最近一段时间,以 “羊驼” 家族为代表的各类 ChatGPT 替代模型不断涌现。一方面,开源社区也有了可以与 ChatGPT “一较高下” 的开源模型;而另一方面,各模型在如何提升 LLM 的指令表现方面以及评估 LLM 效果的方法不尽相同。
此前,一个基于斯坦福的 Alpaca 、并进行了中文优化的项目受到大家关注,即开源中文对话大模型 70 亿参数的 BELLE(Be Everyone's Large Language model Engine)。它基于斯坦福的 Alpaca 完成,但进行了中文优化,并对生成代码进行了一些修改,不仅如此,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。
BELLE 的目标是促进中文对话大模型开源社区的发展,愿景是成为能够帮到每一个人的 LLM Engine。
相比如何做好大语言模型的预训练,BELLE 更关注如何在开源预训练大语言模型的基础上,帮助每一个人都能够得到一个属于自己的、效果尽可能好的具有指令表现能力的语言模型,降低大语言模型、特别是中文大语言模型的研究和应用门槛。为此,BELLE 项目会持续开放指令训练数据、相关模型、训练代码、应用场景等,也会持续评估不同训练数据、训练算法等对模型表现的影响。
BELLE 项目亮点包括:
还有其他功能,请移步 Github 项目 。
项目地址:https://github.com/LianjiaTech/BELLE
BELLE 项目的研究方向着眼于提升中文指令调优模型的指令跟随、指令泛化效果,降低模型训练和研究工作的门槛,让更多人都能感受到大语言模型带来的帮助。
为此 BELLE 进行了一系列研究,涵盖模型评估方法、影响模型指令表现效果的因素、模型调优等多方面。
最近,两篇相关论文已经公开,下面我们看看论文内容。
论文 1:Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation

论文地址:https://arxiv.org/pdf/2304.07854.pdf
为了推动开源大语言模型的发展,大家投入了大量精力开发能够类似于 ChatGPT 的低成本模型。首先,为了提高模型在中文领域的性能和训练 / 推理效率,我们进一步扩展了 LLaMA 的词汇表,并在 34 亿个中文词汇上进行了二次预训练。
此外,目前可以看到基于 ChatGPT 产生的指令训练数据方式有:1)参考 Alpaca 基于 GPT3.5 得到的 self-instruct 数据;2)参考 Alpaca 基于 GPT4 得到的 self-instruct 数据;3)用户使用 ChatGPT 分享的数据 ShareGPT。在这里,我们着眼于探究训练数据类别对模型性能的影响。具体而言,我们考察了训练数据的数量、质量和语言分布等因素,以及我们自己采集的中文多轮对话数据,以及一些公开可访问的高质量指导数据集。
为了更好的评估效果,我们使用了一个包含一千个样本和九个真实场景的评估集来测试各种模型,同时通过量化分析来提供有价值的见解,以便更好地促进开源聊天模型的发展。
这项研究的目标是填补开源聊天模型综合评估的空白,以便为这一领域的持续进步提供有力支持。
实验结果如下:
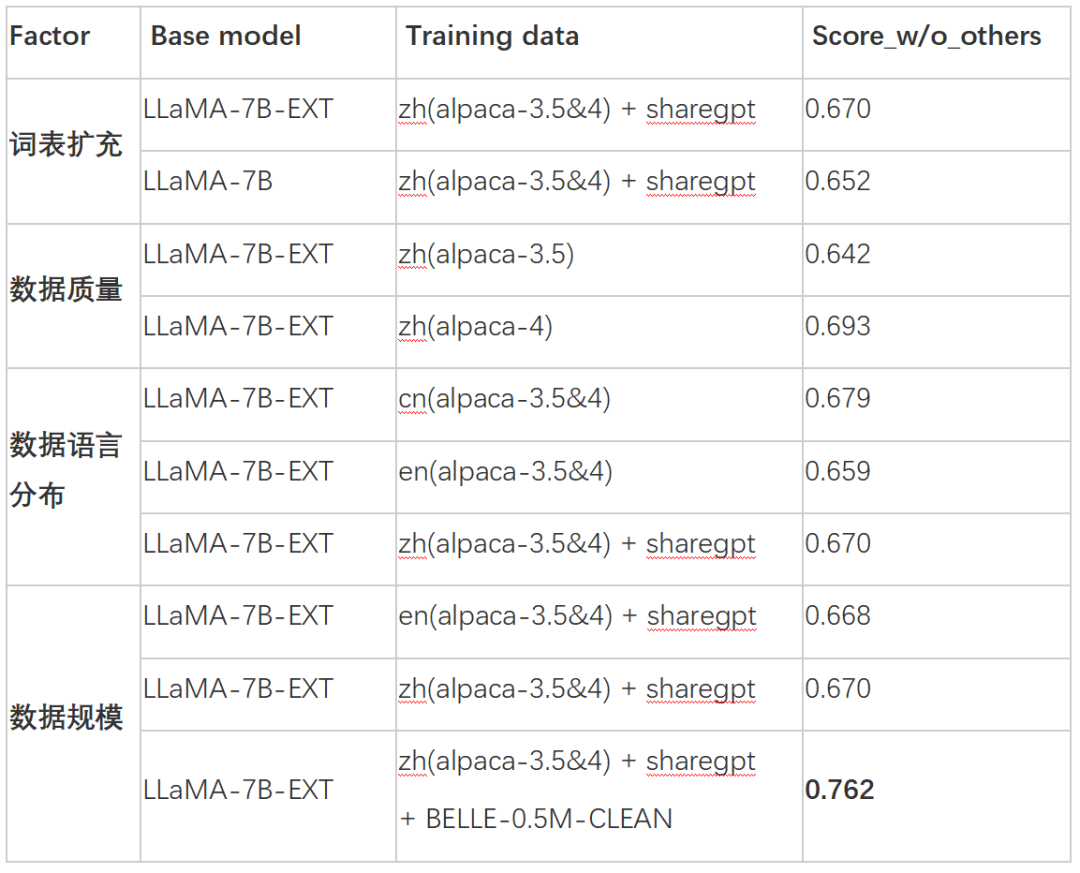
其中 BELLE-0.5M-CLEAN 是从 230 万指令数据中清洗得到 0.5M 数据,其中包含单轮和多轮对话数据,和之前开放的 0.5M 数据不是同一批数据。
需要强调指出的是,通过案例分析,我们发现我们的评估集在全面性方面存在局限性,这导致了模型分数的改善与实际用户体验之间的不一致。构建一个高质量的评估集是一个巨大的挑战,因为它需要在保持平衡难易程度的同时包含尽可能多样的使用场景。如果评估样本过于困难,那么所有模型的表现将会很差,更难辨别各种训练数据和策略的效果;相反,如果评估样本都相对容易,评估将失去其比较价值。同样地,评估集多样性不够的时候,容易出现评估有偏(例如当某个模型的训练和评估领域或任务类型十分一致)。二者的联合分布还可能导致部分任务上难易区分度高,部分任务上难易区分度低,进一步加大评估的难度和有效性。此外,必须确保评估数据与训练数据保持独立。
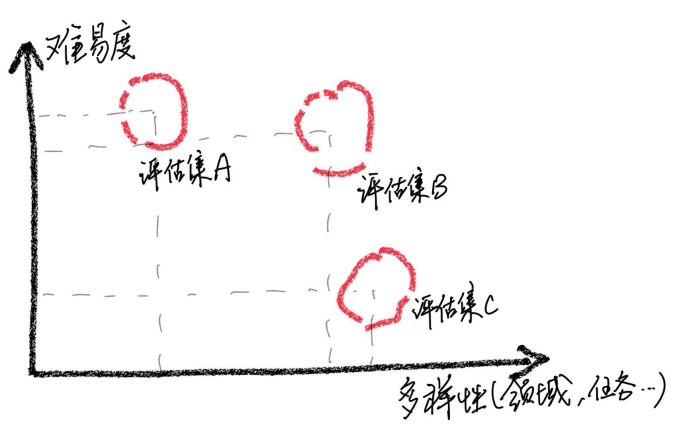
图 1 评估集的难易度与多样性分布示意图
基于这些观察,我们谨慎地提醒不要假设模型仅通过在有限数量的测试样本上获得良好结果就已经达到了与 ChatGPT 相当的性能水平。我们认为,优先发展全面评估集的持续发展具有重要意义。
这篇工作中的相关数据和模型将会于近日在 BELLE 项目中开源。
论文 2:A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model

论文地址:https://arxiv.org/pdf/2304.08109.pdf
为了实现对大语言模型的指令调优,受限于资源和成本,许多研究者开始使用参数高效的调优技术,例如 LoRA,来进行指令调优,这也取得了一些令人鼓舞的成果。相较于全参数微调,基于 LoRA 的调优在训练成本方面展现出明显的优势。在这个研究报告中,我们选用 LLaMA 作为基础模型,对全参数微调和基于 LoRA 的调优方法进行了实验性的比较。
实验结果揭示,选择合适的基础模型、训练数据集的规模、可学习参数的数量以及模型训练成本均为重要因素。
我们希望本文的实验结论能对大型语言模型的训练提供有益的启示,特别是在中文领域,协助研究者在训练成本与模型性能之间找到更佳的权衡策略。
实验结果如下:
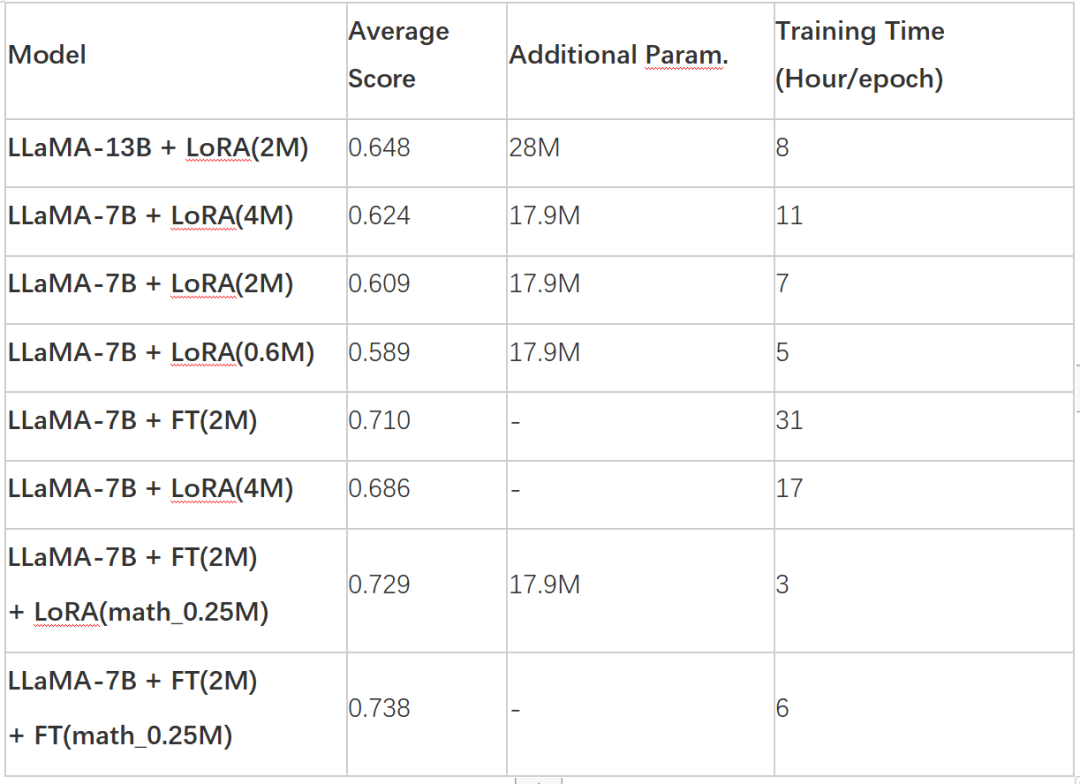
其中的 Average Score 是基于本项目集目前开放的 1000 条评估集合得到的(见下文评估数据部分)。LLaMA-13B + LoRA (2M) 代表使用 LLaMA-13B 作为基础模型和 LoRA 训练方法,在 2M 指令数据上进行训练的模型;而 LLaMA-7B + FT (2M) 代表了一个使用全参数微调进行训练的模型。所有这些实验都是在 8 块 NVIDIA A100-40GB GPU 上进行的,实验细节请参考我们的论文。
根据评估,我们的模型在数学任务上表现不佳,得分大多低于 0.5。为了验证 LoRA 在特定任务上的适应能力,我们使用增量 0.25M 数学数据集(math_0.25M)来提升模型的数学能力,并与增量微调方法作为对比。从实验结果可以看出,增量微调仍然表现更好,但需要更长的训练时间。LoRA 和增量微调都提高了模型的整体性能。从论文附录中的详细数据可以看出,LoRA 和增量微调都在数学任务中显示出显著的改进,而只会导致其他任务的轻微性能下降。
总体而言:1) 选择基础模型对于 LoRA 调整的有效性具有显著影响;2)增加训练数据量可以持续提高 LoRA 模型的有效性;3)LoRA 调整受益于模型参数的数量。对于 LoRA 方案的使用,我们建议可以在已经完成了指令学习的模型的基础上针对特定任务做 loRA 的自适应训练。
同样地,该论文中的相关模型也会尽快开放在 BELLE 项目中。
目前 BELLE 已经开放的数据分为两部分:最近开放的 10M 中文数据集与早前开放的 1.5M 中文数据集。
10M 中文数据集
包含数个由 BELLE 项目产生的不同指令类型、不同领域的子集。目前正在逐步整理中,将会逐渐发布。
评估数据
如上文所述,评估数据的质量对评估 LLM 的效果十分关键。BELLE 项目开放的中文评估集包含由 BELLE 项目产生的约 1000 条不同指令类型、不同领域的评估样例,并试图兼顾评估集的多样性与难易度。评估集的数据分布见图 2。
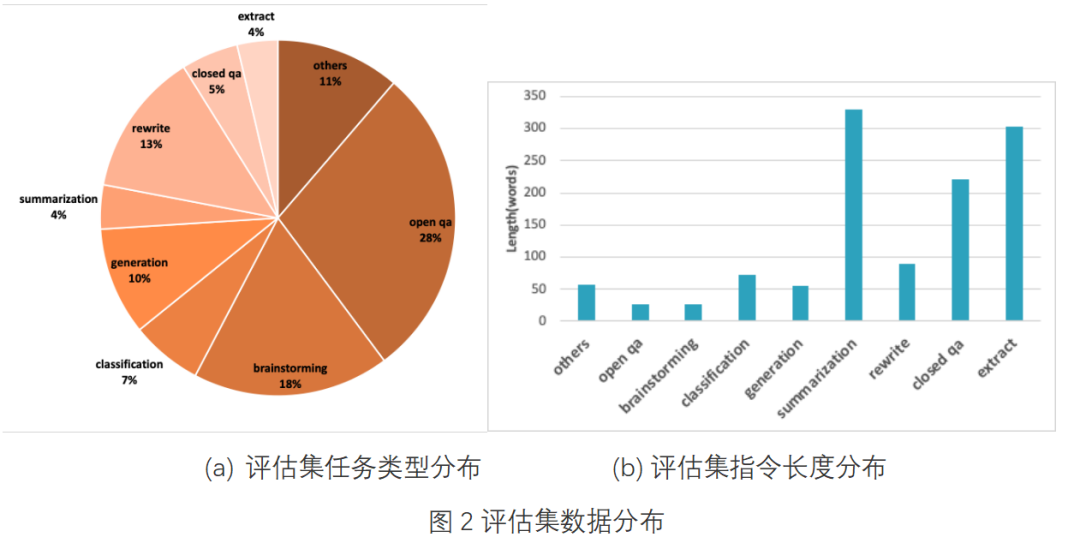
多样性方面,评估集涵盖 extract、open qa、closed qa、rewrite、generation、summerization、classification、brainstorming、others 9 种任务类型,并涵盖市场销售、健康饮食、语言文学、旅行、多种编程语言、环保、音乐、历史、厨艺、影视、体育赛事、医学、金融、科技等多个主题。任务类型分布见图 2 (a)。
难易度方面,评估集目前尽可能加入了一些难度偏高的样本,并且平衡评估集与标注回复的平均指令长度分布。
开源社区中已经诞生了如 llama.cpp、GPT4ALL、WebLLM 等 LLM 离线部署加速方案。虽然这些项目已经将动辄几十 GB 的显存需求和专业 GPU 的算力需求降低至一般的消费电子设备也可运行,但大多仍然需要一些技能才可部署及体验。
BELLE 希望进一步拓展大语言模型的使用场景,让更多用户即使没有专业设备也能感受到 LLM 带来的帮助。提供了纯离线、跨平台的 BELLE 聊天应用:结合 4bit 量化后的 ChatBELLE 模型、llama.cpp 和 Flutter 跨平台 UI,用户仅需安装 app、下载模型,即可在各类移动设备上不需联网本地体验 ChatBELLE 模型。
首先来看看效果:
macOS
在 M1 Max Macbook 上仅使用 CPU 实时运行,无论是加载还是推理都十分迅速:

相信随着 LLM 端上推理相关算法和软硬件技术的逐步发展,纯离线端上模型的效果将越来越好。BELLE 项目将持续优化 ChatBELLE 模型的性能和 App 功能,努力为更多用户带来更优质更丰富的体验。
近两个月,LLM 开源社区在基础模型研究、模型指令微调、模型应用场景等多方面的进展称得上日新月异、百花齐放。BELLE 项目组对这些进展感到欣喜之余,也希望贡献自己微薄之力,促进开源 LLM,特别是中文开源 LLM 的发展。
虽然在大家不懈努力下开源模型在效果方面已经取得了长足进步,甚至一些模型在个别方面已经与 ChatGPT 甚至 GPT-4 效果比肩,我们仍然需要直面与 OpenAI 的差距。目前,ChatGPT 的能力之多样、指令跟随和泛化能力之强、安全性之高,仍然需要开源社区脚踏实地地不断提升来追赶。在全社区的共同努力下,希望大语言模型将真正属于每一个人,能够帮助到每一个人。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序