目录
二分查找分为整数二分和浮点数二分,一般所说的二分查找都是指整数二分。
满足单调性的数组一定可以使用二分查找,但可以使用二分查找的数组不一定需要满足单调性。
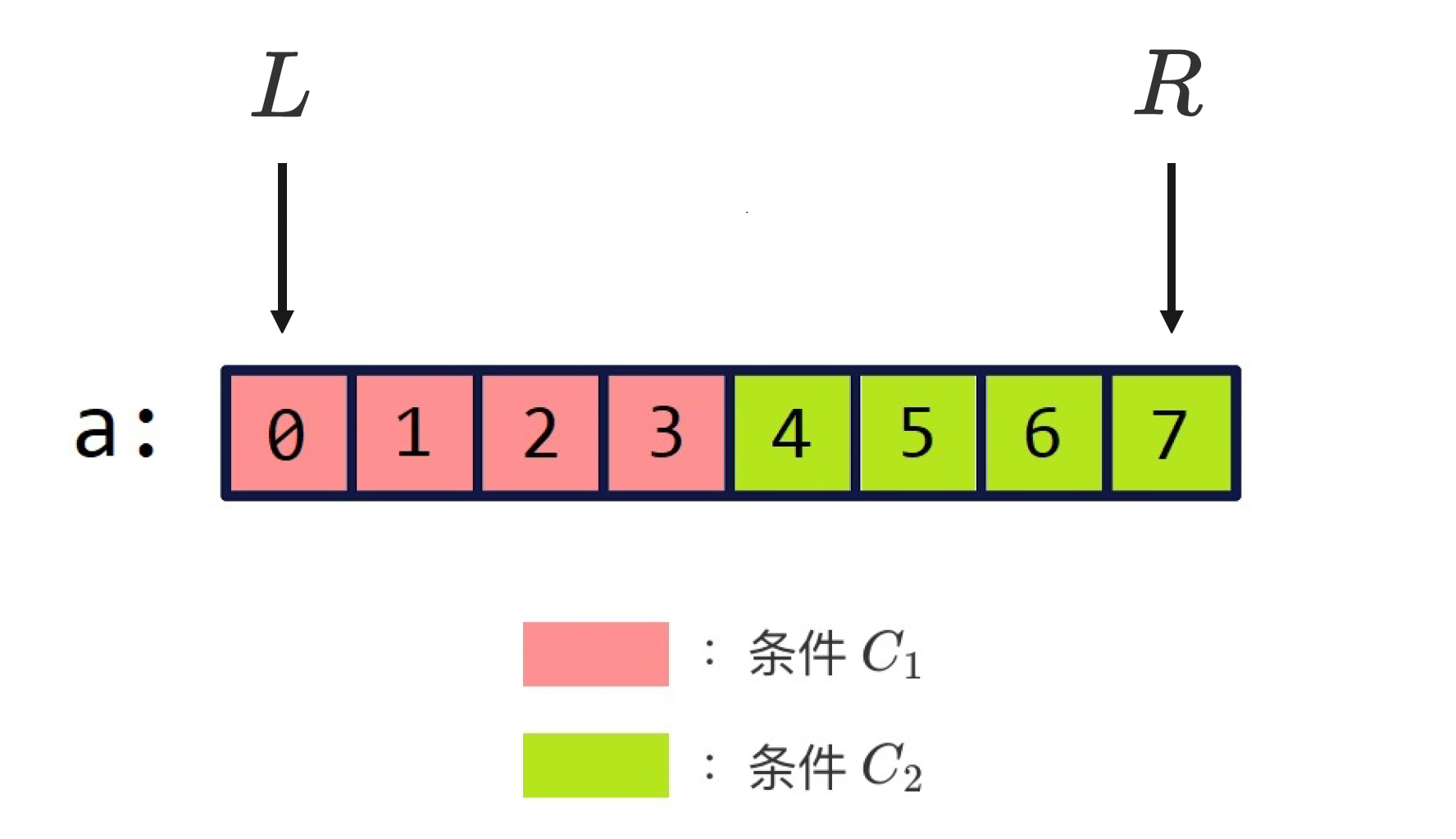
不妨假设我们找到了条件 C 1 C_1 C1,它和它的对立条件 C 2 C_2 C2 能够将数组 a a a 一分为二,如下图所示:
因为
C
1
C_1
C1 和
C
2
C_2
C2 互为对立,故总有
C
1
∪
C
2
≡
True
,
C
1
∩
C
2
≡
False
C_1\cup C_2\equiv \text{True},\;C_1\cap C_2\equiv \text{False}
C1∪C2≡True,C1∩C2≡False(用C++语言描述,就是 c1 || !c1 总是为真,c1 && !c1 总是为假)。换句话说,
∀
x
∈
a
\forall \,x\in a
∀x∈a,
x
x
x 至少满足
C
1
C_1
C1 和
C
2
C_2
C2 中的一个,且
x
x
x 不会同时满足
C
1
C_1
C1 和
C
2
C_2
C2。
观察上图可以发现,索引 3 3 3 和索引 4 4 4 这两个位置都可以作为 C 1 C_1 C1 和 C 2 C_2 C2 的分界点。其中,索引 3 3 3 是红色区域的右边界,索引 4 4 4 是绿色区域的左边界。而我们接下来要讨论的二分查找模板就是用来寻找 C 1 C_1 C1 和 C 2 C_2 C2 的分界点的。
前面说过, C 1 C_1 C1 和 C 2 C_2 C2 的分界点一共有两个,因此我们的整数二分查找模板也有两个。一个用来查找右边界(即左侧的分界点,对应索引 3 3 3),一个用来查找左边界(即右侧的分界点,对应索引 4 4 4)。这里首先介绍查找右边界的模板。
因为查找的是红色区域的右边界,所以先定义一个函数 check(i),其中参数
i
i
i 是索引。当
i
i
i 位于红色区域,即
0
≤
i
≤
3
0\leq i \leq 3
0≤i≤3 时,check(i) 为真;当
i
i
i 位于绿色区域,即
4
≤
i
≤
7
4\leq i \leq 7
4≤i≤7 时,check(i) 为假。
初始时设置左右两个指针分别位于数组的左右两端,每次循环时计算
m
i
d
=
l
+
r
2
mid=\frac{l+r}{2}
mid=2l+r(至于
m
i
d
mid
mid 到底取多少稍后会说),然后判断 check(mid) 的值(为实现二分查找,我们需要确保每次缩小区间时答案都落在区间内。这样一来,当最终 l == r 时,l 就是我们需要的答案)。如果 check(mid) 为真,说明
m
i
d
mid
mid 位于红色区域,且
m
i
d
mid
mid 有可能就是右边界,因此接下来令
l
=
m
i
d
l=mid
l=mid 来缩小查找范围(因为我们要保证缩小后的区间仍然包含答案);如果 check(mid) 为假,说明
m
i
d
mid
mid 位于绿色区域,且
m
i
d
mid
mid 必不可能是红色区域的右边界,因为
m
i
d
mid
mid 最多是索引
4
4
4,因此令
r
=
m
i
d
−
1
r=mid-1
r=mid−1 来缩小查找范围。
接下来重点关注
m
i
d
mid
mid 到底该取多少。如果
m
i
d
=
l
+
r
2
mid=\frac{l+r}{2}
mid=2l+r,其中的除法代表整除,在某一轮循环出现了
r
−
l
=
1
r-l=1
r−l=1,则
m
i
d
=
2
l
+
1
2
=
l
mid=\frac{2l+1}{2}=l
mid=22l+1=l。若 check(mid) 为真,则更新后的区间仍然为
[
l
,
r
]
[l,r]
[l,r],这就会导致无限循环。事实上,只需要取
m
i
d
=
l
+
r
+
1
2
mid=\frac{l+r+1}{2}
mid=2l+r+1,若 check(mid) 为真,则
m
i
d
=
r
mid=r
mid=r,更新后的区间为
[
r
,
r
]
[r,r]
[r,r],循环结束。若 check(mid) 为假,则更新后的区间为
[
l
,
l
]
[l,l]
[l,l],循环结束。
寻找右边界的二分查找模板:
int right_bound(int l, int r) {
while (l < r) {
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
类似1.1.1节中的分析,因为查找的是绿色区域的左边界,所以先定义一个函数 check(i),其中参数
i
i
i 是索引。当
i
i
i 位于绿色区域,即
4
≤
i
≤
7
4\leq i \leq 7
4≤i≤7 时,check(i) 为真;当
i
i
i 位于红色区域,即
0
≤
i
≤
3
0\leq i \leq 3
0≤i≤3 时,check(i) 为假。
初始时设置左右两个指针分别位于数组的左右两端,每次循环时计算
m
i
d
=
l
+
r
2
mid=\frac{l+r}{2}
mid=2l+r(至于
m
i
d
mid
mid 到底取多少稍后会说),然后判断 check(mid) 的值。如果 check(mid) 为真,说明
m
i
d
mid
mid 位于绿色区域,且
m
i
d
mid
mid 有可能就是左边界,因此接下来令
r
=
m
i
d
r=mid
r=mid 来缩小查找范围;如果 check(mid) 为假,说明
m
i
d
mid
mid 位于红色区域,且
m
i
d
mid
mid 必不可能是绿色区域的左边界,因为
m
i
d
mid
mid 最多是索引
3
3
3,因此令
l
=
m
i
d
+
1
l=mid+1
l=mid+1 来缩小查找范围。
接下来重点关注
m
i
d
mid
mid 到底该取多少。如果
m
i
d
=
l
+
r
2
mid=\frac{l+r}{2}
mid=2l+r,其中的除法代表整除,在某一轮循环出现了
r
−
l
=
1
r-l=1
r−l=1,则
m
i
d
=
2
l
+
1
2
=
l
mid=\frac{2l+1}{2}=l
mid=22l+1=l。若 check(mid) 为真,则更新后的区间为
[
l
,
l
]
[l,l]
[l,l],循环结束。若 check(mid) 为假,则更新后的区间为
[
r
,
r
]
[r,r]
[r,r],循环结束。综上所述,
m
i
d
mid
mid 取
l
+
r
2
\frac{l+r}{2}
2l+r 即可。
寻找左边界的二分查找模板:
int left_bound(int l, int r) {
while (l < r) {
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
原题链接:AcWing 789. 数的范围
以 a = [1, 3, 3, 3, 4] 为例,数字
3
3
3 的起始位置和终止位置分别是
1
1
1 和
3
3
3(索引)。如何利用1.1节中的模板来完成此题呢?
现对数组 a a a 作出划分,若令 C 1 : a [ i ] < x , C 2 : a [ i ] ≥ x C_1:a[i]<x,\; C_2:a[i]\geq x C1:a[i]<x,C2:a[i]≥x(注意必须保证 C 1 , C 2 C_1,C_2 C1,C2 互为对立),则求 x x x 的起始位置便转化成了求 C 2 C_2 C2 区域的左边界。若令 C 1 : a [ i ] ≤ x , C 2 : a [ i ] > x C_1:a[i]\leq x,\; C_2:a[i]> x C1:a[i]≤x,C2:a[i]>x,则求 x x x 的终止位置便转化成了求 C 1 C_1 C1 区域的右边界。
在求
C
2
C_2
C2 区域的左边界时,check(mid) 即为 a[mid] >= x。在求
C
1
C_1
C1 区域的右边界时,check(mid) 即为 a[mid] <= x。
AC代码如下:
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N];
int left_bound(int l, int r, int x) {
while (l < r) {
int mid = l + r >> 1;
if (a[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
}
int right_bound(int l, int r, int x) {
while (l < r) {
int mid = l + r + 1 >> 1;
if (a[mid] <= x) l = mid;
else r = mid - 1;
}
return l;
}
int main() {
int n, q;
cin >> n >> q;
for (int i = 0; i < n; i++) cin >> a[i];
while (q--) {
int k;
cin >> k;
int begin = left_bound(0, n - 1, k);
if (a[begin] != k) cout << "-1 -1" << endl;
else cout << begin << " " << right_bound(0, n - 1, k) << endl;
}
return 0;
}
相比整数二分,浮点数二分就要简单许多了,因为浮点数二分不涉及到边界问题。
浮点数二分通常用来求某个数
x
x
x 的近似值(
x
x
x 不易直接求得,例如
x
=
2
x=\sqrt{2}
x=2 等)。由于此时左右两个指针也均为浮点数,所以我们不能直接判断 l == r,而是判断 r - l 是否小于预先设定的精度。
模板如下:
double fbsearch(double l, double r, double eps) {
while (r - l > eps) {
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
return l;
}
一些注意事项:
check(mid) 为真,否则为假。原题链接:AcWing 790. 数的三次方根
注意到当 ∣ x ∣ < 1 |x|<1 ∣x∣<1 时,有 ∣ x 1 / 3 ∣ > ∣ x ∣ |x^{1/3}|>|x| ∣x1/3∣>∣x∣,故选取 l , r l,r l,r 时一定要谨慎。
因为 1000 0 1 / 3 < 22 10000^{1/3}<22 100001/3<22,所以这里取 l = − 22 , r = 22 l=-22,\,r=22 l=−22,r=22 即可。
#include <iostream>
using namespace std;
double x;
double fbsearch(double l, double r, double eps) {
while (r - l > eps) {
double mid = (l + r) / 2;
if (mid * mid * mid >= x) r = mid;
else l = mid;
}
return l;
}
int main() {
cin >> x;
printf("%lf", fbsearch(-22, 22, 1e-8));
return 0;
}
template< class ForwardIt, class T >
bool binary_search( ForwardIt first, ForwardIt last, const T& value );
该函数用来检查 [first, last) 区间内(该区间已排序)是否有数字等于 value,如果有返回 true,否则返回 false。
template< class ForwardIt, class T >
ForwardIt lower_bound( ForwardIt first, ForwardIt last, const T& value );
该函数用来返回 [first, last) 区间内(该区间已排序)首个大于等于 value 的元素的迭代器,如果找不到这种元素则返回 last。
template< class ForwardIt, class T >
ForwardIt upper_bound( ForwardIt first, ForwardIt last, const T& value );
该函数用来返回 [first, last) 区间内(该区间已排序)首个大于 value 的元素的迭代器,如果找不到这种元素则返回 last。
template< class ForwardIt, class T >
std::pair<ForwardIt, ForwardIt>
equal_range( ForwardIt first, ForwardIt last, const T& value );
该函数用来返回 [first, last) 区间内(该区间已排序)所有等于 value 的元素的「范围」。
「范围」实际上是由两个迭代器构成的 pair。pair 中的第一个元素是 std::lower_bound 的返回值,pair 中的第二个元素是 std::upper_bound 的返回值。
接下来我们用STL来简化1.2节中的代码。
注意到对于数组而言,其迭代器就是指针,因此我们可以通过将返回的迭代器与数组名作差来得到迭代器所指向的元素的下标。
简化后的代码如下:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int a[N];
int main() {
int n, q;
cin >> n >> q;
for (int i = 0; i < n; i++) cin >> a[i];
while (q--) {
int k;
cin >> k;
auto p = equal_range(a, a + n, k);
if (*p.first != k) cout << "-1 -1" << endl;
else cout << p.first - a << " " << p.second - a - 1 << endl;
}
return 0;
}
[1] https://www.acwing.com/activity/content/punch_the_clock/11/
[2] https://www.acwing.com/blog/content/31/
[3] https://zh.cppreference.com/w/cpp/algorithm/lower_bound
设置:狂欢ruby1.9.2高线(1.6.13)描述:我已经相当习惯在其他一些项目中使用highline,但已经有几个月没有使用它了。现在,在Ruby1.9.2上全新安装时,它似乎不允许在同一行回答提示。所以以前我会看到类似的东西:require"highline/import"ask"Whatisyourfavoritecolor?"并得到:Whatisyourfavoritecolor?|现在我看到类似的东西:Whatisyourfavoritecolor?|竖线(|)符号是我的终端光标。知道为什么会发生这种变化吗? 最佳答案
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我遇到了一个非常奇怪的问题,我很难解决。在我看来,我有一个与data-remote="true"和data-method="delete"的链接。当我单击该链接时,我可以看到对我的Rails服务器的DELETE请求。返回的JS代码会更改此链接的属性,其中包括href和data-method。再次单击此链接后,我的服务器收到了对新href的请求,但使用的是旧的data-method,即使我已将其从DELETE到POST(它仍然发送一个DELETE请求)。但是,如果我刷新页面,HTML与"new"HTML相同(随返回的JS发生变化),但它实际上发送了正确的请求类型。这就是这个问题令我困惑的
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
我有可变数量的表格和可变数量的行,我想让它们一个接一个地显示,但如果表格不适合当前页面,请将其放在下一页,然后继续。我已将表格放入事务中,以便我可以回滚然后打印它(如果高度适合当前页面),但我如何获得表格高度?我现在有这段代码pdf.transactiondopdf.table@data,:font_size=>12,:border_style=>:grid,:horizontal_padding=>10,:vertical_padding=>3,:border_width=>2,:position=>:left,:row_colors=>["FFFFFF","DDDDDD"]pdf.
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo
我有以下数组:arr=[1,3,2,5,2,4,2,2,4,4,2,2,4,2,1,5]我想要一个包含前三个奇数元素的数组。我知道我可以做到:arr.select(&:odd?).take(3)但我想避免遍历整个数组,而是在找到第三个匹配项后返回。我想出了以下解决方案,我相信它可以满足我的要求:my_arr.each_with_object([])do|el,memo|memo但是有没有更简单/惯用的方法来做到这一点? 最佳答案 使用lazyenumerator与Enumerable#lazy:arr.lazy.select(&:o