摘要:Apache ShardingSphere 是一款分布式的数据库生态系统,它包含两大产品:ShardingSphere-Proxy和ShardingSphere-JDBC。
本文分享自华为云社区《看完这一篇,ShardingSphere-jdbc 实战再也不怕了》,作者:勇哥java实战分享 。
Apache ShardingSphere 是一款分布式的数据库生态系统,它包含两大产品:
ShardingSphere-Proxy 被定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
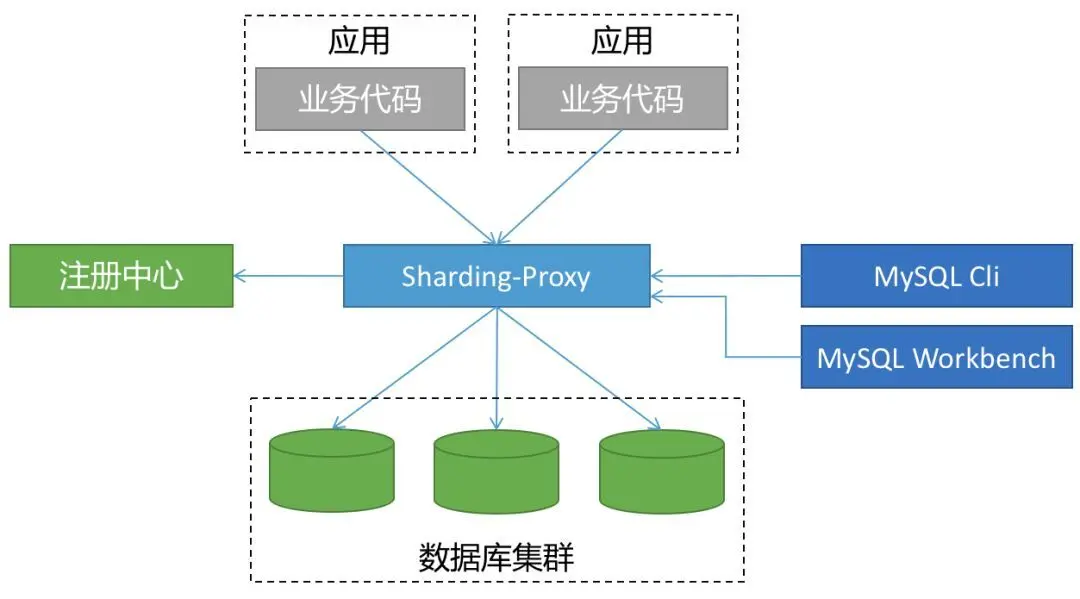
代理层介于应用程序与数据库间,每次请求都需要做一次转发,请求会存在额外的时延。
这种方式对于应用非常友好,应用基本零改动,和语言无关,可以通过连接共享减少连接数消耗。
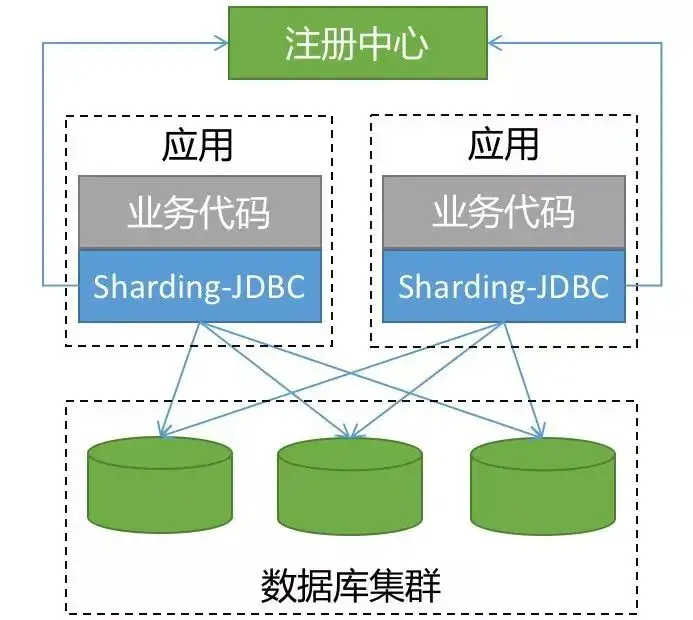
ShardingSphere-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身, 我们经常简称之为:sharding-jdbc 。
它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
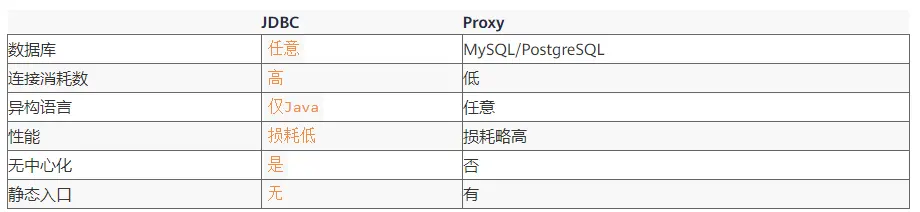
当我们在 Proxy 和 JDBC 两种模式选择时,可以参考下表对照:
越来越多的公司都在生产环境使用了 sharding-jdbc ,最核心的原因就是:简单(原理简单,易于实现,方便运维)。
在后端开发中,JDBC 编程是最基本的操作。不管 ORM 框架是 Mybatis 还是 Hibernate ,亦或是 spring-jpa ,他们的底层实现是 JDBC 的模型。
sharding-jdbc 的本质上就是实现 JDBC 的核心接口。
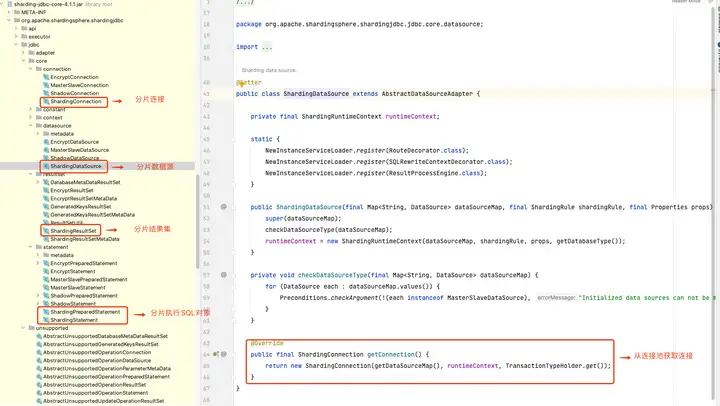

虽然我们理解了 sharding-jdbc 的本质,但是真正实现起来还有非常多的细节,下图展示了 Prxoy 和 JDBC 两种模式的核心流程。
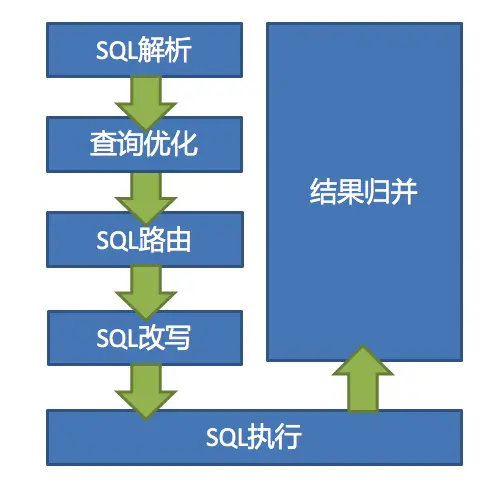
1.SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。
解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
2.执行器优化
合并和优化分片条件,如 OR 等。
3.SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
4.SQL 改写
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
5.SQL 执行
通过多线程执行器异步执行。
6.结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
本文的重点在于实战层面, sharding-jdbc 的实现原理细节我们会在后续的文章一一给大家呈现 。
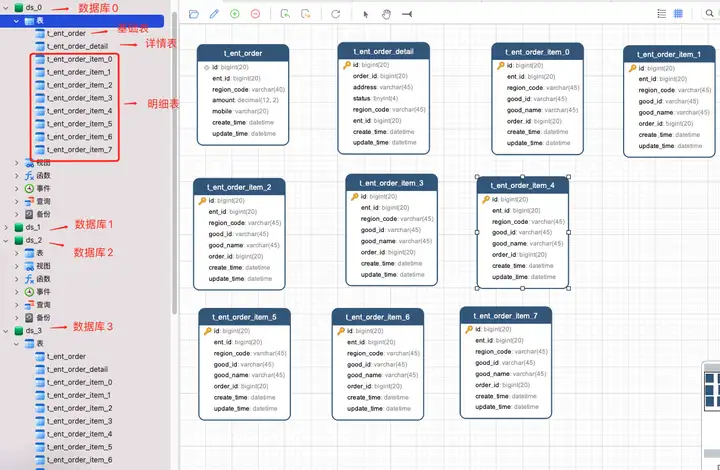
笔者曾经为武汉一家 O2O 公司订单服务做过分库分表架构设计 ,当企业用户创建一条采购订单 , 会生成如下记录:
订单数据采用了如下的分库分表策略:
首先创建 4 个库,分别是:ds_0、ds_1、ds_2、ds_3 。
这四个分库,每个分库都包含 订单基础表 , 订单详情表 ,订单明细表 。但是因为明细表需要分表,所以包含多张表。
然后 springboot 项目中配置依赖 :
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>配置文件中配置如下:
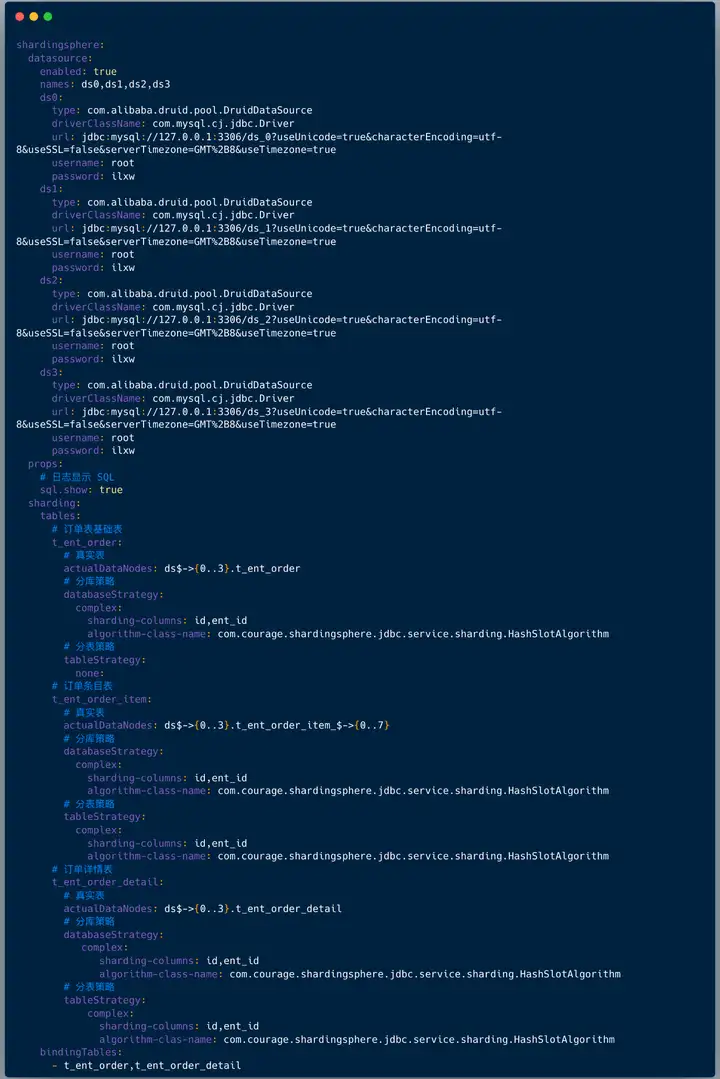

上图中我们看到配置分片规则包含如下两点:
对于我们的应用来讲,我们查询的逻辑表是:t_ent_order_item 。
它们在数据库中的真实形态是:t_ent_order_item_0 到 t_ent_order_item_7。
真实数据节点是指数据分片的最小单元,由数据源名称和数据表组成。
订单明细表的真实节点是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。
配置分库策略和分表策略 , 每种策略都需要配置分片字段( sharding-columns )和分片算法。
分片算法和阿里开源的数据库中间件 cobar 路由算法非常类似的。
假设现在需要将订单表平均拆分到4个分库 shard0 ,shard1 ,shard2 ,shard3 。
首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
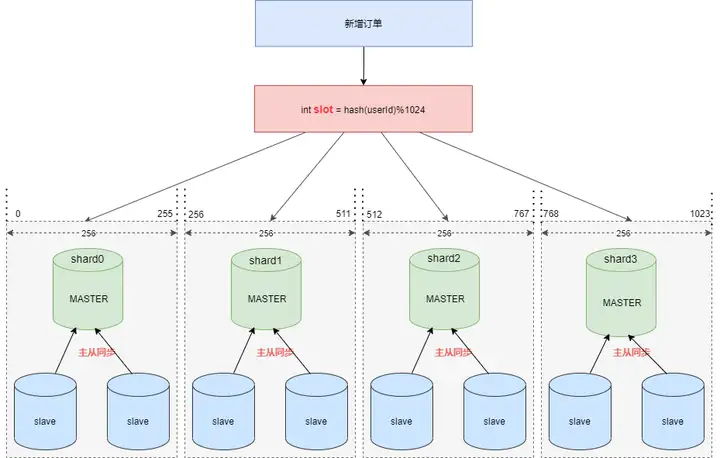
看起来分片算法很简单,但我们需要按照订单 ID 查询订单信息时依然需要路由四个分片,效率不高,那么如何优化呢 ?
答案是:基因法 & 自定义复合分片算法。
基因法是指在订单 ID 中携带企业用户编号信息,我们可以在创建订单 order_id 时使用雪花算法,然后将 slot 的值保存在 10位工作机器 ID 里。
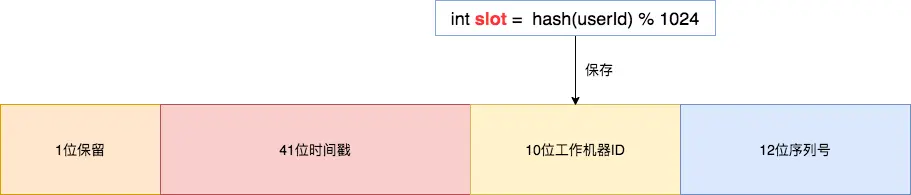
通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分片里。
Integer getWorkerId(Long orderId) {
Long workerId = (orderId >> 12) & 0x03ff;
return workerId.intValue();
}下图展示了订单 ID 使用雪花算法的生成过程,生成的编号会携带企业用户 ID 信息。

解决了分布式 ID 问题,接下来的一个问题:sharding-jdbc 可否支持按照订单 ID ,企业用户 ID 两个字段来决定分片路由吗?
答案是:自定义复合分片算法。我们只需要实现 ComplexKeysShardingAlgorithm 类即可。
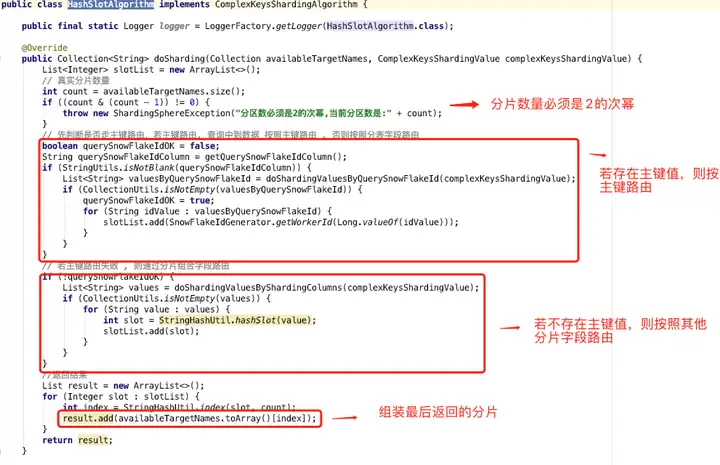
复合分片的算法流程非常简单:
1.分片键中有主键值,则直接通过主键解析出路由分片;
2.分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片。
既然做了分库分表,如何实现平滑扩容也是一个非常有趣的话题。
在数据同步之前,需要梳理迁移范围。
在进行数据同步前,需要先梳理所有表的唯一业务 ID,只有确定了唯一业务 ID 才能实现数据的同步操作。
需要注意的是:业务中是否有使用数据库自增 ID 做为业务 ID 使用的,如果有需要业务先进行改造 。另外确保每个表是否都有唯一索引,一旦表中没有唯一索引,就会在数据同步过程中造成数据重复的风险,所以我们先将没有唯一索引的表根据业务场景增加唯一索引(有可能是联合唯一索引)。
分表规则不同决定着 rehash 和数据校验的不同。需逐个表梳理是用户ID纬度分表还是非用户ID纬度分表、是否只分库不分表、是否不分库不分表等等。
接下来,进入数据同步环节。
整体方案见下图,数据同步基于 binlog ,独立的中间服务做同步,对业务代码无侵入。
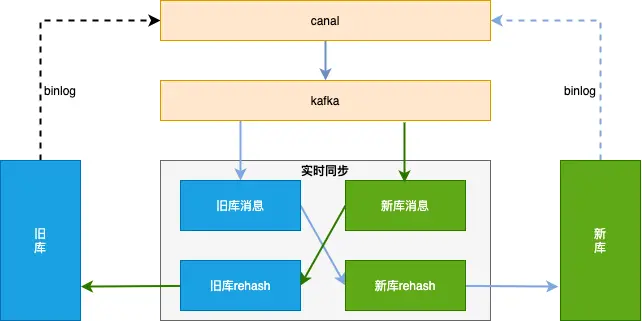
首先需要做历史数据全量同步:也就是将旧库迁移到新库。
单独一个服务,使用游标的方式从旧库分片 select 语句,经过 rehash 后批量插入 (batch insert)到新库,需要配置jdbc 连接串参数 rewriteBatchedStatements=true 才能使批处理操作生效。
因为历史数据也会存在不断的更新,如果先开启历史数据全量同步,则刚同步完成的数据有可能不是最新的。
所以我们会先开启增量数据单向同步(从旧库到新库),此时只是开启积压 kafka 消息并不会真正消费;然后在开始历史数据全量同步,当历史全量数据同步完成后,在开启消费 kafka 消息进行增量数据同步(提高全量同步效率减少积压也是关键的一环),这样来保证迁移数据过程中的数据一致。
增量数据同步考虑到灰度切流稳定性、容灾 和可回滚能力 ,采用实时双向同步方案,切流过程中一旦新库出现稳定性问题或者新库出现数据一致问题,可快速回滚切回旧库,保证数据库的稳定和数据可靠。
增量数据实时同步的大体思路 :
1.过滤循环消息
需要过滤掉循环同步的 binlog 消息 ;
2.数据合并
同一条记录的多条操作只保留最后一条。为了提高性能,数据同步组件接到 kafka 消息后不会立刻进行数据流转,而是先存到本地阻塞队列,然后由本地定时任务每X秒将本地队列中的N条数据进行数据流转操作。此时N条数据有可能是对同一张表同一条记录的操作,所以此处只需要保留最后一条(类似于 redis aof 重写);
3.update 转 insert
数据合并时,如果数据中有 insert + update 只保留最后一条 update ,会执行失败,所以此处需要将 update 转为 insert 语句 ;
4.按新表合并
将最终要提交的 N 条数据,按照新表进行拆分合并,这样可以直接按照新表纬度进行数据库批量操作,提高插入效率。
扩容方案文字来自 《256变4096:分库分表扩容如何实现平滑数据迁移》,笔者做了些许调整。
sharding-jdbc 的本质是实现 JDBC 的核心接口,架构相对简单。
实战过程中,需要配置数据源信息,逻辑表对应的真实节点和分库分表策略(分片字段和分片算法)
实现分布式主键直接路由到对应分片,则需要使用基因法 & 自定义复合分片算法 。
平滑扩容的核心是全量同步和实时双向同步,工程上有不少细节。
实战代码地址:https://github.com/makemyownlife/shardingsphere-jdbc-demo
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
1.什么是JDBC?Java数据库连接,(JavaDatabaseConnectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。JDBC也是SunMicrosystems的商标。我们通常说的JDBC是面向关系型数据库的。简而言之,JDBC就是JDK提供的关于数据库操作的一套接口规范,不同数据库厂商来负责实现这个接口,完成指定的操作。用程序和数据建立连接,分为三步骤:1.连接数据库2.执行SQL语句3.把查询到的结果集转换成JAVA对象2.对于MySQL的JDBC编程的前期准备工作知识拓展:JAR文件(Java归
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif