目录
Cluster 集群:
一个 Elasticsearch 集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为
标识。
Node节点:
一个 Elasticsearch 实例即一个 Node,一台机器可以有多个实例,正常使用下每个实例应该
会部署在不同的机器上。Elasticsearch 的配置⽂件中可以通过 node.master、node.data 来
设置节点类型。
node.master:表示节点是否具有成为主节点的资格
true代表的是有资格竞选主节点
false代表的是没有资格竞选主节点
node.data:表示节点是否存储数据
Node节点组合:
主节点+数据节点(master+data)
节点即有成为主节点的资格,又存储数据
node.master: true
node.data: true
数据节点(data):
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
node.master: false
node.data: false
分片:
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片( primary
shard)和复制分片(replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复
制分片,一个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个
节点上。
步骤:
拷贝elasticsearch-7.2.0安装包3份,分别命名elasticsearch-7.2.0-a, elasticsearch-7.2.0-b,
elasticsearch-7.2.0-c。
分别修改elasticsearch.yml文件。groupadd esgroup #只需要执行一次
useradd esuser -g esgroup #只需要执行一次
chown -R esuser:esgroup /usr/local/software/elasticsearch-7.2.0-a #三个目录都需要执行
su esuser 再分别进入bin文件夹下启动a,b,c三个节点
打开浏览器输入:http://localhost:9200/_cat/health?v ,如果返回的node.total是3,代表集
群搭建成功
a节点配置更改:
#集群名称
cluster.name: my-application
#节点名称
node.name: node-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#网关地址
network.host: 0.0.0.0
#端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
b节点更改:
#节点名称
node.name: node-2#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9400
c节点更改:
#节点名称
node.name: node-3#端口
http.port: 9202
#内部节点之间沟通端口
transport.tcp.port: 9500
kibana安装步骤
1.下载
https://www.elastic.co/cn/downloads/kibana
选择对应版本
2.启动
kibana-7.2.0-linux-x86_64.tar.gz 解压后,更改下配置文件
打开配置 kibana.yml,添加elasticsearch.hosts: ["http://localhost:9200","http://localhost:
9201","http://localhost:9202"]
sh ./kibana --allow-root
通过kibana查看
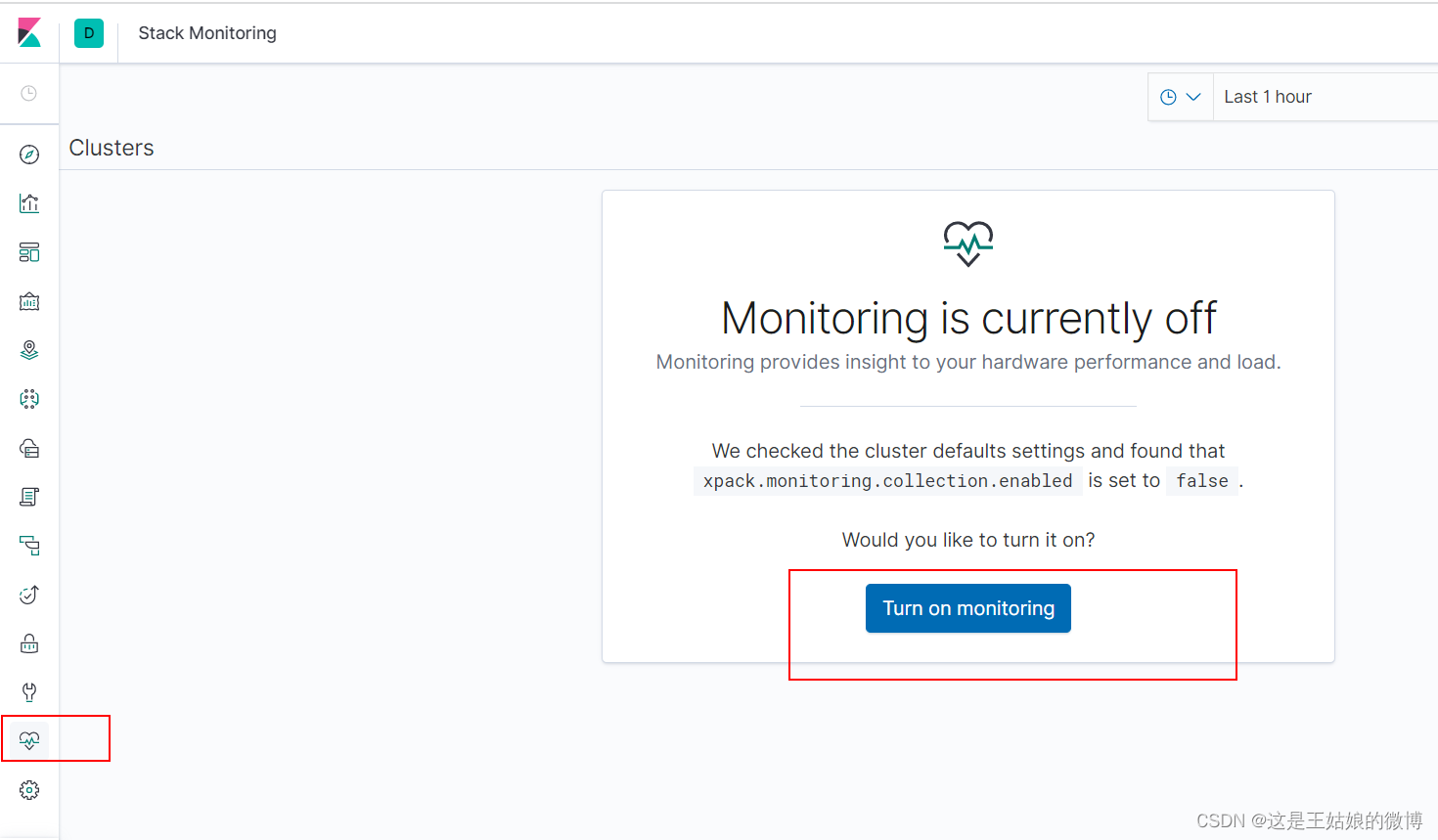
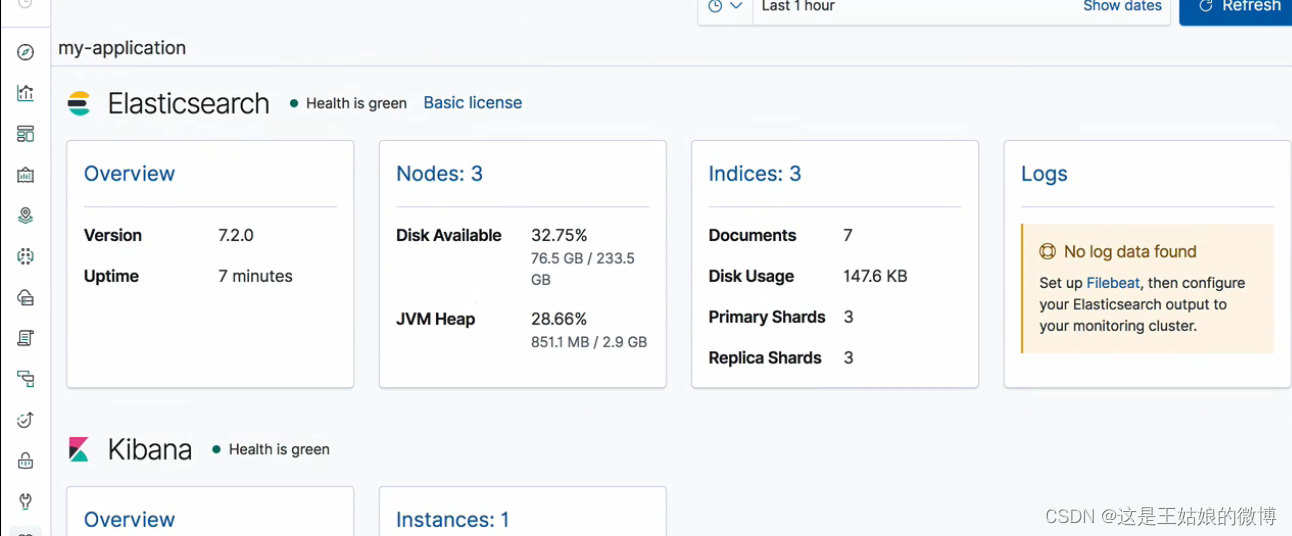
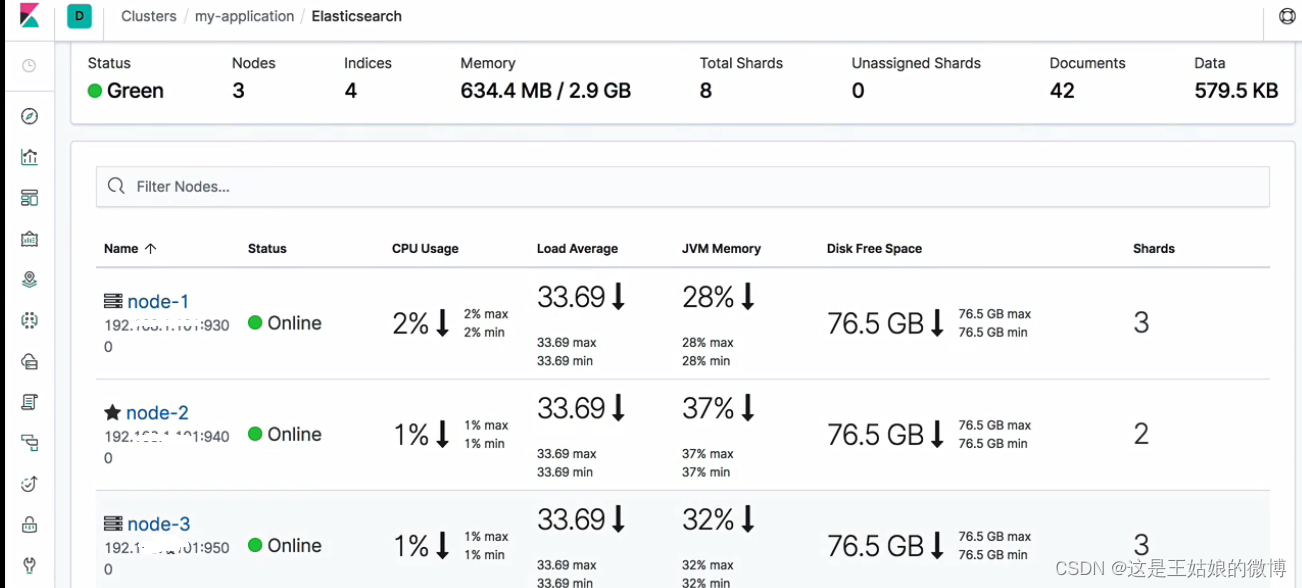
集群搭建成功~
分片(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 这些分布在
不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分
配, 所以用户基本上不用担心分片的处理细节。
副本(replica):ES默认为一个索引创建1个主分片, 并分别为其创建一个副本分片.
Elastic search7.x之后,如果不指定索引分片,默认会创建1个主分片和一个副分片,而7.x版
本之前的比如6.x版本,默认是5个主分片
创建索引,不指定分片
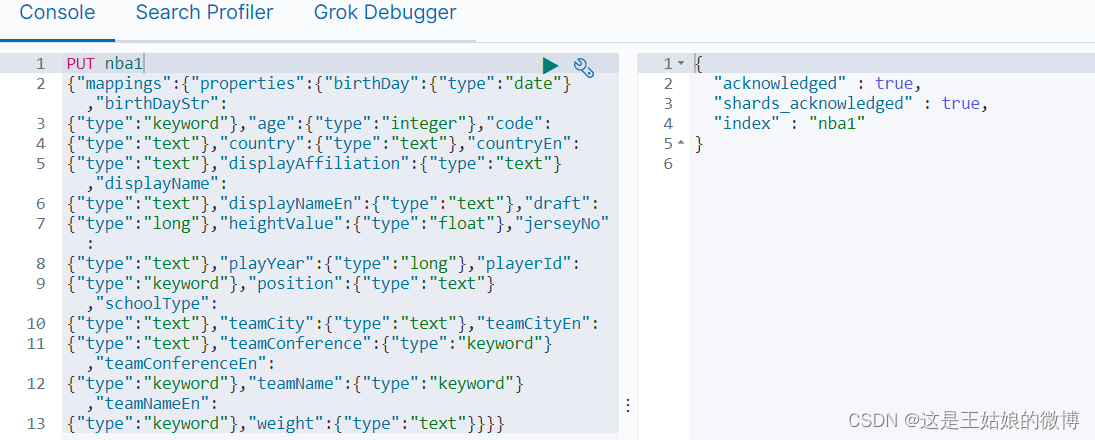
默认是一个分片
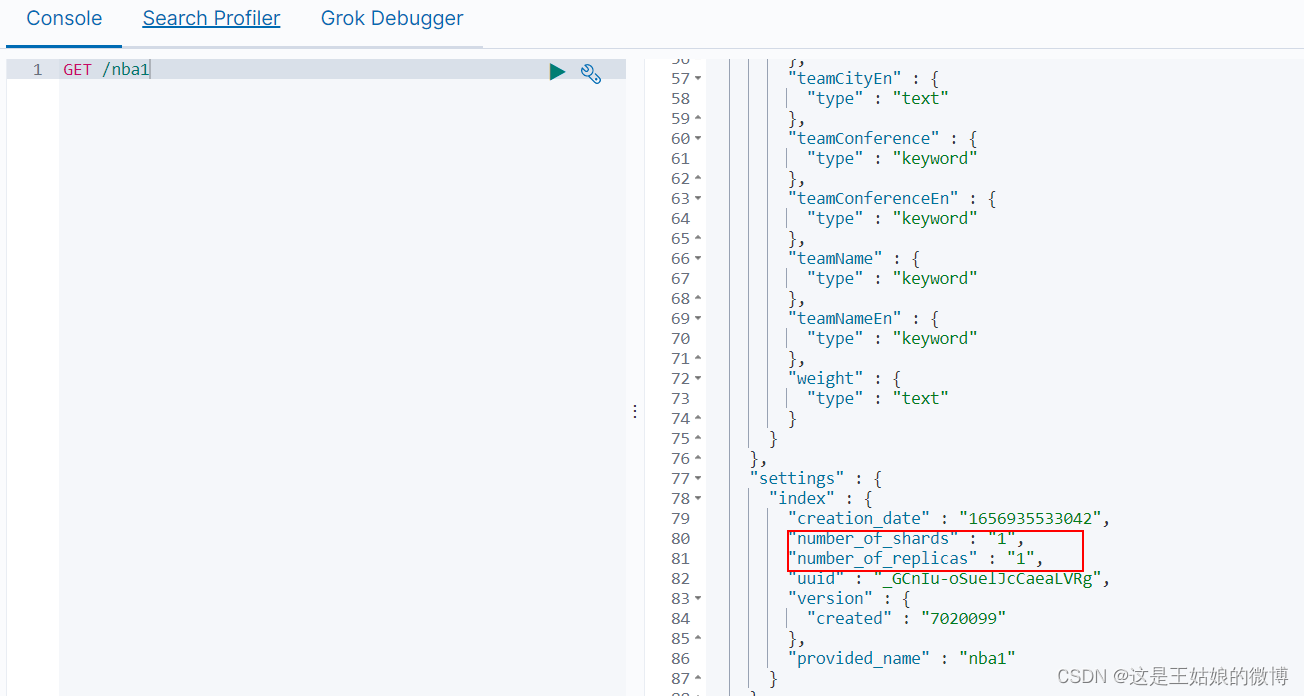
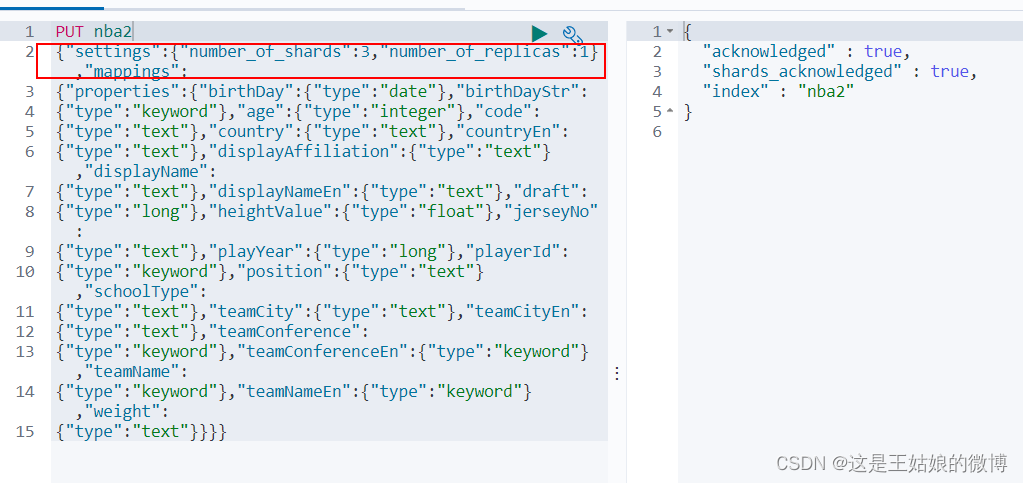
指定分区数量
"settings": { "number_of_shards": 3, "number_of_replicas": 1 },
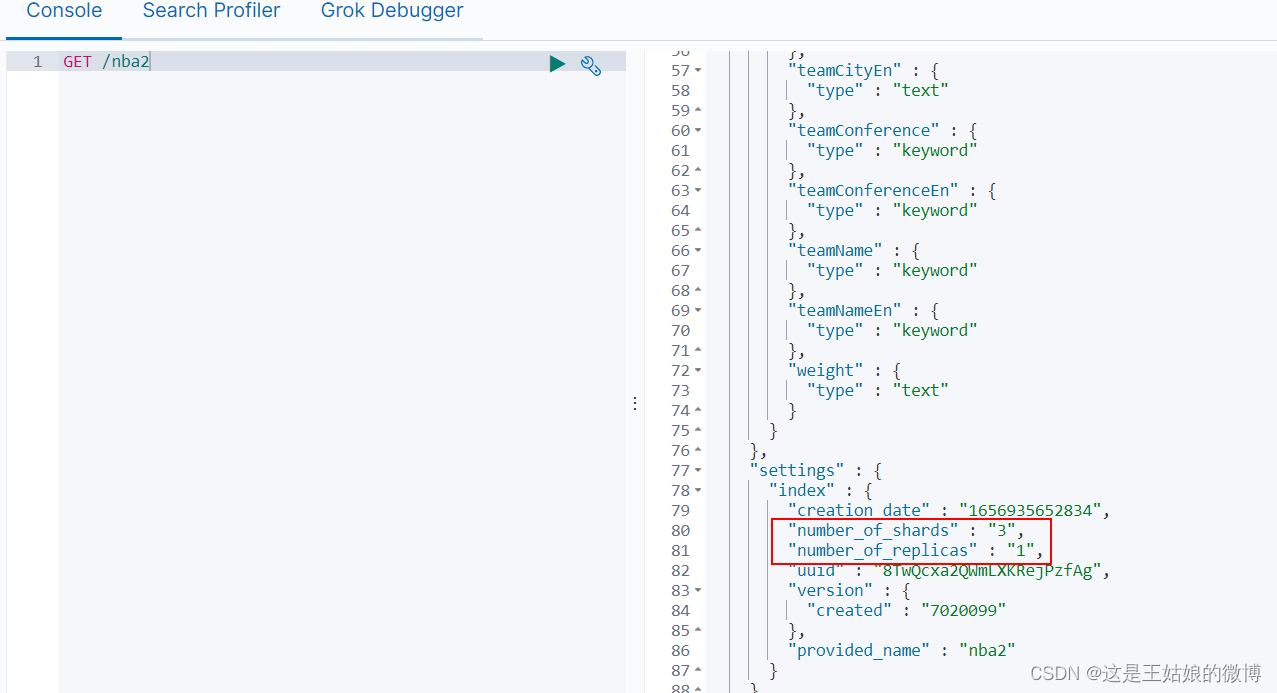
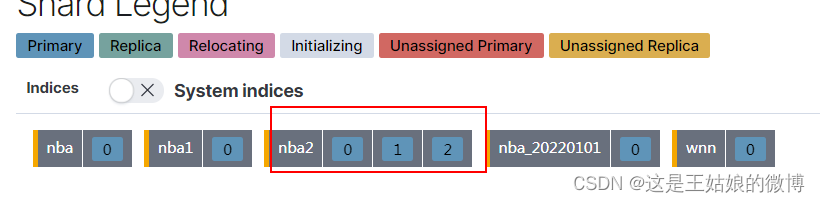
分片分配到哪个节点是由ES自动管理的,如果某个节点挂了,那分片会重新分配到别的节
点上。
在单机中,节点没有副分片,因为只有一个节点没必要生成副分片,一个节点挂点,副分片
也会挂掉,完全是单故障,没有存在的意义。
在集群中,同个分片它的主分片不会和它的副分片在同一个节点上,因为主分片和副分片在
同个节点,节点挂了,副分片和主分机一样是挂了,不要把所有的鸡蛋都放在同个篮子里。
可以手动移动分片,比如把某个分片移动从节点1移动到节点2。
创建索引时指定的主分片数以后是无法修改的,所以主分片数的数量要根据项目决定,如果
真的要增加主分片只能重建索引了。副分片数以后是可以修改的
移动之前
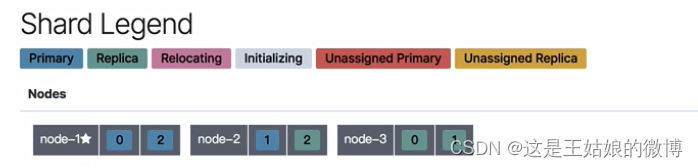
POST /_cluster/reroute { "commands": [ { "move": { "index": "nba", "shard": 2, "from_node": "node-1", "to_node": "node-3" } } ] }
把nba这个索引的第二个分片,从node-1服务中移动到node-2服务中
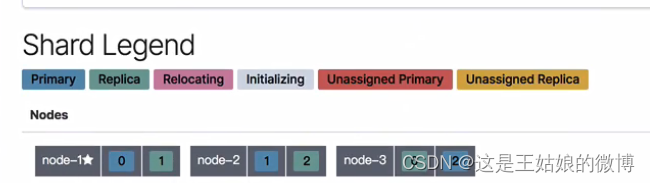
PUT /nba/_settings { "number_of_replicas": 2 }
更改之后,三个主分片 * 2 副本
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
我正在尝试为我的iOS应用程序设置cocoapods但是当我执行命令时:sudogemupdate--system我收到错误消息:当前已安装最新版本。中止。当我进入cocoapods的下一步时:sudogeminstallcocoapods我在MacOS10.8.5上遇到错误:ERROR:Errorinstallingcocoapods:cocoapods-trunkrequiresRubyversion>=2.0.0.我在MacOS10.9.4上尝试了同样的操作,但出现错误:ERROR:Couldnotfindavalidgem'cocoapods'(>=0),hereiswhy:U
我正在构建一个应用程序,想知道是否将未使用的对象设置为nil是生产级编码中的常见做法。我知道这只是垃圾收集器的提示,并不总是处理对象。 最佳答案 根据这个thread如果您使用完一个成员对象,将其设置为nil将引发被引用对象被垃圾回收。如果它是局部变量,方法exit将做同样的事情。也就是说,如果您要求将成员显式设置为nil,我会质疑您的设计。 关于ruby-将对象设置为nil是否很常见?,我们在StackOverflow上找到一个类似的问题: https://
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
使用Paperclip,我想从这样的URL抓取图像:require'open-uri'user.photo=open(url)问题是我最后得到一个像“open-uri20110915-4852-1o7k5uw”这样的文件名。有什么方法可以更改user.photo上的文件名?作为一个额外的变化,Paperclip将我的文件存储在S3上,所以如果我可以在初始分配中设置我想要的文件名就更好了,这样图像就会上传到正确的S3key。像这样:user.photo=open(url),:filename=>URI.parse(url).path 最佳答案