Elasticsearch有采集管道直说.其实我们在Kibana中就可以看到它已经提供了2个.所有的文档(Document)都是先通过管道在入库的cuiyaonan2000@163.com
默认提供的管道如下所示:
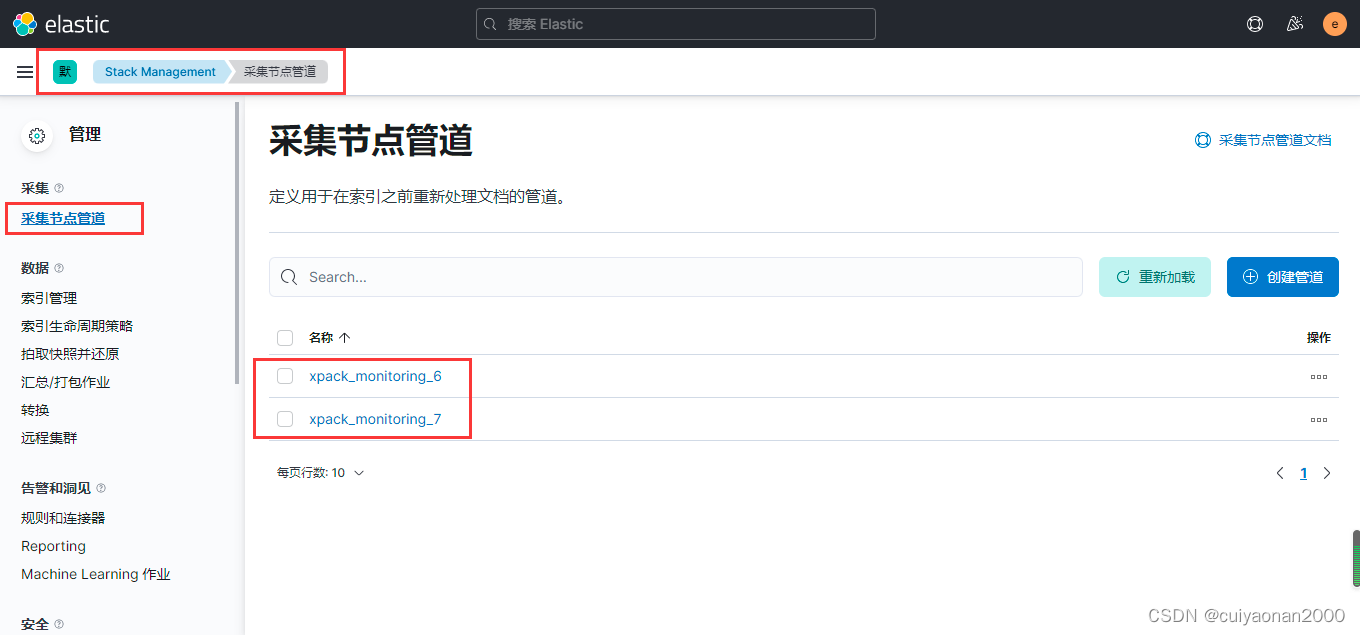
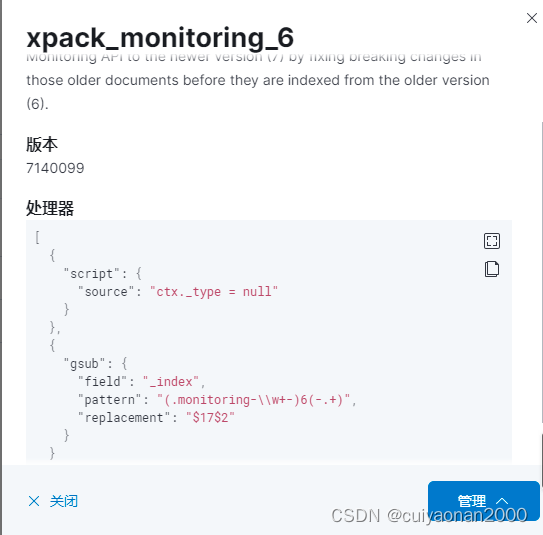
管道的定义如下所示
Ingest Node表示:预处理节点,是 ES 用于功能上命名的一种节点类型,可以通过 elasticsearch.xml 进行如下配置来标识出集群中的某个节点是否是 Ingest Node.
node.ingest: ture上述将 node.ingest 设置成 true,则表明当前节点是 Ingest Node,具有预处理能力, Elasticsearch 默认所有节点都是 Ingest Node,即集群中所有的节点都具有预处理能力.
用过 Logstash 对日志进行处理的用户都知道,一般情况下我们并不会直接将原始的日志进行加载到 Elasticsearch 集群,而是对原始日志信息进行(深)加工后保存到 Elasticsearch 集群中。比如 Logstash 支持多种解析器比如 json,kv,date 等,比较经典的是 grok.这里我们不会对 Logstash 的解析器进行详细说明,只是为了描述一个问题,有些时候我们需要 Logstash 来对加载到 Elasticsearch 中的数据进行处理,这个处理,从概念上而言,我们也能称之为"预处理。而这里我们所说的预处理也其实就是类似的概念。
Elasticsearch 5.x 版本开始,官方在内部集成了部分 Logstash 的功能,这就是 Ingest,而具有 Ingest 能力的节点称之为 Ingest Node.
如果要脱离 Logstash 来对在 Elasticsearch 写入文档之前对文档进行加工处理,比如为文档某个字段设置默认值,重命名某个字段,设置通过脚本来完成更加复杂的加工逻辑,我们则必须要了解两个基本概念: Pipeline 和 Processors.
Pipeline与Processor这里就以Pipeline和java中的Stream进行类比,两者从功能和概念上很类似,我们经常会对Stream中的数据进行处理,比如map操作,peek操作,reduce操作,count操作等,这些操作从行为上说,就是对数据的加工,而Pipeline也是如此,Pipeline也会对通过该Pipeline的数据(一般来说是文档)进行加工,比如上面说到的,修改文档的某个字段值,修改文档某个字段的类型等等.而Elasticsearch对该加工行为进行抽象包装,并称之为Processors.
Elasticsearch命名了多种类型的Processors来规范对文档的操作,比如set,append,date,join,json,kv等等.这些不同类型的Processors,我们会在后文进行说明
如此这般,Pipeline相当于java中的stream.而process相当于是一些类似于map,flatmap的算子cuiyaonan2000@163.com
定义一个 Pipeline 是件很简单的事情,官方给出了参考(pipeline中包含了processors):
PUT _ingest/pipeline/my-pipeline-id
{
"description" : "describe pipeline",
"processors" : [
{
"set" : {
"field": "foo",
"value": "bar"
}
}
]
}
上面的例子,表明通过指定的 URL 请求"_ingest/pipeline“定义了一个 ID 为”my-pipeline-id"的 pipeline,其中请求体中的存在两个必须要的元素:
description 描述该 pipeline 是做什么的processors 定义了一系列的 processors,这里只是简单的定义了一个赋值操作,即将字段名为"foo“的字段值都设置为”bar"
如果需要了解更多关于 Pipeline 定义的信息,可以参考: Ingest APIs
该API即用于我们测试自己的Pipeline的工具,可以帮助我们去测试自己的管道.
#如下测试pipeline的时候不指定pipeline,而是在测试内容中声明一个
POST _ingest/pipeline/_simulate
{
"pipeline" : {
// pipeline definition here
//因为没有在路径中设置pipeline的id,所以这里我们要声明一个
},
"docs" : [
{ "_source": {/** first document **/} },
{ "_source": {/** second document **/} },
// ...
]
}
#这里直接在路径中指明一个pipeline来测试
POST _ingest/pipeline/my-pipeline-id/_simulate
{
"docs" : [
{ "_source": {/** first document **/} },
{ "_source": {/** second document **/} },
// ...
]
}
执行如下的测试访问
POST _ingest/pipeline/_simulate
{
"pipeline" :
{
"description": "_description",
"processors": [
{
"set" : {
"field" : "field2",
"value" : "_value"
}
}
]
},
"docs": [
{
"_index": "index",
"_type": "type",
"_id": "id",
"_source": {
"foo": "bar"
}
},
{
"_index": "index",
"_type": "type",
"_id": "id",
"_source": {
"foo": "rab"
}
}
]
}
返回的内容
{
"docs": [
{
"doc": {
"_id": "id",
"_index": "index",
"_type": "type",
"_source": {
"field2": "_value",
"foo": "bar"
},
"_ingest": {
"timestamp": "2017-05-04T22:30:03.187Z"
}
}
},
{
"doc": {
"_id": "id",
"_index": "index",
"_type": "type",
"_source": {
"field2": "_value",
"foo": "rab"
},
"_ingest": {
"timestamp": "2017-05-04T22:30:03.188Z"
}
}
}
]
}
从具体的响应结果中看到,在文档通过 pipeline 时(或理解为被 pipeline 中的 processors 加工后),新的文档与原有的文档产生了差异,这些差异体现为:
field2 字段,这点我们可以通过对比响应前后的定义在"docs"中文档的_source 内容中看出瞬态)的字段,比如 timestamp,他们都在_ingest 节点下,(这些)字段都是临时与源文档存在一起,在被 pipeline 中的 processors 加工后后返回给对应的批量操作或索引操作之后。这些信息就不会携带返回。----额外增加的字段都在_ingest节点下cuiyaonan2000@163.com
每个文档都会有一些元数据字段信息(metadata filed),比如_id,_index,_type 等,我们在 processors 中也可以直接访问这些信息的,比如下面的例子:
{
"set": {
"field": "_id"
"value": "1"
}
}
只是引用方式的区别,瞬态字段需要使用{{}}来访问,没有文档元数据的字段访问方便cuiyaonan2000@163.com
{
"set": {
"field": "received"
"value": "{{_ingest.timestamp}}"
}
}
系统提供的默认的类型如下所示.
Append Processor 追加处理器Convert Processor 转换处理器Date Processor 日期转换器Date Index Name Processor 日期索引名称处理器Fail Processor 失败处理器Foreach Processor 循环处理器Grok Processor Grok 处理器Gsub ProcessorJoin ProcessorJSON ProcessorKV ProcessorLowercase ProcessorRemove ProcessorRename ProcessorScript ProcessorSplit ProcessorSort ProcessorTrim ProcessorUppercase ProcessorDot Expander Processor实例参考文档Elasticsearch Pipeline 详解_自知自省的博客-CSDN博客_es的pipeline
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
刚刚将应用程序从rails3.0.9升级到3.2.1,当我运行bundleexecrakeassets:precompile时出现错误,这很好,但是回溯没有告诉我在哪里语法问题来self的css或scss文件。我尝试对“0ee5c0e69c92af0”进行greping,但该字符串没有出现在我的项目中。bundleexecrakeassets:precompile:allRAILS_ENV=productionRAILS_GROUPS=assets--trace**Invokeassets:precompile:all(first_time)**Executeassets:precom
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
我有一个关于配置elasticsearch以连接AWSelasticsearch服务以在生产环境中运行项目的问题。我的gem文件:gem'searchkick'gem'faraday_middleware-aws-signers-v4'gem'aws-sdk','~>2'gem"elasticsearch",">=1.0.15"引用:https://github.com/ankane/searchkick我的config/initializers/elasticsearch.rb文件:require"faraday_middleware/aws_signers_v4"ENV["ELAS
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
我在查询中使用geo_distancefilter和tire,它工作正常:search.filter:geo_distance,:distance=>"#{request.distance}km",:location=>"#{request.lat},#{request.lng}"我预计结果会以某种方式包括到我用于过滤器的地理位置的计算距离。有没有办法告诉elasticsearch在响应中包含它,这样我就不必在ruby中为每个结果计算它?==更新==我在谷歌群组中的foundtheanswer:search.sortdoby"_geo_distance","location"=>"