Redis 高可用架构之哨兵模式 - Sentinel
上一篇文章,已经介绍了 Redis 主从架构:Redis 主从复制 + 读写分离。为Redis 配置主从模式,可以大幅度提高 Redis 的可用性,减少甚至避免 Redis 服务发生宕机的可能。
Redis 主从模式有以下作用:
故障隔离和恢复:无论主节点或者从节点宕机,其他节点依然可以保证服务的正常运行,并可以手动切换主从。
读写隔离:Master 节点提供写服务,Slave 节点提供读服务,分摊流量压力,均衡流量的负载。
提供高可用保障:主从模式是高可用的最基础版本,也是哨兵模式和 cluster模式实施的前置条件。
尽管 Redis 主从模式已经做的足够多了,但其还是存在不小的问题。我们先来学习一个专业名词:平均修复时间(Mean time to repair,MTTR),它是衡量系统可用性的关键指标:我们计算一下,从监控到 Redis 故障到手动切换主从止损,再到 Redis 服务恢复正常,这期间可能是一个较长的过程,这在生产环境(甚至是超高并发的大型交易系统)就是一个灾难,其带来的损失也是无法估计的。
所以我们需要系统自动的感知到 Master 故障,并选择一个 Slave 切换为 Master,实现故障自动转移的能力。

bind 0.0.0.0
# Master 端口
port 6379
# 后台执行
daemonize yes
requirepass "123456"
logfile "/usr/local/redis/log/redis1.log"
dbfilename "pointer1.rdb"
dir "/usr/local/redis/data"
appendonly yes
appendfilename "appendonly1.aof"
masterauth "123456"
主要在于端口号不同,分别是 6380、6381。
bind 0.0.0.0
# Master 端口
port 6380
# 后台执行
daemonize yes
requirepass "123456"
logfile "/usr/local/redis/log/redis2.log"
dbfilename "pointer2.rdb"
dir "/usr/local/redis/data"
appendonly yes
appendfilename "appendonly2.aof"
# 从本机 6379 的 redis 实例复制数据,Redis 5.0 之前使用 slaveof
replicaof 192.169.0.1 6379
# 从节点开启只读模式(默认)
replica‐read‐only yes
# 从节点访问主节点的密码,和 requirepass ⼀样
masterauth "123456"
./redis-6.2.4/src/redis-server redis-6379/redis.conf
./redis-6.2.4/src/redis-server redis-6380/redis.conf
./redis-6.2.4/src/redis-server redis-6381/redis.conf
将哨兵配置文件分别复制到 sentinel26379 sentinel26380 sentinel26381,需要注意的是每个文件的端口配置以及 sentinel monitor mymaster 192.169.0.1 6379 2 中最后的数字 2,哨兵集群汇总每个节点必须一致。
# 绑定IP
bind 0.0.0.0
# 后台运行
daemonize yes
# 默认yes,没指定密码或者指定IP的情况下,外网无法访问
protected-mode no
# 哨兵的端口,客户端通过这个端口来发现redis
port 26379
# 这个文件会自动生成(如果同一台服务器上启动,注意要修改为不同的端口)
pidfile /var/run/redis-sentinel-26379.pid
# sentinel 监控的 master 的名字叫做 mymaster,初始地址为 127.0.0.1 6379,2代表两个及以上哨兵认定为故障,才认为是真的故障
sentinel monitor mymaster 192.169.0.1 6379 2
./redis-6.2.4/src/redis-sentinel sentinel26379/sentinel.conf
./redis-6.2.4/src/redis-sentinel sentinel26380/sentinel.conf
./redis-6.2.4/src/redis-sentinel sentinel26381/sentinel.conf
redis-cli -h 192.168.0.1 -p 26379
sentinel master mymaster
SENTINEL replicas mymaster
SENTINEL sentinels mymaster
redis-cli -p 6379 DEBUG sleep 30
SENTINEL get-master-addr-by-name mymaster
哨兵是 Redis 的⼀种运⾏模式,它专注于对 Redis 实例(主节点、从节点)运⾏状态的监控,并能够在主节点发⽣故障时通过⼀系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可⽤性。
Redis提供了哨兵的命令,是⼀个独⽴的进程;
哨兵通过发送命令给多个节点,等待 Redis 服务器响应,从⽽监控运⾏的多个 Redis 实例的运⾏情况;
当哨兵监测到 Master 宕机,会⾃动将 Slave 切换成 Master,通过通知其他的从服务器,修改配置⽂件切换主机。
Redis Sentinel 在不使用 Redis 集群时为 Redis 提供高可用性。结合 官方文档 - Redis Sentinel,可以知道 Redis 哨兵具备的能⼒有如下⼏个:
监控:Sentinel 会持续监测 master、slave 是否处于预期工作状态;
自动故障转移:当 Master 运⾏故障,哨兵启动⾃动故障恢复流程:从 slave 中选择⼀台作为新 master;
通知:让 slave 执⾏ replicaof ,与新的 master 同步;并且通知客户端与新 master 建⽴连接;
配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵模式启用的时候,会同步启用 sentinel 的进程。sentinel 进程会向所有的 master 和 slaves 以及其他 sentinel进程 发送1s一次 PING 命令(心跳包)。
如果 slave 没有在规定的时间内响应 sentinel 的 PING 命令 , sentinel 会认为该实例已经挂了,将它记录为:「下线状态」;
同理,如果 master 没有在规定时间响应 sentinel 的 PING 命令,也会被判定为 offline 状态,开始执行 「自动切换 master 」 的流程。
但是还是可能存在因为网络拥塞、master实例假死、请求延迟等导致实例在某个短暂时间段不可用,后续又快速恢复了。如果这时候被我们主动下线了,其实整个系统的可用性反而遭到了退化;而且误判之后的一系列操作,master竞选、消息通知,slave 与新 master 同步数据,都会消耗大量资源。
为了保证判断的可靠性,Redis 对下线的标识做了区分:一种是主观下线,一种是客观下线。
哨兵利用 PING 命令来监测 master、 slave 实例节点的生命状态。如果是无效回复,哨兵就把这个实例节点标记为 「主观下线」。如果是 slave,一般是一主多从,直接下线即可;但如果是 master,就要小心了:一个 sentinel 实例很容易造成误判,那就可以多个 sentinel 实例一起投票判断。
哨兵机制就是这样的,采用多个实例组成 sentinel 集群模式进行部署,即哨兵集群。多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
master 是否要下线不能是单个 sentinel 实例来决定,上面说了一般会有多个 sentinel 实例(即sentinel集群)。只有当 sentinel 集群里的实例过半判断 master 已经 「主观下线」 了,这时候我们就把 master 标记为 「客观下线」。
当 master 被判定为客观下线后,才会进⼀步触发哨兵执行主从切换流程。

主观下线是 sentinel 实例自己认为节点 offline,这时候节点并不是真正的下线;而客观下线是达到一定数量的 sentinel 实例(比如超过一半)都认为节点 offline 了,这时候会进一步触发离线、重新竞选主等一系列操作。
这里的「一定数量」是一个法定数量(Quorum),是由哨兵监控配置决定的:
# sentinel monitor <master-name> <master-host> <master-port> <quorum>
# 举例如下:
sentinel monitor mymaster 192.168.0.1 6379 2
sentinel monitor:代表监控。
mymaster:代表主节点的名称,可以自定义。
192.168.0.1:代表监控的主节点 ip,6379 代表端口。
2:法定数量,代表只有两个或两个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
客观下线的标准就是,当有 N 个哨兵实例时,要有 N/2 + 1 个实例判断 master 为 主观下线 ,才能最终判定 master 为 客观下线 ,其实就是过半机制。
sentinel 的一个很重要工作,就是从多个 slave 中选举出一个新的 master。当然,这个选举的过程会比较严谨,需要通过筛选 + 综合评估方式进行选举。
过滤掉不健康的(下线或者断线),没有回复哨兵 PING 命令的从节点。
评估实例过往的网络连接状况 down-after-milliseconds,如果一定周期内(如24h)从库和主库经常断连,而且超出了一定的阈值(如 10 次),则该 slave 不予考虑。
这样,就保留下比较健康的实例了。
筛选掉不健康的实例之后,我们就可以对于剩下健康的实例按顺序进行综合评估了。
slave 优先级:通过 slave-priority 配置项(redis.conf),可以给不同的从库设置不同优先级,优先级高的优先成为 master。
选择数据偏移量差距最小的:即 slave_repl_offset 与 master_repl_offset 进度差距,其实就是比较 slave 与原 master 复制进度差距。
slave runID:在优先级和复制进度都相同的情况下,选用 runID 最小的,runID 越小说明创建时间越早,优先选为 master。先来后到原则。
等这几个条件都评估完,我们就会选择出最适合 slave,把他推举为新的 master。

推选出最新的 master 之后,后续所有的写操作都会进入这个 master 中。所以需要尽快通知到所有的 slave,让他们重新 replacaof 到 master 上,重新建立 runID 和 slave_repl_offset ,来保证数据的正常传输和主从一致性。如下图所示:

集群中的哨兵如何实现通信?
哨兵之间可以相互通信,主要归功于 Redis 的 pub/sub 发布/订阅机制`。哨兵与 master 建立通信之后,可以利用 master 提供发布/订阅机制发布自己的 ip、port 等信息
master 有一个 sentinel:hello 的专用通道,用于哨兵之间发布和订阅消息。哨兵们都可以通过该通道发布自己的 name、ip、port 消息,同时订阅其他哨兵发布的 name、ip、port 消息。互相发现之后建立起了连接,后续的消息通信就可以直接进行了。
这个与微服务中的服务注册与发现,以及RPC通信类似的整套做法类似。

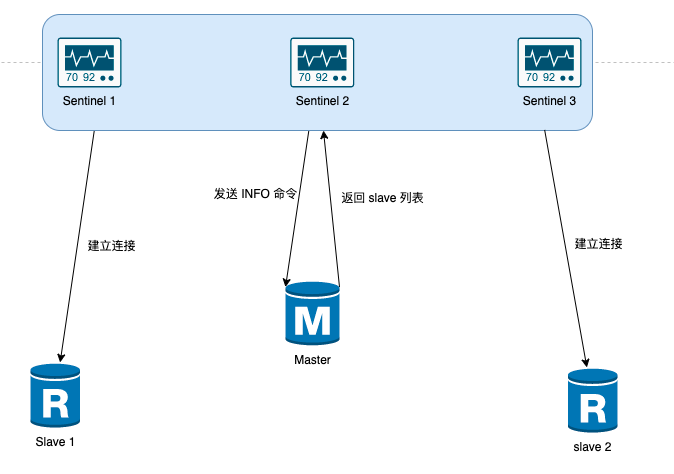
哨兵如何与 slave 实现连接?
sentinel 向 master 发送 INFO 命令
master 返回与之关联的 slave 列表
sentinel 根据 master 返回的 slave 列表,逐个与 salve 建立连接,并且根据这个连接持续监控
哨兵如何与客户端进行事件通知?
通过 pub/sub 机制,发布不同事件,让客户端在这里订阅消息。客户端可以订阅哨兵的消息,哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
Redis Sentinel 在不使用 Redis 集群时为 Redis 提供高可用性。主从架构集群的数据同步,是数据可靠性的基础保障;主库宕机,自动执行主从切换是服务不间断的关键支撑。
监控 master 与 slave 运行状态,判断是否客观下线;
master 客观下线后,选择一个 slave 切换成 master;
通知 slave 和客户端新 master 信息。
为了避免单个哨兵故障后无法进行主从切换,以及为了减少误判率,又引入了哨兵集群;哨兵集群又需要有一些机制来支撑它的正常运行:
基于 pub/sub 机制实现哨兵集群之间的通信;
基于 INFO 命令获取 slave 列表,帮助哨兵与 slave 建立连接;
通过哨兵的 pub/sub,实现了与客户端和哨兵之间的事件通知。
主从切换,并不是随意选择一个哨兵就可以执行,而是通过投票选举,选择一个 master,由这个 master 负责主从切换。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo