摘要:今天,我们就一起来简单看看Thread类的源码。
本文分享自华为云社区《【高并发】Thread类的源码精髓》,作者:冰 河。
最近和一个朋友聊天,他跟我说起了他去XXX公司面试的情况,面试官的一个问题把他打懵了!竟然问他:你经常使用Thread创建线程,那你看过Thread类的源码吗?我这个朋友自然是没看过Thread类的源码,然后,就没有然后了!!!
所以,我们学习技术不仅需要知其然,更需要知其所以然,今天,我们就一起来简单看看Thread类的源码。
注意:本文是基于JDK 1.8来进行分析的。
我们可以使用下图来表示Thread类的继承关系。

由上图我们可以看出,Thread类实现了Runnable接口,而Runnable在JDK 1.8中被@FunctionalInterface注解标记为函数式接口,Runnable接口在JDK 1.8中的源代码如下所示。
@FunctionalInterface
public interface Runnable {
public abstract void run();
}Runnable接口的源码比较简单,只是提供了一个run()方法,这里就不再赘述了。
接下来,我们再来看看@FunctionalInterface注解的源码,如下所示。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FunctionalInterface {}可以看到,@FunctionalInterface注解声明标记在Java类上,并在程序运行时生效。
Thread在java.lang包下,Thread类的定义如下所示。
public class Thread implements Runnable {打开Thread类后,首先,我们会看到在Thread类的最开始部分,定义了一个静态本地方法registerNatives(),这个方法主要用来注册一些本地系统的资源。并在静态代码块中调用这个本地方法,如下所示。
//定义registerNatives()本地方法注册系统资源
private static native void registerNatives();
static {
//在静态代码块中调用注册本地系统资源的方法
registerNatives();
}Thread类中的成员变量如下所示。
//当前线程的名称
private volatile String name;
//线程的优先级
private int priority;
private Thread threadQ;
private long eetop;
//当前线程是否是单步线程
private boolean single_step;
//当前线程是否在后台运行
private boolean daemon = false;
//Java虚拟机的状态
private boolean stillborn = false;
//真正在线程中执行的任务
private Runnable target;
//当前线程所在的线程组
private ThreadGroup group;
//当前线程的类加载器
private ClassLoader contextClassLoader;
//访问控制上下文
private AccessControlContext inheritedAccessControlContext;
//为匿名线程生成名称的编号
private static int threadInitNumber;
//与此线程相关的ThreadLocal,这个Map维护的是ThreadLocal类
ThreadLocal.ThreadLocalMap threadLocals = null;
//与此线程相关的ThreadLocal
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
//当前线程请求的堆栈大小,如果未指定堆栈大小,则会交给JVM来处理
private long stackSize;
//线程终止后存在的JVM私有状态
private long nativeParkEventPointer;
//线程的id
private long tid;
//用于生成线程id
private static long threadSeqNumber;
//当前线程的状态,初始化为0,代表当前线程还未启动
private volatile int threadStatus = 0;
//由(私有)java.util.concurrent.locks.LockSupport.setBlocker设置
//使用java.util.concurrent.locks.LockSupport.getBlocker访问
volatile Object parkBlocker;
//Interruptible接口中定义了interrupt方法,用来中断指定的线程
private volatile Interruptible blocker;
//当前线程的内部锁
private final Object blockerLock = new Object();
//线程拥有的最小优先级
public final static int MIN_PRIORITY = 1;
//线程拥有的默认优先级
public final static int NORM_PRIORITY = 5;
//线程拥有的最大优先级
public final static int MAX_PRIORITY = 10;从Thread类的成员变量,我们可以看出,Thread类本质上不是一个任务,它是一个实实在在的线程对象,在Thread类中拥有一个Runnable类型的成员变量target,而这个target成员变量就是需要在Thread线程对象中执行的任务。
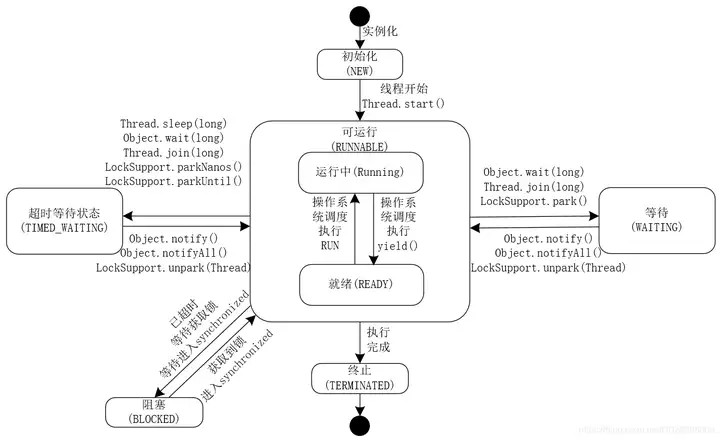
在Thread类的内部,定义了一个枚举State,如下所示。
public enum State {
//初始化状态
NEW,
//可运行状态,此时的可运行包括运行中的状态和就绪状态
RUNNABLE,
//线程阻塞状态
BLOCKED,
//等待状态
WAITING,
//超时等待状态
TIMED_WAITING,
//线程终止状态
TERMINATED;
}这个枚举类中的状态就代表了线程生命周期的各状态。我们可以使用下图来表示线程各个状态之间的转化关系。
Thread类中的所有构造方法如下所示。
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
Thread(Runnable target, AccessControlContext acc) {
init(null, target, "Thread-" + nextThreadNum(), 0, acc, false);
}
public Thread(ThreadGroup group, Runnable target) {
init(group, target, "Thread-" + nextThreadNum(), 0);
}
public Thread(String name) {
init(null, null, name, 0);
}
public Thread(ThreadGroup group, String name) {
init(group, null, name, 0);
}
public Thread(Runnable target, String name) {
init(null, target, name, 0);
}
public Thread(ThreadGroup group, Runnable target, String name) {
init(group, target, name, 0);
}
public Thread(ThreadGroup group, Runnable target, String name,
long stackSize) {
init(group, target, name, stackSize);
}其中,我们最经常使用的就是如下几个构造方法了。
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
public Thread(String name) {
init(null, null, name, 0);
}
public Thread(ThreadGroup group, String name) {
init(group, null, name, 0);
}
public Thread(Runnable target, String name) {
init(null, target, name, 0);
}
public Thread(ThreadGroup group, Runnable target, String name) {
init(group, target, name, 0);
}通过Thread类的源码,我们可以看出,Thread类在进行初始化的时候,都是调用的init()方法,接下来,我们看看init()方法是个啥。
private void init(ThreadGroup g, Runnable target, String name, long stackSize) {
init(g, target, name, stackSize, null, true);
}
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
//线程的名称为空,抛出空指针异常
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name;
Thread parent = currentThread();
//获取系统安全管理器
SecurityManager security = System.getSecurityManager();
//线程组为空
if (g == null) {
//获取的系统安全管理器不为空
if (security != null) {
//从系统安全管理器中获取一个线程分组
g = security.getThreadGroup();
}
//线程分组为空,则从父线程获取
if (g == null) {
g = parent.getThreadGroup();
}
}
//检查线程组的访问权限
g.checkAccess();
//检查权限
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
g.addUnstarted();
//当前线程继承父线程的相关属性
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader();
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
this.target = target;
setPriority(priority);
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
//设置线程id
tid = nextThreadID();
}Thread类中的构造方法是被创建Thread线程的线程调用的,此时,调用Thread的构造方法创建线程的线程就是父线程,在init()方法中,新创建的Thread线程会继承父线程的部分属性。
既然Thread类实现了Runnable接口,则Thread类就需要实现Runnable接口的run()方法,如下所示。
@Override
public void run() {
if (target != null) {
target.run();
}
}可以看到,Thread类中的run()方法实现非常简单,只是调用了Runnable对象的run()方法。所以,真正的任务是运行在run()方法中的。另外,需要注意的是:直接调用Runnable接口的run()方法不会创建新线程来执行任务,如果需要创建新线程执行任务,则需要调用Thread类的start()方法。
public synchronized void start() {
//线程不是初始化状态,则直接抛出异常
if (threadStatus != 0)
throw new IllegalThreadStateException();
//添加当前启动的线程到线程组
group.add(this);
//标记线程是否已经启动
boolean started = false;
try {
//调用本地方法启动线程
start0();
//将线程是否启动标记为true
started = true;
} finally {
try {
//线程未启动成功
if (!started) {
//将线程在线程组里标记为启动失败
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
private native void start0();从start()方法的源代码,我们可以看出:start()方法使用synchronized关键字修饰,说明start()方法是同步的,它会在启动线程前检查线程的状态,如果不是初始化状态,则直接抛出异常。所以,一个线程只能启动一次,多次启动是会抛出异常的。
这里,也是面试的一个坑:面试官:【问题一】能不能多次调用Thread类的start()方法来启动线程吗?【问题二】多次调用Thread线程的start()方法会发生什么?【问题三】为什么会抛出异常?
调用start()方法后,新创建的线程就会处于就绪状态(如果没有分配到CPU执行),当有空闲的CPU时,这个线程就会被分配CPU来执行,此时线程的状态为运行状态,JVM会调用线程的run()方法执行任务。
sleep()方法可以使当前线程休眠,其代码如下所示。
//本地方法,真正让线程休眠的方法
public static native void sleep(long millis) throws InterruptedException;
public static void sleep(long millis, int nanos)
throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
//调用本地方法
sleep(millis);
}sleep()方法会让当前线程休眠一定的时间,这个时间通常是毫秒值,这里需要注意的是:调用sleep()方法使线程休眠后,线程不会释放相应的锁。
join()方法会一直等待线程超时或者终止,代码如下所示。
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
public final synchronized void join(long millis, int nanos)
throws InterruptedException {
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
join(millis);
}
public final void join() throws InterruptedException {
join(0);
}join()方法的使用场景往往是启动线程执行任务的线程,调用执行线程的join()方法,等待执行线程执行任务,直到超时或者执行线程终止。
interrupt()方法是中断当前线程的方法,它通过设置线程的中断标志位来中断当前线程。此时,如果为线程设置了中断标志位,可能会抛出InteruptedExeption异常,同时,会清除当前线程的中断状态。这种方式中断线程比较安全,它能使正在执行的任务执行能够继续执行完毕,而不像stop()方法那样强制线程关闭。代码如下所示。
public void interrupt() {
if (this != Thread.currentThread())
checkAccess();
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupt0(); // Just to set the interrupt flag
b.interrupt(this);
return;
}
}
//调用本地方法中断线程
interrupt0();
}
private native void interrupt0();作为技术人员,要知其然,更要知其所以然,我那个朋友技术本身不错,各种框架拿来就用,基本没看过常用的框架源码和JDK中常用的API,属于那种CRUD型程序员,这次面试就栽在了一个简单的Thread类上,所以,大家在学会使用的时候,一定要了解下底层的实现才好啊!
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
大家好!我想知道Ruby中未使用语法ClassName.method_name调用的方法是如何工作的。我头脑中的一些是puts、print、gets、chomp。可以在不使用点运算符的情况下调用这些方法。为什么是这样?他们来自哪里?我怎样才能看到这些方法的完整列表? 最佳答案 Kernel中的所有方法都可用于Object类的所有对象或从Object派生的任何类。您可以使用Kernel.instance_methods列出它们。 关于没有类的Ruby方法?,我们在StackOverflow
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我正在写一篇关于在Ruby中几乎一切都是对象的博客文章,我试图通过以下示例来展示这一点:classCoolBeansattr_accessor:beansdefinitialize@bean=[]enddefcount_beans@beans.countendend所以从类中我们可以看出它有4个方法(当然,除非我错了):它可以在创建新实例时初始化一个默认的空bean数组它可以计算它有多少个bean它可以读取它有多少个bean(通过attr_accessor)它可以向空数组写入(或添加)更多bean(也通过attr_accessor)但是,当我询问类本身它有哪些实例方法时,我没有看到默认
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我理解(我认为)Ruby中类变量和类的实例变量之间的区别。我想知道如何从该类外部访问该类的实例变量。从内部(即在类方法中而不是实例方法中),它可以直接访问,但是从外部,有没有办法做MyClass.class.[@$#]variablename?我没有任何具体原因要这样做,只是学习Ruby并想知道是否可行。 最佳答案 classMyClass@my_class_instance_var="foo"class上述yield:>>foo我相信Arkku演示了如何从类外部访问类变量(@@),而不是类实例变量(@)。我从这篇文章中提取了上述内
我目前对后台队列不太满意。我正在尝试让Resque工作。我已经安装了redis和Resquegem。Redis正在运行。一个worker正在运行(rakeresque:workQUEUE=simple)。使用Web界面,我可以看到工作人员正在运行并等待工作。当我运行“rakeget_updates”时,作业已排队但失败了。我已经用defself.perform和defperform试过了。发条.raketask:get_updates=>:environmentdoResque.enqueue(GetUpdates)end类文件(app/workers/get_updates.rb)c
这个问题在这里已经有了答案:Inrubyhowtouseclasslevellocalvariable?(arubynewbie'squestion)(4个答案)关闭6年前。我注意到以下代码在语法上是正确的:classFoobar=3end现在,我知道实例变量由@访问,类变量由@@访问,但我不知道在哪里bar存储在这种情况下或如何访问它。如何找到bar的范围?