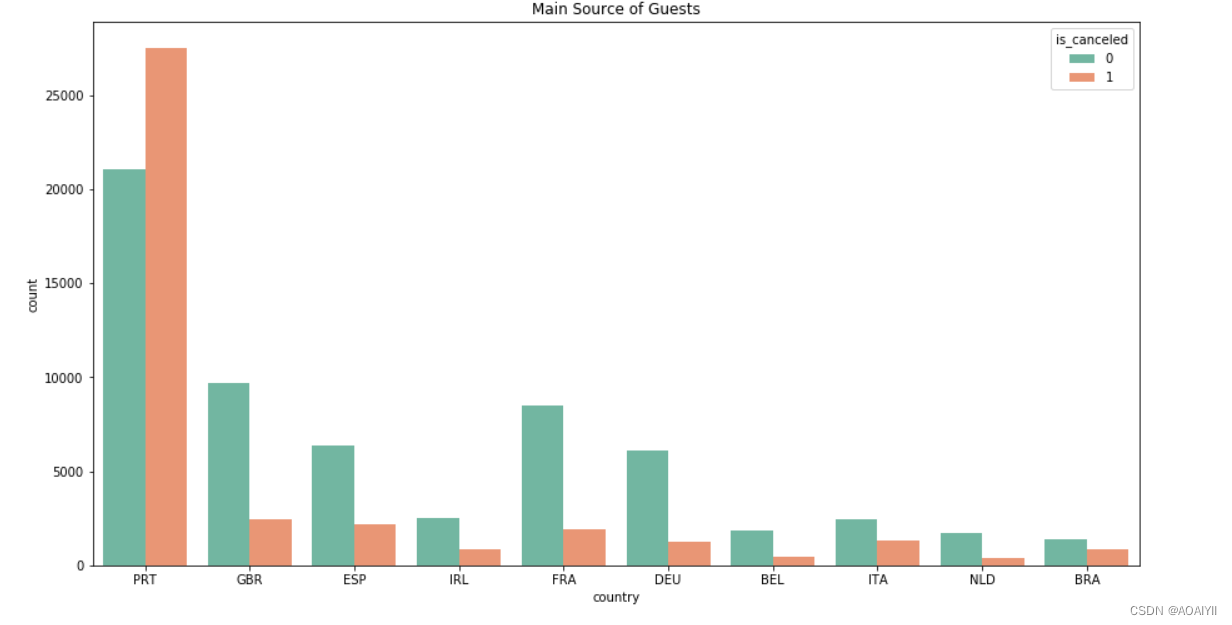
country_book=df['country'].value_counts()[:10]
country_cancel=df[(df.country.isin (country_book.index)) & (df.is_canceled==1)]['country'].value_counts()
plt.figure(figsize=(15,8))
sns.countplot(x='country'
,data=df[df.country.isin (country_book.index)]
,hue='is_canceled'
,palette=sns.color_palette('Set2',2)
)
plt.title('Main Source of Guests')
country_cancel_rate=(country_cancel/country_book).sort_values(ascending=False)
print('各国客户取消率'.center(10),country_cancel_rate,sep='\n')
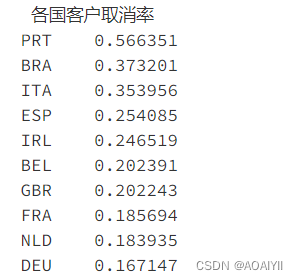
Resort hotel和City hotel的旺季均为夏季7、8月份,且客源主要为欧洲国家,符合欧洲游客偏爱夏季出游的特点,需要重点关注来自葡萄牙(PRT)和英国(BRT)等取消率高的主要客源
city_customer=city_hotel.customer_type.value_counts()
resort_customer=resort_hotel.customer_type.value_counts()
plt.figure(figsize=(21,12),dpi=80)
plt.subplot(1,2,1)
plt.pie(city_customer,labels=city_customer.index,autopct='%.2f%%')
plt.legend(loc=1)
plt.title('City Hotel Customer Type')
plt.subplot(1,2,2)
plt.pie(resort_customer,labels=resort_customer.index,autopct='%.2f%%')
plt.title('Resort Hotel Customer Type')
plt.legend()
plt.show()
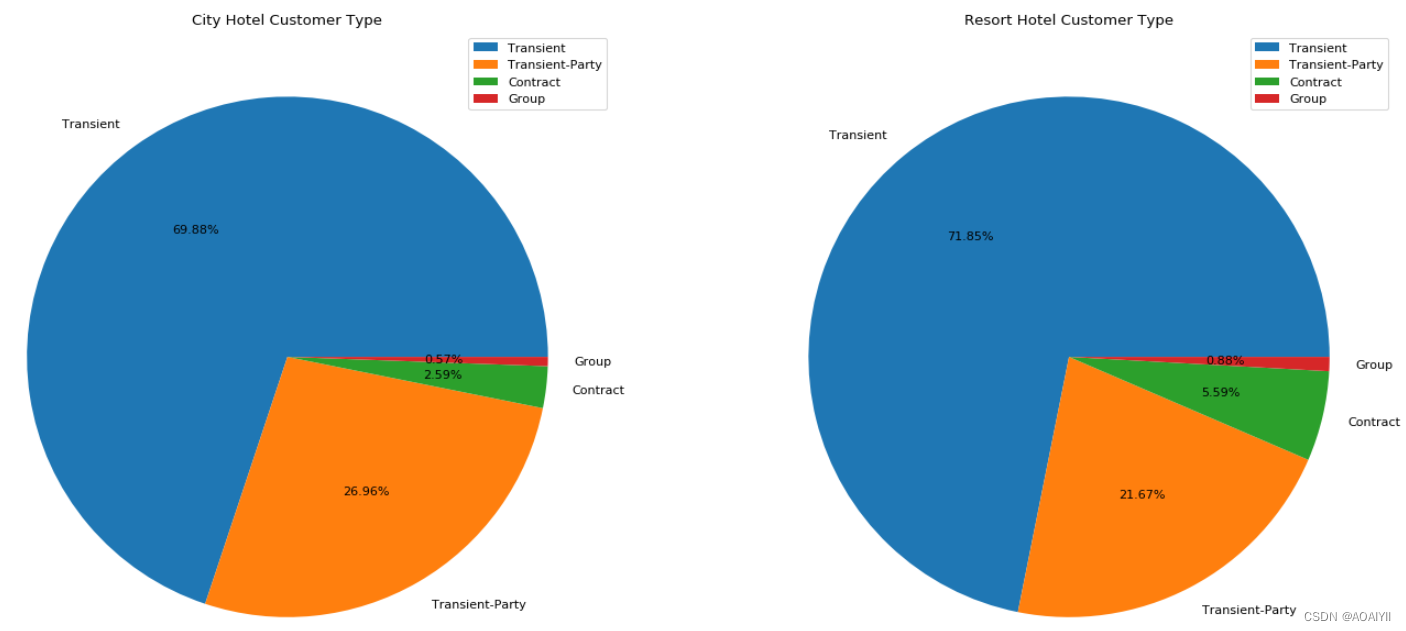
酒店的主要客户类型都是散客(Transient),占比均为70%左右
city_segment=city_hotel.market_segment.value_counts()
resort_segment=resort_hotel.market_segment.value_counts()
plt.figure(figsize=(21,12),dpi=80)
plt.subplot(1,2,1)
plt.pie(city_segment,labels=city_segment.index,autopct='%.2f%%')
plt.legend()
plt.title('City Hotel Market Segment')
plt.subplot(1,2,2)
plt.pie(resort_segment,labels=resort_segment.index,autopct='%.2f%%')
plt.title('Resort Hotel Market Segment')
plt.legend()
plt.show()
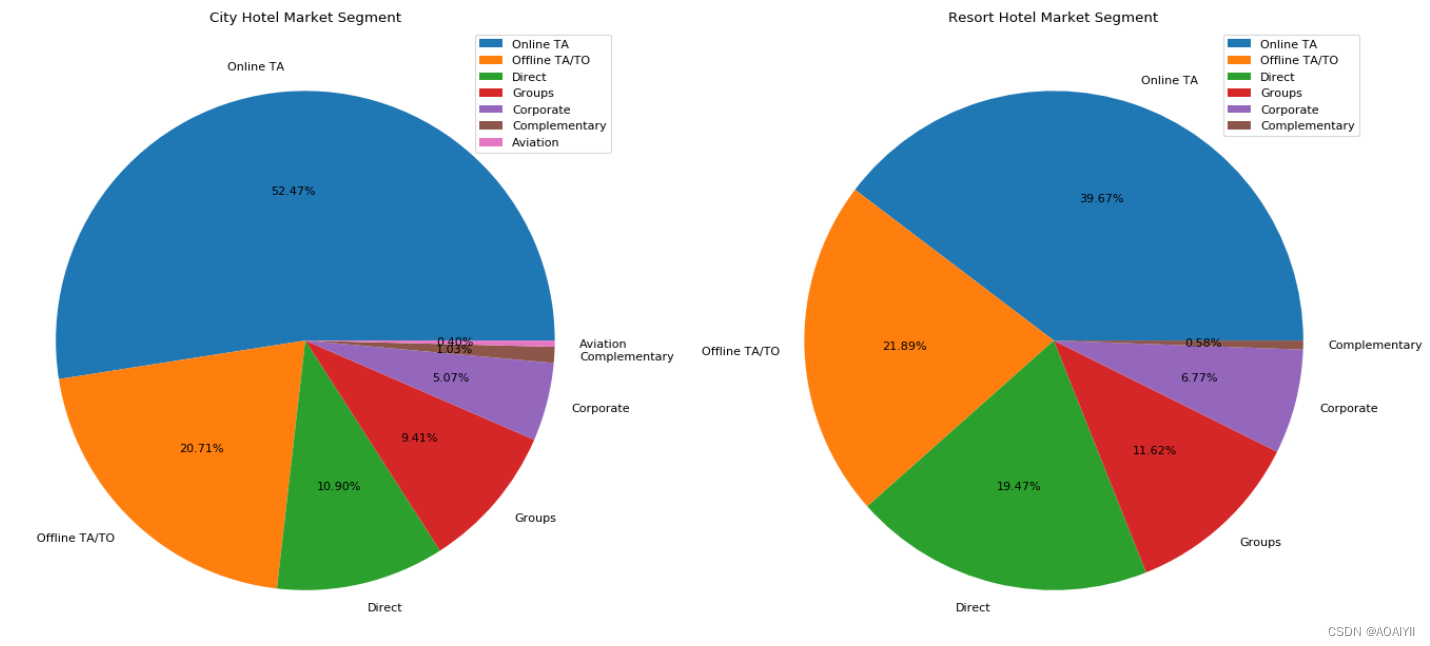
两间酒店的客源主要来自线上旅游机构,其在City Hotel的占比甚至超过5成;线下旅游机构的比重次之,均为20%左右
plt.figure(figsize=(15,8))
sns.boxplot(x='customer_type'
,y='adr'
,hue='hotel'
,data=df[df.is_canceled==0]
,palette=sns.color_palette('Set2',2)
)
plt.title('Average Daily Rate of Different Customer Type')
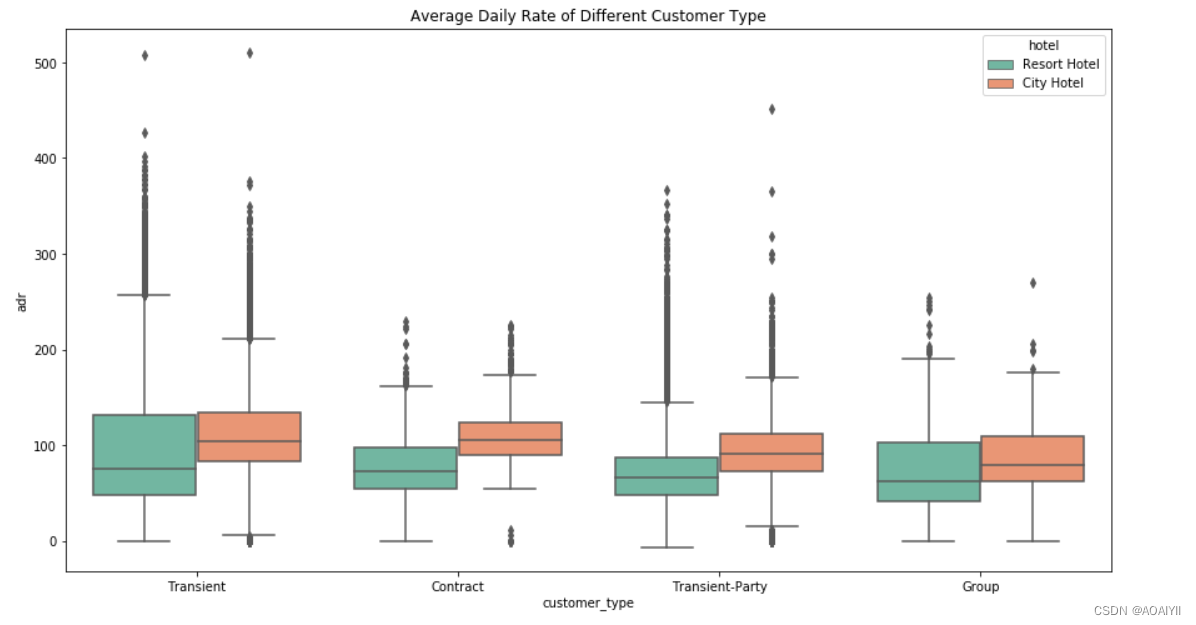
City Hotel各类客户的日均开销均高于Resort Hotel;在四种类型的客户中,散客(Transient)的消费最高,团体客(Group)最低
plt.figure(figsize=(15,8))
sns.countplot(x='is_repeated_guest'
,data=df
,hue='is_canceled'
,palette=sns.color_palette('Set2',2)
)
plt.title('New/Repeated Guest Amount')
plt.xticks(range(2),['no','yes'])
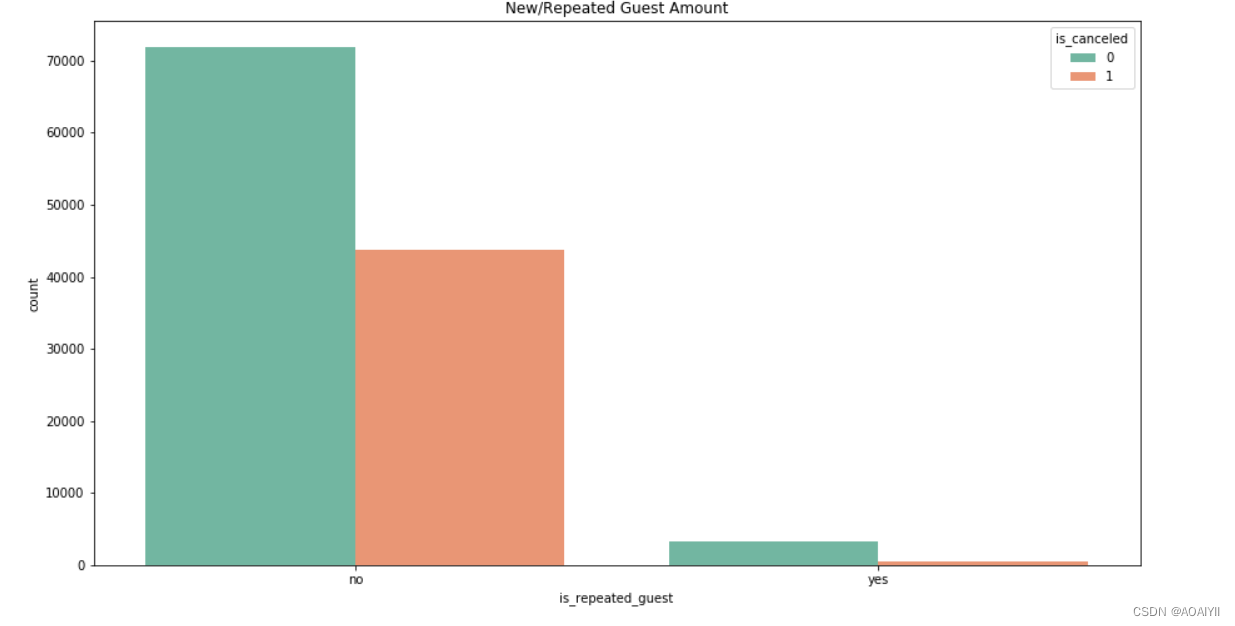
guest_cancel=(df.loc[df['is_canceled']==1]['is_repeated_guest'].value_counts()/df['is_repeated_guest'].value_counts()).sort_values(ascending=False)
guest_cancel.index=['New Guest', 'Repeated Guest']
print('新老客取消率'.center(15),guest_cancel,sep='\n')

老客的取消率为14.4%,而新客的取消率则达到了37.8%,高出老客24个百分点
print('三种押金方式预定量'.center(15),df['deposit_type'].value_counts(),sep='\n')

deposit_cancel=(df.loc[df['is_canceled']==1]['deposit_type'].value_counts()/df['deposit_type'].value_counts()).sort_values(ascending=False)
plt.figure(figsize=(8,5))
x=range(len(deposit_cancel.index))
y=deposit_cancel.values
plt.bar(x,y,label='Cancel_Rate',color=['orangered','lightsalmon','lightseagreen'],width=0.4)
plt.xticks(x,deposit_cancel.index)
plt.legend()
plt.title('Cancel Rate of Deposite Type')
for x,y in zip(x,y):
plt.text(x,y,'%.2f' % y,ha = 'center',va = 'bottom')
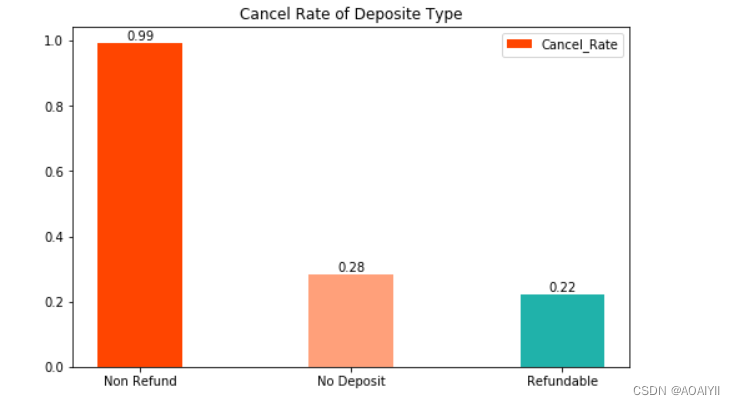
无需押金(‘No Deposit’)是预定量最高的方式,且取消率较低,而不退押金(Non Refund)这一类型的取消预订率高达99%,可以减少这一类型的押金方式以减少客户取消率
plt.figure(figsize=(15,8))
sns.countplot(x='assigned_room_type'
,data=df
,hue='is_canceled'
,palette=sns.color_palette('Set2',2)
)
plt.title('Book & Cancel Amount of Room Type')
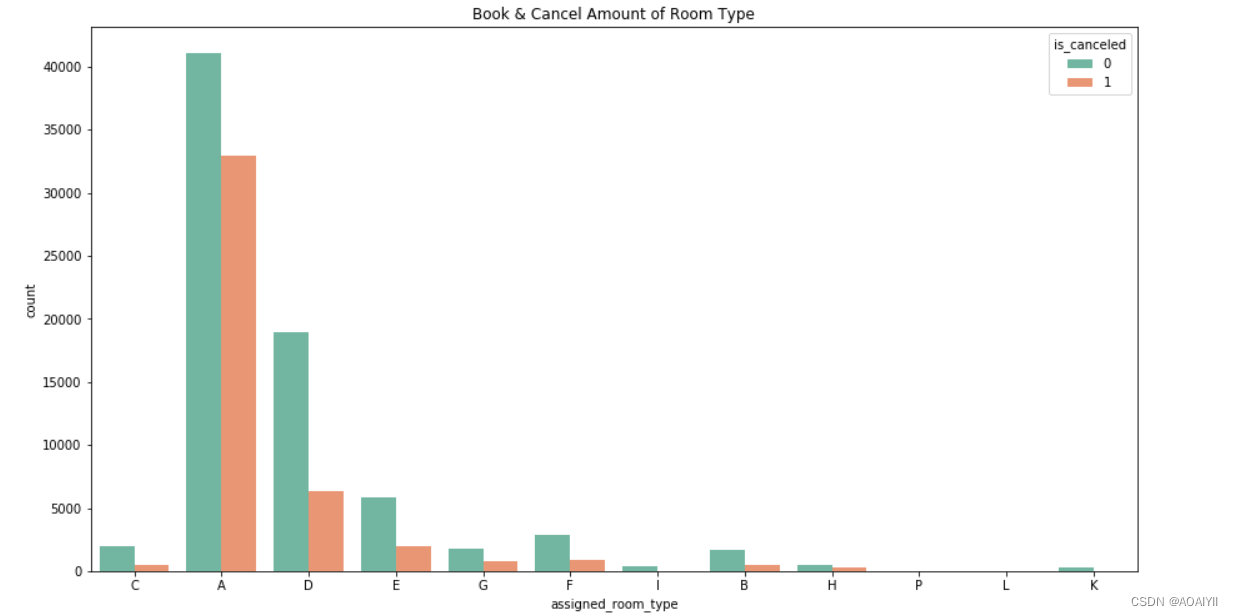
room_cancel=df.loc[df['is_canceled']==1]['assigned_room_type'].value_counts()[:7]/df['assigned_room_type'].value_counts()[:7]
print('不同房型取消率'.center(5),room_cancel.sort_values(ascending=False),sep='\n')
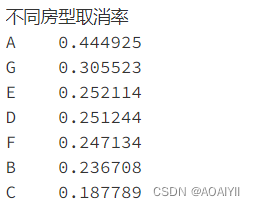
在预定量前7的房型中,A、G房型的取消率均高于其他房型,A房型的取消率更是高达44.5%
建模的目的是为了预测旅客是否会取消酒店的预订,后续需要将’is_canceled’设为标签y,其余为特征x。日期特征’is_cance’reservation_status_date’不会直接影响标签,所以删除
df1=df.drop(labels=['reservation_status_date'],axis=1)
cate=df1.columns[df1.dtypes == "object"].tolist()
#用数字表现的分类型变量
num_cate=['agent','company','is_repeated_guest']
cate=cate+num_cate
results={}
for i in ['agent','company']:
result=np.sort(df1[i].unique())
results[i]=result
results

agent和company列空值占比较多且无0值,所以用0填补
df1[['agent','company']]=df1[['agent','company']].fillna(0,axis=0)
df1.loc[:,cate].isnull().mean()
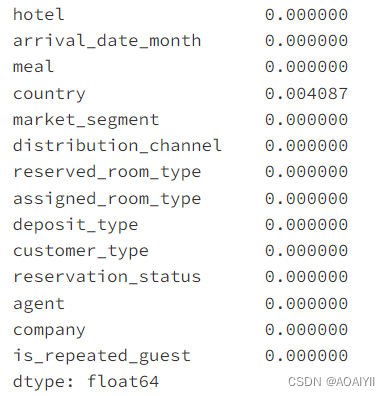
创造新变量in_company和in_agent对旅客分类,company和agent为0的设为NO,非0的为YES
df1.loc[df1['company'] == 0,'in_company']='NO'
df1.loc[df1['company'] != 0,'in_company']='YES'
df1.loc[df1['agent'] == 0,'in_agent']='NO'
df1.loc[df1['agent'] != 0,'in_agent']='YES'
创造新特征same_assignment,若预订的房间类型和分配的类型一致则为yes,反之为no
df1.loc[df1['reserved_room_type'] == df1['assigned_room_type'],'same_assignment']='Yes'
df1.loc[df1['reserved_room_type'] != df1['assigned_room_type'],'same_assignment']='No'
删除’reserved_room_type’,‘assigned_room_type’,‘agent’,'company’四个特征
df1=df1.drop(labels=['reserved_room_type','assigned_room_type','agent','company'],axis=1)
重新设置’is_repeated_guest’,常客标为YES,非常客为NO
df1['is_repeated_guest'][df1['is_repeated_guest']==0]='NO'
df1['is_repeated_guest'][df1['is_repeated_guest']==1]='YES'
df1['country']=df1['country'].fillna(df1['country'].mode()[0])
for i in ['in_company','in_agent','same_assignment']:
cate.append(i)
for i in ['reserved_room_type','assigned_room_type','agent','company']:
cate.remove(i)
cate

对分类型特征进行编码
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
oe = oe.fit(df1.loc[:,cate])
df1.loc[:,cate] = oe.transform(df1.loc[:,cate])
筛选出连续型变量,需要先删除’is_canceled’这一标签
col=df1.columns.tolist()
col.remove('is_canceled')
for i in cate:
col.remove(i)
col
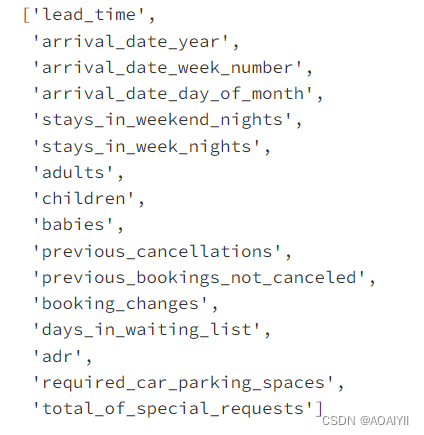
统计空值
df1[col].isnull().sum()
使用众数填补xtrain children列的空值
df1['children']=df1['children'].fillna(df1['children'].mode()[0])
连续型变量进行无量纲化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(df1.loc[:,col])
df1.loc[:,col] = ss.transform(df1.loc[:,col])
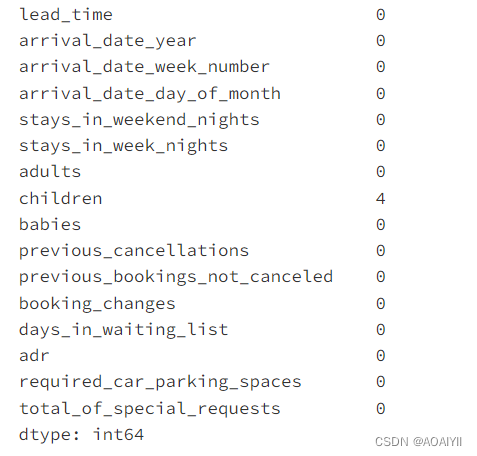
cor=df1.corr()
cor=abs(cor['is_canceled']).sort_values()
cor
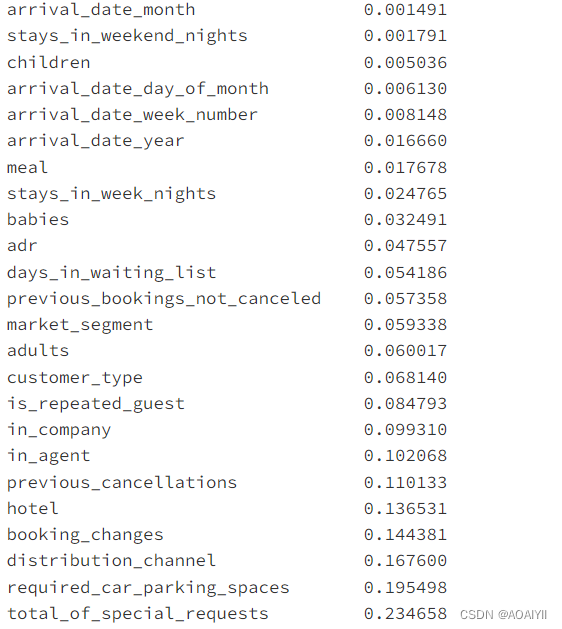
plt.figure(figsize=(8,15))
x=range(len(cor.index))
name=cor.index
y=abs(cor.values)
plt.barh(x,y,color='salmon')
plt.yticks(x,name)
for x,y in zip(x,y):
plt.text(y,x-0.1,'%.2f' % y,ha = 'center',va = 'bottom')
plt.xlabel('Corrleation')
plt.ylabel('Varriance')
plt.show()
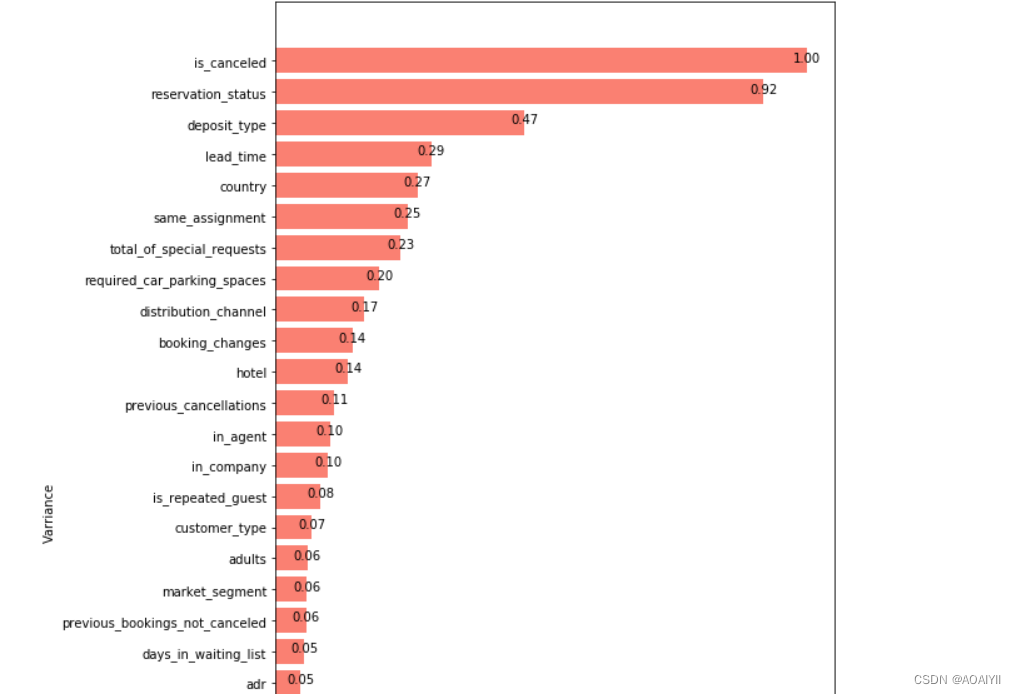
预订状态(‘reservation_status’)与是否取消预订的相关性最高,达到了0.92,但考虑到后续可能会导致模型过拟合,所以删除;押金类型(‘deposit_type’)则达到了0.47,创造的特征预订和分配房型是否一致(‘same_assignment’)也有0.25的相关性
划分特征x和标签y
df2=df1.drop('reservation_status',axis=1)
x=df2.loc[:,df2.columns != 'is_canceled' ]
y=df2.loc[:,'is_canceled']
from sklearn.model_selection import train_test_split as tts
xtrain,xtest,ytrain,ytest=tts(x,y,test_size=0.3,random_state=90)
for i in [xtrain,xtest,ytrain,ytest]:
i.index=range(i.shape[0])
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score as cvs,KFold
from sklearn.metrics import accuracy_score
rfc=RandomForestClassifier(n_estimators=100,random_state=90)
cv=KFold(n_splits=10, shuffle = True, random_state=90)
rfc_score=cvs(rfc,xtrain,ytrain,cv=cv).mean()
rfc.fit(xtrain,ytrain)
y_score=rfc.predict_proba(xtest)[:,1]
rfc_pred=rfc.predict(xtest)
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score as AUC
FPR, recall, thresholds = roc_curve(ytest,y_score, pos_label=1)
rfc_auc = AUC(ytest,y_score)
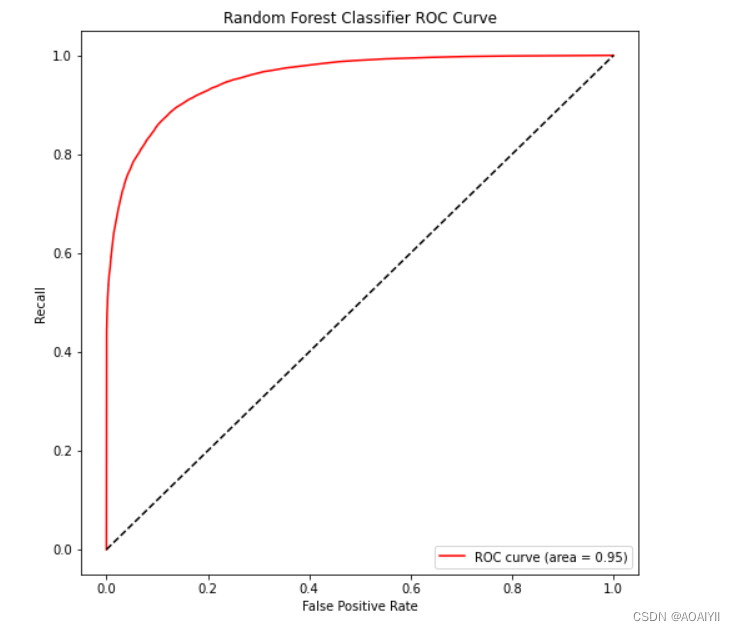
绘制ROC曲线
plt.figure(figsize=(8,8))
plt.plot(FPR, recall, color='red',label='ROC curve (area = %0.2f)' % rfc_auc)
plt.plot([0, 1], [0, 1], color='black', linestyle='--')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('Recall')
plt.title('Random Forest Classifier ROC Curve')
plt.legend(loc="lower right")
plt.show()
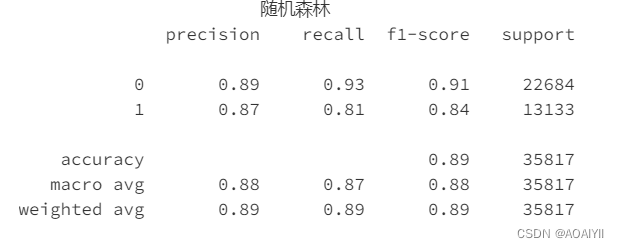
查看模型classification_report
from sklearn.metrics import classification_report as CR
print('随机森林'.center(50), CR(ytest,rfc_pred),sep='\n')
score={'Model_score':[rfc_score],'Auc_area':[rfc_auc]}
score_com=pd.DataFrame(data=score,index=['RandomForest'])
score_com.sort_values(by=['Model_score'],ascending=False)
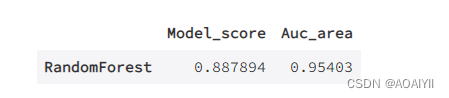
随机森林的准确度达到了88.8%,AUC面积也有0.95,可以通过调参来继续提升模型的效果
1.City Hotel的预定量和取消率都远高于Resort Hotel,该酒店应对客户展开调研,深入了解导致客户最终放弃预订的因素从而降低客户的取消率
2.酒店应利用好每年7、 8月的旅游旺季,可以在保证服务质量的同时适当提高价格获取更多利润,在淡季(冬季)的时候进行优惠活动,如圣诞大促和新年活动,减少酒店空房率
3.酒店需分析来自葡萄牙、英国等主要客源国的客户画像,了解这些客户的属性标签、偏好与消费特征,推出专属服务从而降低客户的取消率
4.由于散客是酒店的主要客户群且消费水平较高,酒店可以通过线上和线下旅游机构的途径,加大对自由行的宣传营销,从而吸引更多该类型的游客
5.新客的取消率比老客高24%,因此,酒店应重点关注新客的预订与入住体验,为新客提供更多指引与优惠,如为首次入住的客户提供折扣,调研新客对入住满意与不满意的反馈以提升日后服务,同时维护好老客
6.不退押金(Non Refund)这一类型的取消预订率高达99%,酒店应优化这种方式,如返还50%的押金,或者可以直接取消这一种方式,从而提高入住率
7.A、G房型的取消率远高于其他房型,酒店方应在客户在预订的时候跟客户仔细确认房间信息,让客户对房间情况有充分了解,避免认知错误,同时可以对房间设施进行优化并提高服务水平
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf