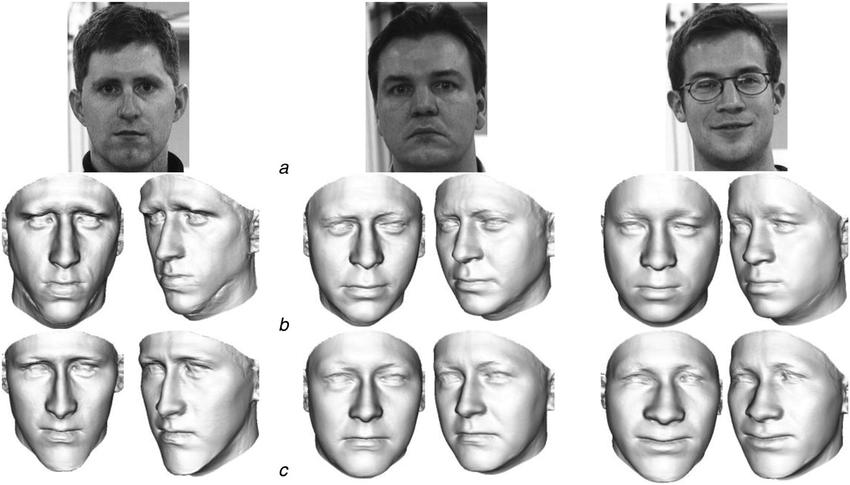
 典型的基于二维图像的三维人脸重建。图源:10.1049/iet-cvi.2013.0220传统三维重建大致可以分为光测度和几何方法,前者分析像素点的亮度变化,后者依靠视差完成重建。近年来又开始采用机器学习尤其是深度学习技术,在特征检测、深度估计等方面取得很好的效果。虽然当前一些方法利用空间几何模型与纹理贴图,在场景的外观还原度上与真实世界看起来几近相同。但应看到,这些方法仍存在一些局限,仅能还原场景外观特征,无法实现场景内光照、反射率和粗糙度等更深层次属性的数字化,对这些深层信息的查询和编辑更无从谈起了。这也导致无法将它们转化为渲染引擎可用的 PBR 渲染资产,也就不能生成真实感十足的渲染效果。如何解决这些问题呢?逆渲染技术逐渐进入了人们的视野。逆渲染任务最早是由老一辈计算机科学家 Barrow 和 Tenenbaum 于 1978 年提出,在三维重建的基础上,进一步恢复光照、反射率、粗糙度和金属度等场景内在属性,实现更具真实感的渲染。不过从图像中分解这些属性极其不稳定,不同的属性配置往往导致相似的外观。随着可微分渲染和隐式神经表示的进展,一些方法在具有显式或隐式先验的以物体为中心的小场景中取得了较好效果。然而大规模室内场景的逆渲染一直没能很好地解决,不仅难以在真实场景下恢复物理合理的材质,场景内多视角一致性也很难保证。在国内有这样一家深耕自主研发核心算法,专注三维重建领域大规模行业应用的技术公司 —— 如视(Realsee),针对大规模室内场景的逆渲染这一难啃的课题,开创性地提出了高效的多视角逆渲染框架。论文已被 CVPR 2023 会议接收。
典型的基于二维图像的三维人脸重建。图源:10.1049/iet-cvi.2013.0220传统三维重建大致可以分为光测度和几何方法,前者分析像素点的亮度变化,后者依靠视差完成重建。近年来又开始采用机器学习尤其是深度学习技术,在特征检测、深度估计等方面取得很好的效果。虽然当前一些方法利用空间几何模型与纹理贴图,在场景的外观还原度上与真实世界看起来几近相同。但应看到,这些方法仍存在一些局限,仅能还原场景外观特征,无法实现场景内光照、反射率和粗糙度等更深层次属性的数字化,对这些深层信息的查询和编辑更无从谈起了。这也导致无法将它们转化为渲染引擎可用的 PBR 渲染资产,也就不能生成真实感十足的渲染效果。如何解决这些问题呢?逆渲染技术逐渐进入了人们的视野。逆渲染任务最早是由老一辈计算机科学家 Barrow 和 Tenenbaum 于 1978 年提出,在三维重建的基础上,进一步恢复光照、反射率、粗糙度和金属度等场景内在属性,实现更具真实感的渲染。不过从图像中分解这些属性极其不稳定,不同的属性配置往往导致相似的外观。随着可微分渲染和隐式神经表示的进展,一些方法在具有显式或隐式先验的以物体为中心的小场景中取得了较好效果。然而大规模室内场景的逆渲染一直没能很好地解决,不仅难以在真实场景下恢复物理合理的材质,场景内多视角一致性也很难保证。在国内有这样一家深耕自主研发核心算法,专注三维重建领域大规模行业应用的技术公司 —— 如视(Realsee),针对大规模室内场景的逆渲染这一难啃的课题,开创性地提出了高效的多视角逆渲染框架。论文已被 CVPR 2023 会议接收。
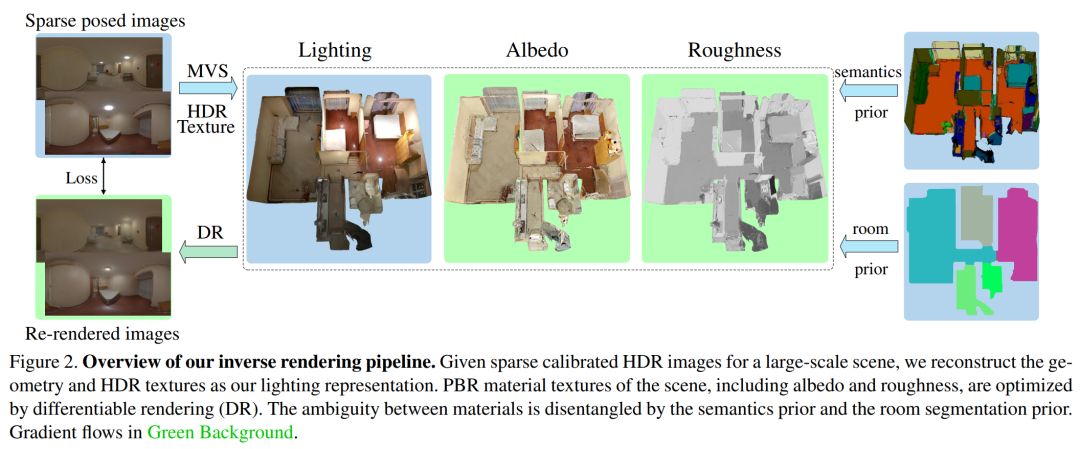 基于纹理的光照(TBL)在表示大规模室内场景的光照上,TBL 的优势分别表现在神经表示的紧凑性、IBL 全局光照以及参量光的可解释性和空间一致性。TBL 是对整个场景的全局表示,定义了所有表面点的射出辐照度。而一个表面点的射出辐照度通常等于 HDR 纹理的值,即输入的 HDR 图像中相应像素观察到的 HDR 辐照度。如视使用自研的高质量三维重建技术来重建整个大场景的网格模型。最终基于输入的 HDR 图像来重建 HDR 纹理,并通过 HDR 纹理从任意位置任意方向查询全局光照。下图 3(左)展示了 TBL 的可视化。
基于纹理的光照(TBL)在表示大规模室内场景的光照上,TBL 的优势分别表现在神经表示的紧凑性、IBL 全局光照以及参量光的可解释性和空间一致性。TBL 是对整个场景的全局表示,定义了所有表面点的射出辐照度。而一个表面点的射出辐照度通常等于 HDR 纹理的值,即输入的 HDR 图像中相应像素观察到的 HDR 辐照度。如视使用自研的高质量三维重建技术来重建整个大场景的网格模型。最终基于输入的 HDR 图像来重建 HDR 纹理,并通过 HDR 纹理从任意位置任意方向查询全局光照。下图 3(左)展示了 TBL 的可视化。 混合光照表示在实践中,直接利用 TBL 优化材质存在弊端,蒙特卡洛高采样数会导致很高的计算和内存成本。由于大多数噪声存在于漫反射分量,如视对漫反射分量表面点的辐照度进行预计算。因此可以高效地查询辐照度,取代了成本高昂的在线计算,如图 3(右)所示。基于 TBL 的渲染方程由公式 (1) 重新写为公式 (2)。
混合光照表示在实践中,直接利用 TBL 优化材质存在弊端,蒙特卡洛高采样数会导致很高的计算和内存成本。由于大多数噪声存在于漫反射分量,如视对漫反射分量表面点的辐照度进行预计算。因此可以高效地查询辐照度,取代了成本高昂的在线计算,如图 3(右)所示。基于 TBL 的渲染方程由公式 (1) 重新写为公式 (2)。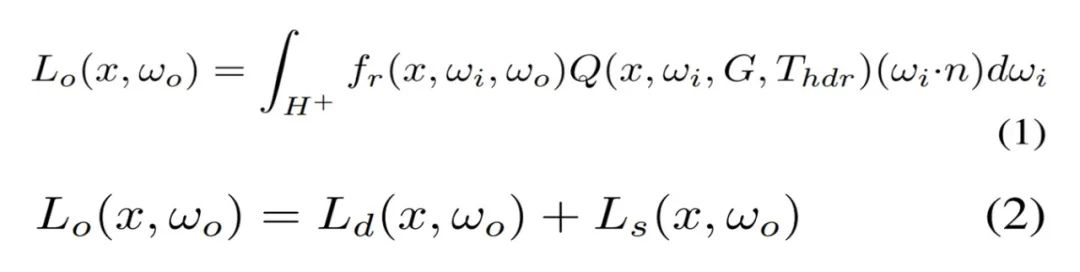 如视提出了两种表示来建模预计算辐照度。一种是神经辐照度场(NIrF),它是一个浅层多层感知器(MLP),以表面点作为输入并输出辐照度 p。另一种是辐照度纹理(IrT),它类似于计算机图形学中常用的光照贴图。可以看到,这种混合光照表示包含了用于漫反射分量的预计算辐照度和用于镜面反射分量的源 TBL,大大降低了渲染噪声,实现了材质的高效优化。公式 (2) 中的漫反射分量被建模为公式 (3) 所示。
如视提出了两种表示来建模预计算辐照度。一种是神经辐照度场(NIrF),它是一个浅层多层感知器(MLP),以表面点作为输入并输出辐照度 p。另一种是辐照度纹理(IrT),它类似于计算机图形学中常用的光照贴图。可以看到,这种混合光照表示包含了用于漫反射分量的预计算辐照度和用于镜面反射分量的源 TBL,大大降低了渲染噪声,实现了材质的高效优化。公式 (2) 中的漫反射分量被建模为公式 (3) 所示。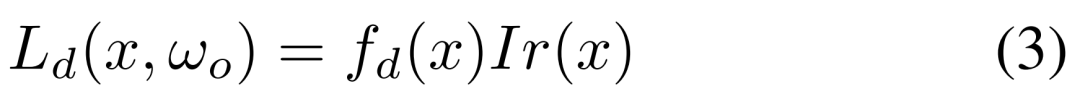 基于分割的三阶段式材质估计对于神经材质而言,很难用极其复杂的材质对大规模场景进行建模,并且不适配传统的图形引擎。如视选择直接优化几何的显式材质纹理,使用了以 SV 反照率和 SV 粗糙度作为参数的简化版 Disney BRDF 模型。不过由于观察的稀疏性,直接优化显式材质纹理导致不一致和未收敛的粗糙度。对此,如视利用语义和房间分割先验来解决这一问题,其中语义图像通过基于学习的模型预测,房间分割通过占用网格计算。在实现过程中,如视采取三阶段式策略。第一阶段基于 Lambertian 假设来优化稀疏反照率,而不像以物体为中心的小场景那样将反照率初始化为常数。虽然可以通过公式 (3) 直接计算漫反射反照率,但在高光区域会使得反照过亮,导致下一阶段的粗糙度过高。因此,如视使用语义平滑约束在相同的语义分割上激发类似的反照率,如下公式 (4) 所示。稀疏的反照率通过公式 (5) 来优化。
基于分割的三阶段式材质估计对于神经材质而言,很难用极其复杂的材质对大规模场景进行建模,并且不适配传统的图形引擎。如视选择直接优化几何的显式材质纹理,使用了以 SV 反照率和 SV 粗糙度作为参数的简化版 Disney BRDF 模型。不过由于观察的稀疏性,直接优化显式材质纹理导致不一致和未收敛的粗糙度。对此,如视利用语义和房间分割先验来解决这一问题,其中语义图像通过基于学习的模型预测,房间分割通过占用网格计算。在实现过程中,如视采取三阶段式策略。第一阶段基于 Lambertian 假设来优化稀疏反照率,而不像以物体为中心的小场景那样将反照率初始化为常数。虽然可以通过公式 (3) 直接计算漫反射反照率,但在高光区域会使得反照过亮,导致下一阶段的粗糙度过高。因此,如视使用语义平滑约束在相同的语义分割上激发类似的反照率,如下公式 (4) 所示。稀疏的反照率通过公式 (5) 来优化。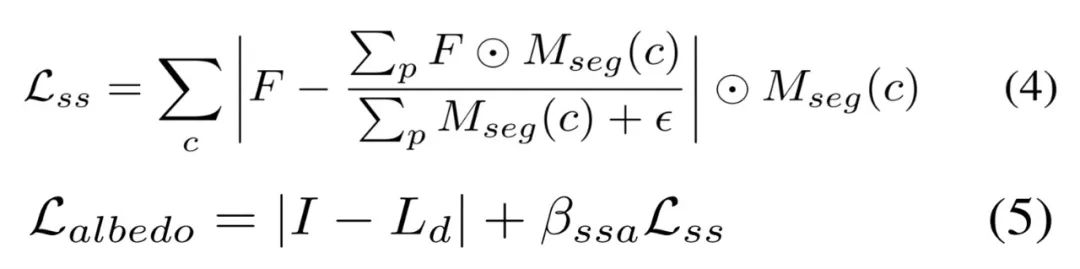 第二阶段基于虚拟高光(VHL)的采样和基于语义的传播。在多视图图像中,只能观察到稀疏的镜面反射线索会导致全局不一致的粗糙度,大规模场景尤甚。不过通过语义分割先验,高光区域的合理粗糙度可以传播到具有相同语义的区域。如视首先基于粗糙度为 0.01 的输入姿态来渲染图像以找到每个语义类的 VHL 区域,然后根据冻结的稀疏反照率和光照来优化这些 VHL 的粗糙度。合理的粗糙度可以通过公式 (6) 传播到相同的语义分割中,并且该粗糙度可以通过公式 (7) 进行优化。
第二阶段基于虚拟高光(VHL)的采样和基于语义的传播。在多视图图像中,只能观察到稀疏的镜面反射线索会导致全局不一致的粗糙度,大规模场景尤甚。不过通过语义分割先验,高光区域的合理粗糙度可以传播到具有相同语义的区域。如视首先基于粗糙度为 0.01 的输入姿态来渲染图像以找到每个语义类的 VHL 区域,然后根据冻结的稀疏反照率和光照来优化这些 VHL 的粗糙度。合理的粗糙度可以通过公式 (6) 传播到相同的语义分割中,并且该粗糙度可以通过公式 (7) 进行优化。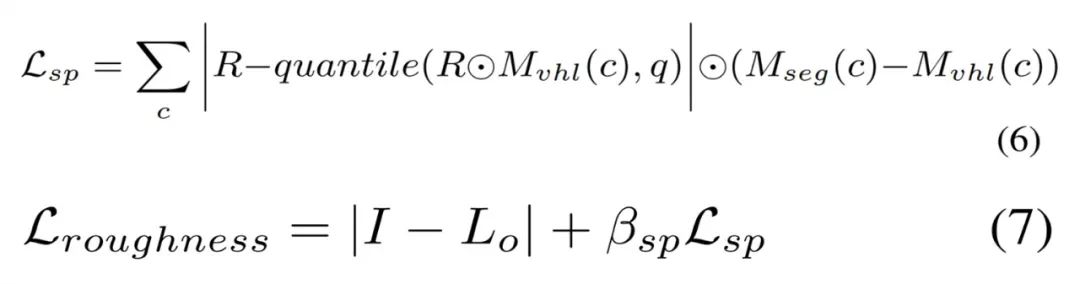 第三阶段基于分割的微调。如视基于语义分割和房间分割先验来微调所有的材质纹理。具体地,如视使用了与公式 (4) 类似的平滑约束以及用于粗糙度的房间平滑约束,使不同房间的粗糙度变得更柔和、平滑。房间平滑约束由公式 (8) 定义,同时不对反照率使用任何平滑约束,总损失被定义公式 (9) 所示。
第三阶段基于分割的微调。如视基于语义分割和房间分割先验来微调所有的材质纹理。具体地,如视使用了与公式 (4) 类似的平滑约束以及用于粗糙度的房间平滑约束,使不同房间的粗糙度变得更柔和、平滑。房间平滑约束由公式 (8) 定义,同时不对反照率使用任何平滑约束,总损失被定义公式 (9) 所示。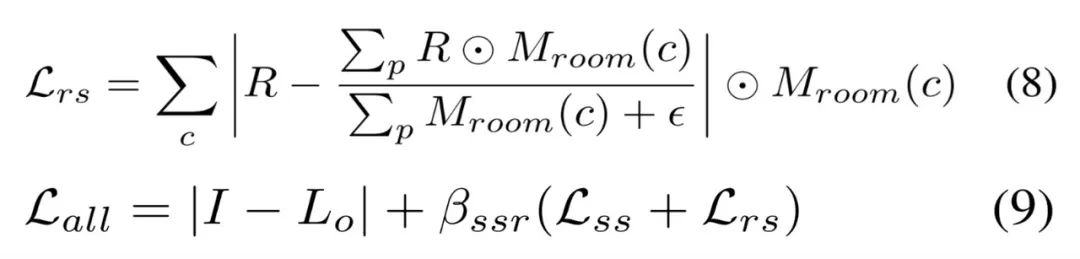 实验设置和效果比较关于数据集,如视使用了两个数据集:合成数据集和真实数据集。对于前者,如视使用路径追踪器创建一个具有不同材质和光源的合成场景,渲染了 24 个用于优化的视图和 14 个新视图,为每个视图渲染 Ground Truth 材质图像。对于后者,由于 Scannet、Matterport3D 和 Replica 等常用大规模场景的真实数据集缺乏 full-HDR 图像,如视收集了 10 个 full-HDR 真实数据集,并通过合并 7 个包围式曝光捕获 10 到 20 个 full-HDR 全景图像。关于基线方法。对于从大规模场景的多视图图像中恢复 SVBRDFs,目前逆渲染方法有基于单张图像学习的 SOTA 方法 PhyIR、以多视图物体为中心的 SOTA 神经渲染方法 InvRender、NVDIFFREC 和 NeILF。关于评估指标,如视使用 PSNR、SSIM 和 MSE 来评估材质预测和重渲染图像以进行定量比较,并使用 MAE 和 SSIM 来评估由不同光照表示渲染的重打光图像。首先来看合成数据集上的评估,如下表 1 和图 4 所示,如视方法在粗糙度估计方面显著优于 SOTA 方法,并且该粗糙度可以产生物理合理的镜面反射率。此外相较于原来的隐式表示,具有如视混合光照表示的 NeILF 减少了材质与光照之间的模糊性。
实验设置和效果比较关于数据集,如视使用了两个数据集:合成数据集和真实数据集。对于前者,如视使用路径追踪器创建一个具有不同材质和光源的合成场景,渲染了 24 个用于优化的视图和 14 个新视图,为每个视图渲染 Ground Truth 材质图像。对于后者,由于 Scannet、Matterport3D 和 Replica 等常用大规模场景的真实数据集缺乏 full-HDR 图像,如视收集了 10 个 full-HDR 真实数据集,并通过合并 7 个包围式曝光捕获 10 到 20 个 full-HDR 全景图像。关于基线方法。对于从大规模场景的多视图图像中恢复 SVBRDFs,目前逆渲染方法有基于单张图像学习的 SOTA 方法 PhyIR、以多视图物体为中心的 SOTA 神经渲染方法 InvRender、NVDIFFREC 和 NeILF。关于评估指标,如视使用 PSNR、SSIM 和 MSE 来评估材质预测和重渲染图像以进行定量比较,并使用 MAE 和 SSIM 来评估由不同光照表示渲染的重打光图像。首先来看合成数据集上的评估,如下表 1 和图 4 所示,如视方法在粗糙度估计方面显著优于 SOTA 方法,并且该粗糙度可以产生物理合理的镜面反射率。此外相较于原来的隐式表示,具有如视混合光照表示的 NeILF 减少了材质与光照之间的模糊性。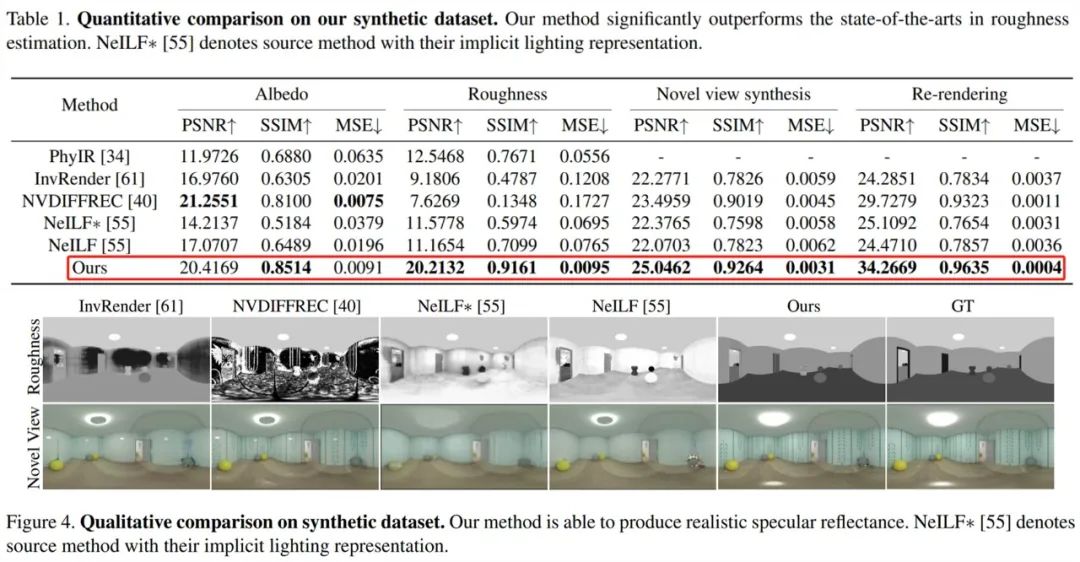 接着在包含复杂材质和光照的挑战性真实数据集上进行评估,下表 2 的定量比较结果显示出如视方法优于以往方法。尽管这些方法具有近似的重渲染误差,但仅有如视方法解耦了全局一致和物理合理的材质。
接着在包含复杂材质和光照的挑战性真实数据集上进行评估,下表 2 的定量比较结果显示出如视方法优于以往方法。尽管这些方法具有近似的重渲染误差,但仅有如视方法解耦了全局一致和物理合理的材质。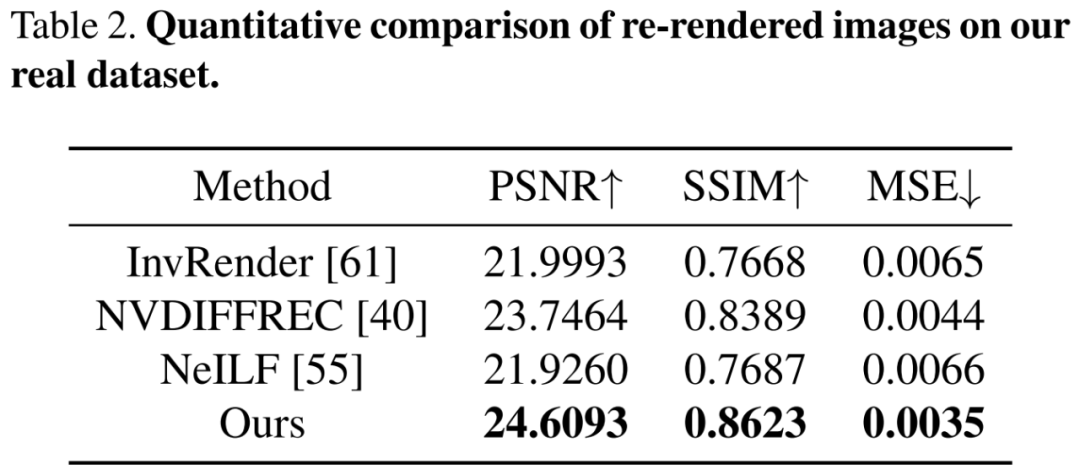 下图 5 和图 6 分别展示了 3D 视图和 2D 图像视图的定性比较。PhyIR 由于域间隙大导致泛化性能差,无法实现全局一致性预测。InvRender、NVDIFFREC 和 NeILF 产生了带有伪影的模糊预测,难以解耦正确的材质。NVDIFFREC 虽能实现与如视方法类似的性能,但无法解耦反照率与粗糙度之间的模糊性,比如镜面反射分量中的高光被错误地恢复为漫反射反照率。
下图 5 和图 6 分别展示了 3D 视图和 2D 图像视图的定性比较。PhyIR 由于域间隙大导致泛化性能差,无法实现全局一致性预测。InvRender、NVDIFFREC 和 NeILF 产生了带有伪影的模糊预测,难以解耦正确的材质。NVDIFFREC 虽能实现与如视方法类似的性能,但无法解耦反照率与粗糙度之间的模糊性,比如镜面反射分量中的高光被错误地恢复为漫反射反照率。 消融实验为了展示其光照表示和材质优化策略的有效性,如视针对 TBL、混合光照表示、第一阶段的反照率初始化、第二阶段用于粗糙度估计的 VHL 采样和语义传播、第三阶段基于分割的微调进行了消融实验。首先将 TBL 与以往方法中广泛使用的 SH 光照和 SG 光照方法进行了比较,结果如下图 7 所示,如视 TBL 在低频和高频特征方面都表现出了高保真度。
消融实验为了展示其光照表示和材质优化策略的有效性,如视针对 TBL、混合光照表示、第一阶段的反照率初始化、第二阶段用于粗糙度估计的 VHL 采样和语义传播、第三阶段基于分割的微调进行了消融实验。首先将 TBL 与以往方法中广泛使用的 SH 光照和 SG 光照方法进行了比较,结果如下图 7 所示,如视 TBL 在低频和高频特征方面都表现出了高保真度。 其次验证混合光照表示的有效性,将混合光照表示与原始 TBL 进行比较,结果如下图 8 所示。如果没有混合光照表示,反照率会导致噪声并且收敛变慢。预计算辐照度的引入可以使用高分辨率输入来恢复精细的材质,并大大加速优化过程。同时与 NIrF 相比,IrT 产生了更精细和无伪影的反照率。
其次验证混合光照表示的有效性,将混合光照表示与原始 TBL 进行比较,结果如下图 8 所示。如果没有混合光照表示,反照率会导致噪声并且收敛变慢。预计算辐照度的引入可以使用高分辨率输入来恢复精细的材质,并大大加速优化过程。同时与 NIrF 相比,IrT 产生了更精细和无伪影的反照率。 最后对三阶段式策略的有效性进行了验证,结果如下表 3 和图 9 所示。基线粗糙度未能收敛且仅高光区域得到更新。第一阶段如果没有反照率初始化,则高光区域反照过亮并导致不正确的粗糙度。第二阶段基于 VHL 的采样和基于语义的传播,对于恢复未观察到镜面反射高光区域的合理粗糙度至关重要。第三阶段基于分割的微调产生了精细的反照率,使得最终的粗糙度更平滑,并阻止了不同材质之间粗糙度的错误传播。
最后对三阶段式策略的有效性进行了验证,结果如下表 3 和图 9 所示。基线粗糙度未能收敛且仅高光区域得到更新。第一阶段如果没有反照率初始化,则高光区域反照过亮并导致不正确的粗糙度。第二阶段基于 VHL 的采样和基于语义的传播,对于恢复未观察到镜面反射高光区域的合理粗糙度至关重要。第三阶段基于分割的微调产生了精细的反照率,使得最终的粗糙度更平滑,并阻止了不同材质之间粗糙度的错误传播。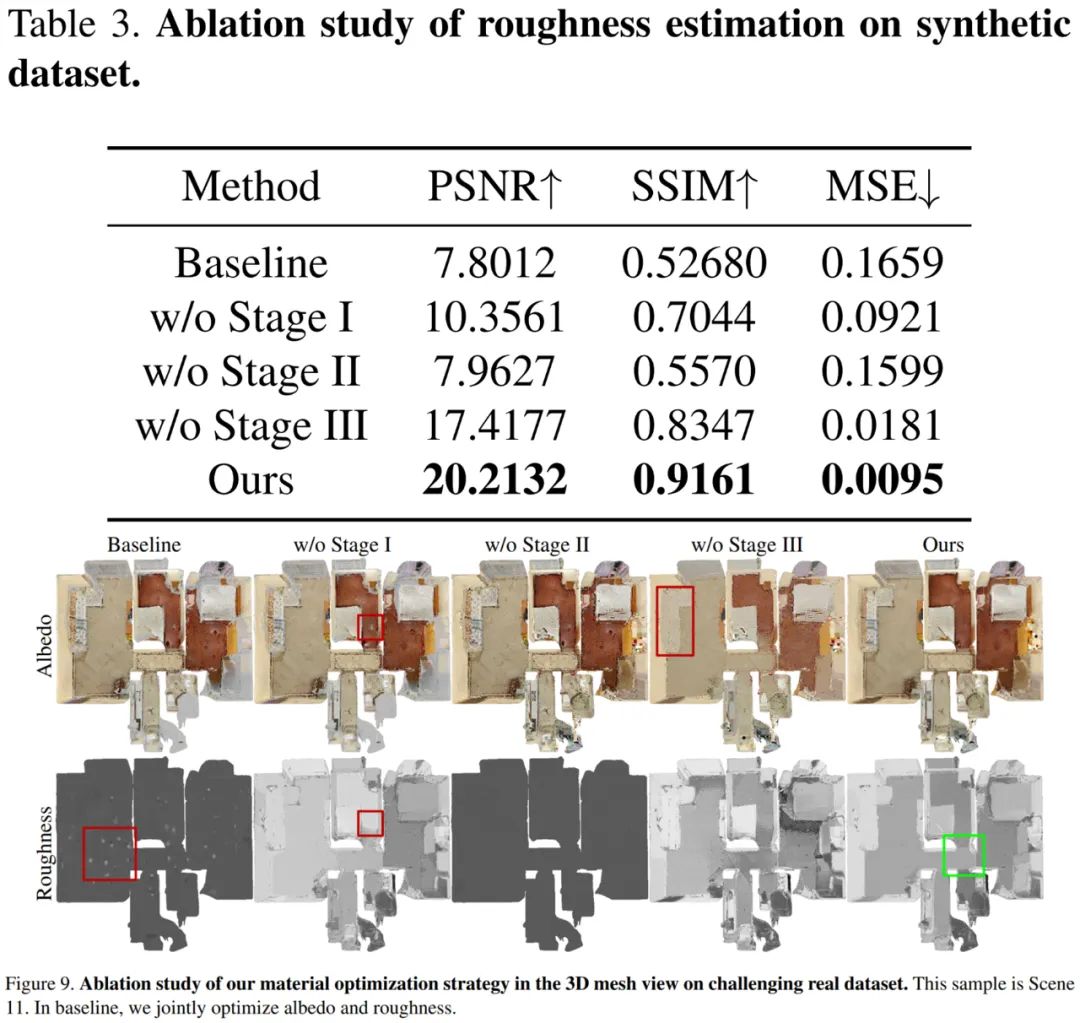
 材质编辑
材质编辑 重打光其次以往基于优化的可微渲染方法计算成本极高,效率极低。近年来,为了更好地解决逆渲染问题,同时减少对训练数据的依赖,可微渲染方法被提出,即通过「微分求导」方式使正向渲染可微分,进而将梯度反向传播至渲染参数,最终优化得到基于物理的待求解参数。这类方法包括球谐(spherical-harmonic, SH)光照 [1] 和三维球形高斯(Volumetric Spherical Gaussian, VSG)光照。但是大规模室内场景存在遮挡、阴影等大量复杂的光学效应,在可微渲染中建模全局光照会带来高昂的计算成本。如视本次提出的 TBL 在高效准确地表示室内场景全局光照的同时,只需要大约 20MB 内存,而基于密集网格的 VSG 光照 [2] 大约需要 1GB 内存,基于稀疏网格的 SH 光照方法 Plenoxels [3] 大约需要 750MB 内存,数据内存容量实现了数十倍缩减。不仅如此,如视新方法可以在 30 分钟内完成整个室内场景的逆渲染,而传统方法 [4] 可能需要 12 个小时左右,整整提升了 24 倍。计算速度的大幅提升意味着成本的降低,性价比优势更加显著,从而离大规模实际应用更近了一步。最后以往的类 NeRF 神经逆渲染方法(如 PS-NeRF [5]、 NeRFactor [6] 等)主要面向以物体为中心的小规模场景,建模大规模室内场景似乎无能为力。基于如视精准数字空间模型以及高效准确的混合光照表示,全新逆渲染框架通过引入语义分割和房间分割先验解决了这一问题。对于此次的全新深度逆渲染框架,如视首席科学家潘慈辉表示,「真正意义上实现了对真实世界更深层的数字化,解决了以往逆渲染方法难以在真实场景下恢复物理合理的材质和光照以及多视角一致性的问题,为三维重建和 MR 的落地应用带来了更大想象空间。」
重打光其次以往基于优化的可微渲染方法计算成本极高,效率极低。近年来,为了更好地解决逆渲染问题,同时减少对训练数据的依赖,可微渲染方法被提出,即通过「微分求导」方式使正向渲染可微分,进而将梯度反向传播至渲染参数,最终优化得到基于物理的待求解参数。这类方法包括球谐(spherical-harmonic, SH)光照 [1] 和三维球形高斯(Volumetric Spherical Gaussian, VSG)光照。但是大规模室内场景存在遮挡、阴影等大量复杂的光学效应,在可微渲染中建模全局光照会带来高昂的计算成本。如视本次提出的 TBL 在高效准确地表示室内场景全局光照的同时,只需要大约 20MB 内存,而基于密集网格的 VSG 光照 [2] 大约需要 1GB 内存,基于稀疏网格的 SH 光照方法 Plenoxels [3] 大约需要 750MB 内存,数据内存容量实现了数十倍缩减。不仅如此,如视新方法可以在 30 分钟内完成整个室内场景的逆渲染,而传统方法 [4] 可能需要 12 个小时左右,整整提升了 24 倍。计算速度的大幅提升意味着成本的降低,性价比优势更加显著,从而离大规模实际应用更近了一步。最后以往的类 NeRF 神经逆渲染方法(如 PS-NeRF [5]、 NeRFactor [6] 等)主要面向以物体为中心的小规模场景,建模大规模室内场景似乎无能为力。基于如视精准数字空间模型以及高效准确的混合光照表示,全新逆渲染框架通过引入语义分割和房间分割先验解决了这一问题。对于此次的全新深度逆渲染框架,如视首席科学家潘慈辉表示,「真正意义上实现了对真实世界更深层的数字化,解决了以往逆渲染方法难以在真实场景下恢复物理合理的材质和光照以及多视角一致性的问题,为三维重建和 MR 的落地应用带来了更大想象空间。」 如视打造的AI营销助手对于 VR + 产业融合,如视的最大优势在于不断良性进化的数字化重建算法和海量真实数据的积累,使其同时拥有了较高的技术壁垒和较大的数据壁垒。这些算法和数据在某种程度上还能相互循环起来,不断地扩大优势。同时数据和算法的壁垒使如视更加容易地切入各个行业的痛点问题,带来一些技术解决方案,创新行业发展新模式。逆渲染技术成果连续两年入选 CVPR,主要脱胎于如视想要在 MR 方向上有所作为并在产业上实现一些落地。未来,如视希望打通实景 VR 与纯虚拟仿真之间的 Gap,真正做到虚实融合,并构建更多行业应用。
如视打造的AI营销助手对于 VR + 产业融合,如视的最大优势在于不断良性进化的数字化重建算法和海量真实数据的积累,使其同时拥有了较高的技术壁垒和较大的数据壁垒。这些算法和数据在某种程度上还能相互循环起来,不断地扩大优势。同时数据和算法的壁垒使如视更加容易地切入各个行业的痛点问题,带来一些技术解决方案,创新行业发展新模式。逆渲染技术成果连续两年入选 CVPR,主要脱胎于如视想要在 MR 方向上有所作为并在产业上实现一些落地。未来,如视希望打通实景 VR 与纯虚拟仿真之间的 Gap,真正做到虚实融合,并构建更多行业应用。 华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
我发现了这个问题here.并且非常想知道如何在Rails中实现类似30.seconds.ago的技术解释。方法链?Numeric用法如下:http://api.rubyonrails.org/classes/Numeric.html#method-i-seconds.还有什么? 最佳答案 Here是seconds的实现:defsecondsActiveSupport::Duration.new(self,[[:seconds,self]])end并且,here是ago的实现:#CalculatesanewTimeorDatethat
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat
您好,我将其视为一个面试问题,并认为这是一个有趣的问题,但我不确定答案。最好的方法是什么? 最佳答案 假设*nix:system("sortoutput_file")“排序”可以使用临时文件来处理大于内存的输入文件。如果需要,它有开关来调整主内存的数量和它将使用的临时文件的数量。如果不是*nix,或者面试官因为斜着回答皱眉,那我就编码一个外部mergesort.请参阅@psyho的回答以获得外部排序算法的良好总结。 关于ruby-使用Ruby作为脚本语言,使用4gbRAM的计算机对30g
最近更新的博客华为OD机试-卡片组成的最大数字(Python)|机试题算法思路华为OD机试-网上商城优惠活动(一)(Python)|机试题算法思路华为OD机试-统计匹配的二元组个数(Python)|机试题算法思路华为OD机试-找到它(Python)|机试题算法思路华为OD机试-九宫格按键输入(Python)|机试算法备考思路华为OD机试-身高排序(Python)|备考思路使用说明参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。华为OD清单查看地址:blog.csdn.net/hihell/catego
一、概述在之前的一篇博文中,记录了AT24C01、AT24C02芯片的读写驱动,先将之前的相关文章include一下:1.IIC驱动:4位数码管显示模块TM1637芯片C语言驱动程序2.AT24C01/AT24C02读写:AT24C01/AT24C02系列EEPROM芯片单片机读写驱动程序本文记录分享AT24C04、AT24C08、AT24C16芯片的单片机C语言读写驱动程序。二、芯片对比介绍型号容量bit容量byte页数字节/页器件寻址位可寻址器件数WordAddress位数/字节数备注AT24C044k5123216A2A149/1WordAddress使用P0位AT24C088k1024