目录
生产者的同步发送消息

生产者发送消息到我们的topic分区上,需要等待我们kafka返回的ack,如果没有返回就会进入3s的阻塞,retry3次——>抛出异常(这里面我们可以将信息记录到文件日志中)
(43条消息) NIO学习_Fairy要carry的博客-CSDN博客
package com.wyh.kafka_demo.kafka;
import com.alibaba.fastjson.JSON;
import com.wyh.kafka_demo.pojo.Order;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutionException;
public class SimpleProducer {
/**
* 1.创建主题
*/
private final static String TOPIC_NAME = "jqTopic5";
public static void main(String[] args) throws ExecutionException, InterruptedException {
/**
* 2.kafka的broker
*/
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "82.157.198.247:9092,82.157.198.247:9093");
/**
* 2.1序列化:Key+value
*/
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/**
* 封装到发消息的客户端中
*/
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
/**
* 3.模拟发送五条消息
*/
int maxNum = 5;
/**
* 3.1创建消息
* hash(key)%partition
* ProducerRecord:消息记录
* key:消息标识key,帮助告诉发送到哪个分许通过hash计算
* value:json数据,消息内容
*/
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, 0,"TestKey", "hello,kafka");
/**
* 3.2通过异步的形式发送消息
*/
RecordMetadata recordMetadata = producer.send(producerRecord).get();
System.out.println("同步方式得到的消息:" + "topic-" + recordMetadata.topic()
+ "|partition-" + recordMetadata.partition()
+ "|offset-" + recordMetadata.offset());
}
}
异步发送
我们可以利用异步回调,生产者不管你消费者有没有消费发送完就往下执行自己的了;当我们拿到数据后通过回调机制异步返回(比如zk的watch机制就是这样)
(43条消息) Zookeeper_Fairy要carry的博客-CSDN博客
优点:速度较快,像银行转账业务异步就毕竟好,反馈较快
缺点:可能会出现消息丢失的情况,例如我们rabbitmq可以利用spring的retry机制解决,另外分布式事务也是需要解决的
(43条消息) RabbitMQ的高级特性(消息可靠性)_Fairy要carry的博客-CSDN博客
(43条消息) MQ-消息延迟_Fairy要carry的博客-CSDN博客_mq 延迟消息
像消息堆积我们kafka不需要考虑这方面,消息放在硬盘中
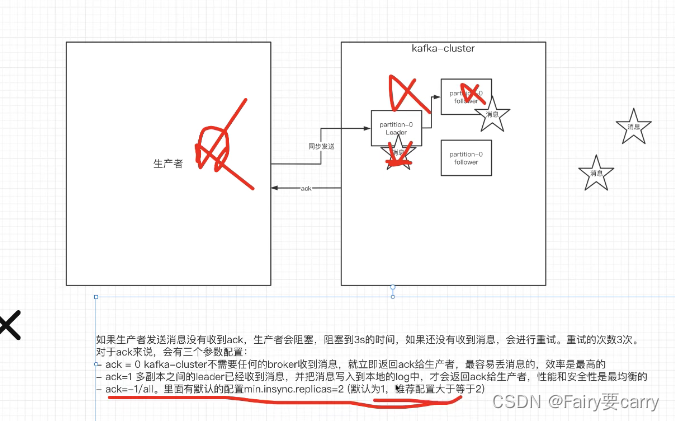
生产端ack的配置
1.两个broker上创建2个分区配上两个副本
bin/kafka-topics.sh --bootstrap-server xxxx:9092,xxxx:9093 --create --partitions 2 --replication-factor 2 --topic jqTopic5
2.生产者配置
bin/kafka-console-producer.sh --broker-list xxxx:9092,xxxx:9093 --topic jqTopic5同步发送的前提,生产者在获取ack前会一直阻塞:三种ack
ack=0:生产者只需要把消息给到broker,而不需要到partition中kafka就会把ack返回给生产者,速度较快容易丢消息
ack=1:多副本都接收到消息(leader进行同步),并且将消息传到log中kafka就返回ack
ack=all:leader和follower同步完后才会将ack返回
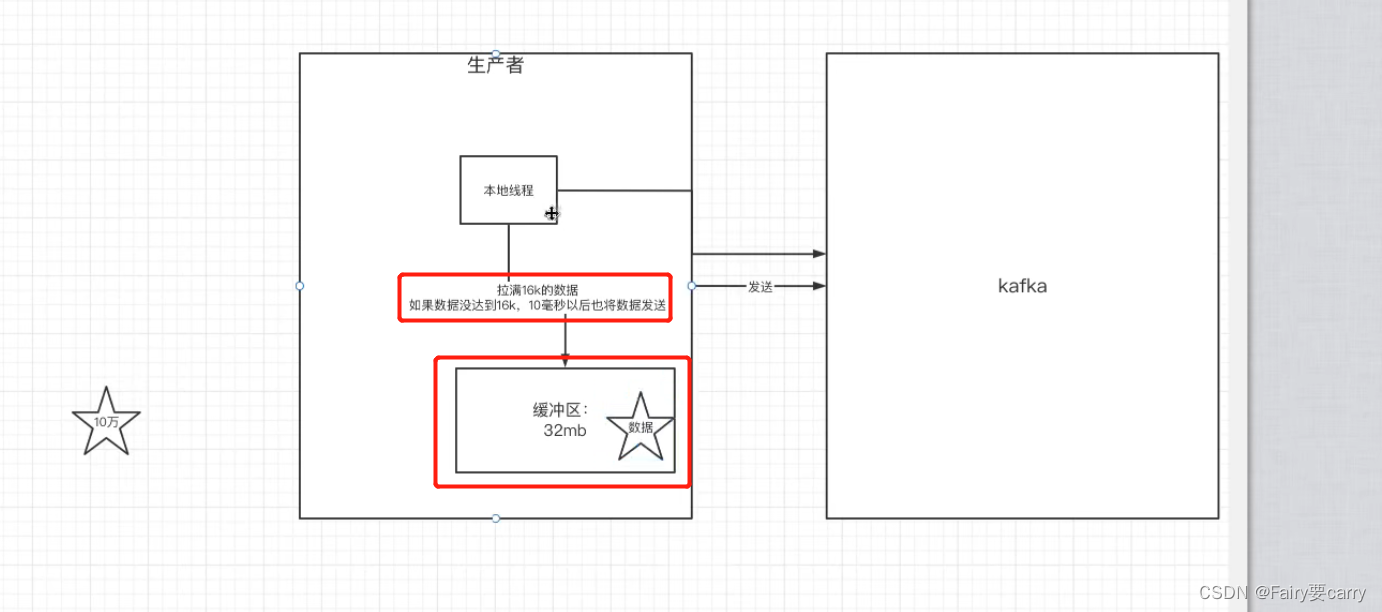
发送消息缓冲机制
生产者并不是直接把消息推送给kafka的——>利用了消息缓冲的机制,kafka本地线程默认会创建一个缓冲区 ,用来存放发送的数据(先放到缓冲区,当到达16k就进行发送)
如果没有满足16k,就等待10ms再发送消息
/**
* 2.kafka的broker
*/
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"82.157.198.247:9092,82.157.198.247:9093");
/**
* 2.1发送消息持久化机制参数ack
* 生产者会等3s,然后重试3次
*/
properties.put(ProducerConfig.ACKS_CONFIG,"1");
/**
* 2.12重试间隔的设置
* 默认间隔为100ms,次数为3次
*/
properties.put(ProducerConfig.RETRIES_CONFIG,3);
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,300);
/**
* 2.2设置消息的缓冲区
* 消息先放到缓冲区,如果到16k就发送,未满足则进行等待10ms再发送
*/
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
/**
* 2.3序列化:Key+value
*/
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/**
* 封装到发消息的客户端中
*/
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);生产者消费者实例
生产者代码
package com.wyh.kafka_demo.kafka;
import com.alibaba.fastjson.JSON;
import com.wyh.kafka_demo.pojo.Order;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class MyProducer {
/**
* 1.创建主题
*/
private final static String TOPIC_NAME="jqTopic5";
public static void main(String[] args) throws InterruptedException {
/**
* 2.kafka的broker
*/
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"82.157.198.247:9092,82.157.198.247:9093");
/**
* 2.1发送消息持久化机制参数ack
* 生产者会等3s,然后重试3次
*/
properties.put(ProducerConfig.ACKS_CONFIG,"1");
/**
* 2.12重试间隔的设置
* 默认间隔为100ms,次数为3次
*/
properties.put(ProducerConfig.RETRIES_CONFIG,3);
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,300);
/**
* 2.2设置消息的缓冲区
* 消息先放到缓冲区,如果到16k就发送,未满足则进行等待10ms再发送
*/
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
/**
* 2.3序列化:Key+value
*/
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/**
* 封装到发消息的客户端中
*/
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
/**
* 3.模拟发送五条消息
*/
int maxNum=5;
final CountDownLatch countDownLatch = new CountDownLatch(maxNum);
for (int i = 1; i <= 5; i++) {
Order order = new Order((long) i, i);
/**
* 3.1消息记录发送给指定的分区
* hash(key)%partition
* ProducerRecord:消息记录
* key:消息标识key,帮助告诉发送到哪个分许通过hash计算
* value:json数据,消息内容
*/
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, order.getOrderId().toString(), JSON.toJSONString(order));
/**
* 3.2通过异步的形式发送消息
*/
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e!=null){
System.err.println("发送消息失败:"+e.getStackTrace());
}
if(recordMetadata!=null){
System.out.println("异步发送的消息为:"+"topic-"+recordMetadata.topic()
+"|partition-"+recordMetadata.partition()
+"|offset-"+recordMetadata.offset());
}
countDownLatch.countDown();
}
});
}
/**
* 4.主线程等待countDownlatch
*/
countDownLatch.await(5, TimeUnit.SECONDS);
producer.close();
}
}
消费者代码:

package com.wyh.kafka_demo.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MyConsumer {
private final static String TOPIC_NAME="jqTopic5";
private final static String CONSUMER_GROUP_NAME="testGroup";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"82.157.198.247:9092,82.157.198.247:9093");
/**
* 1.消费分组名
*/
properties.put(ConsumerConfig.GROUP_ID_CONFIG,CONSUMER_GROUP_NAME);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"0");
/**
* 1.2设置序列化
*/
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
/**
* 2.创建一个消费者的客户端
*/
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
/**
* 3.消费者订阅主题列表
*/
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到的消息:partition= %d,offset= %d,key= %s,value=%s %n",record.partition(),
record.offset(),record.key(),record.value());
}
}
}
}
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除