
JAVA编码中存在一些容易被人忽视的陷阱,稍不留神可能就会跌落其中,给项目的稳定运行埋下隐患。此外,这些陷阱也是面试的时候面试官比较喜欢问的问题。
本文对这些陷阱进行了统一的整理,让你知道应该如何避免落入陷阱中,下面就一起来了解下吧。
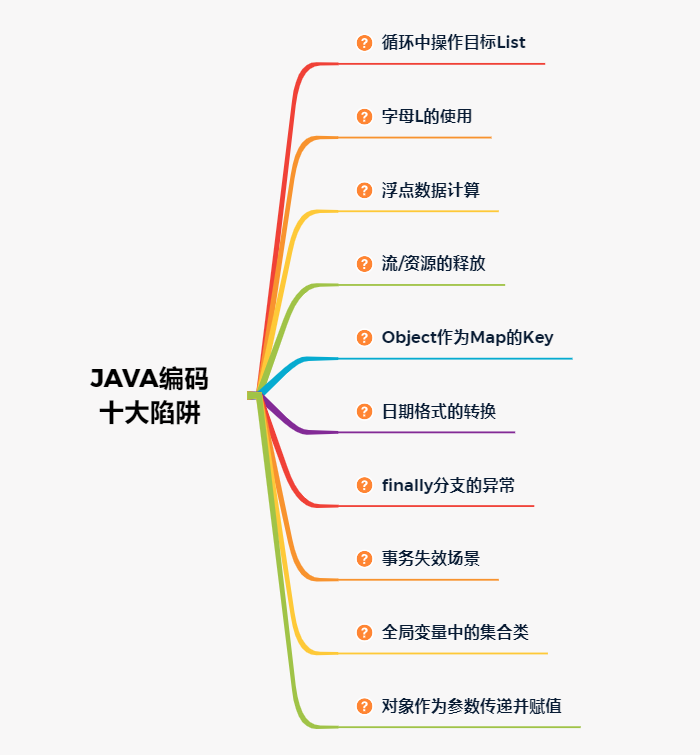
遍历List然后对list中符合条件的元素进行删除操作,这是项目里面非常常见的一个场景。
先看下两种典型的错误写法:
错误写法1:
for (User user : userList) {
if ("男".equals(user.getSex())) {
userList.remove(user);
}
}
错误原因:
在循环或迭代时,会首先创建一个迭代实例,这个迭代实例的expectedModCount 赋值为集合的modCount。而每当迭代器使⽤ hashNext() / next() 遍历下⼀个元素之前,都会检测 modCount 变量与expectedModCount 值是否相等,相等的话就返回遍历;否则就抛出异常ConcurrentModificationException,终⽌遍历。
如果在循环中添加或删除元素,是直接调用集合的add(),remove()方法,导致了modCount增加或减少,但这些方法不会修改迭代实例中的expectedModCount,导致在迭代实例中expectedModCount与 modCount的值不相等,抛出ConcurrentModificationException异常。
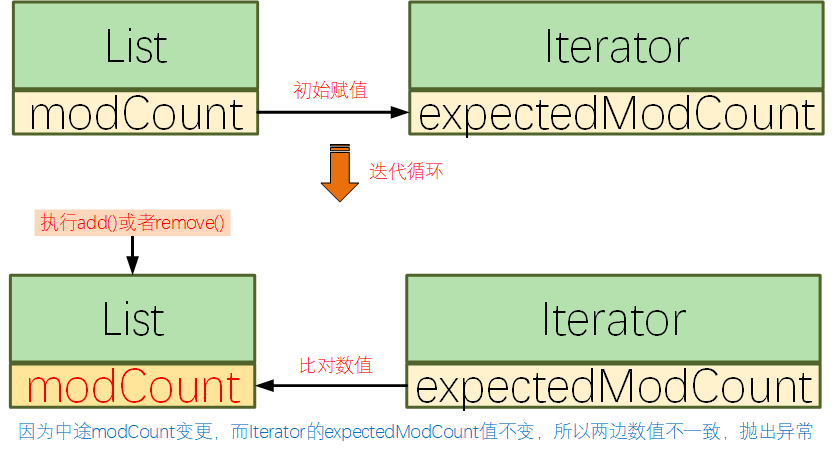
错误写法2:
for (int i = 0; i < userList.size(); i++>) {
if ("男".equals(user.getSex())) {
userList.remove(i);
}
}
错误原因:
删除元素之后,元素下标发生前移,但是指针是不变的,再处理下一个的时候,就可能会有部分元素被漏掉没有处理。
那正确的方式应该如何处理呢?接着往下看。
正确写法1:
// 使用迭代器来实现
Iterator iterator = userList.iterator();
while (iterator.hasNext()) {
if ("男".equals(user.getSex())) {
iterator.remove();
}
}
补充说明:
与前面的错误写法1相对比,同样都是基于迭代器的逻辑,为什么这种写法就对了呢?
这是因为迭代器中的remove(),add()方法,会在调用集合的remove(),add()方法后,将expectedModCount重新赋值为modCount,所以在迭代器中增加、删除元素是可以正常运行的。
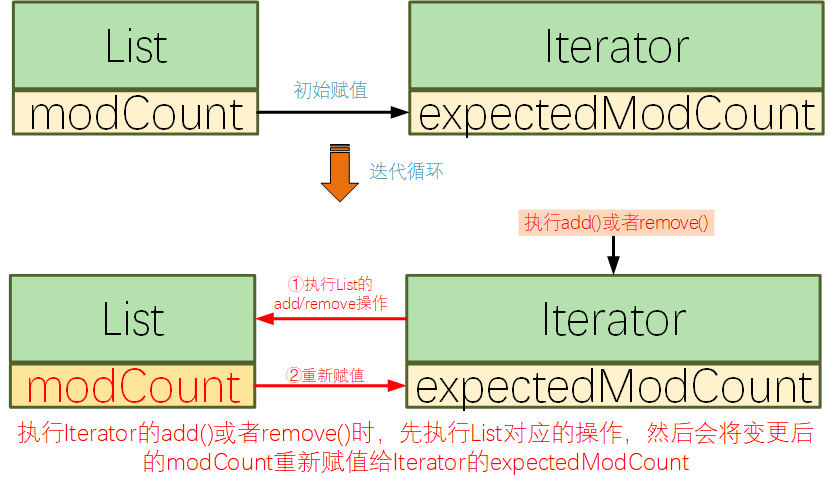
正确写法2:
// 使用Lambda表达式实现
userList.removeIf(user -> "男".equals(user.getSex());
正确写法3:
// 使用removeAll实现
List<User> maleUsers = new ArrayList<>();
for (User user : userList) {
if ("男".equals(user.getSex())) {
maleUsers.add(user);
}
}
userList.removeAll(maleUsers);
看个例子:
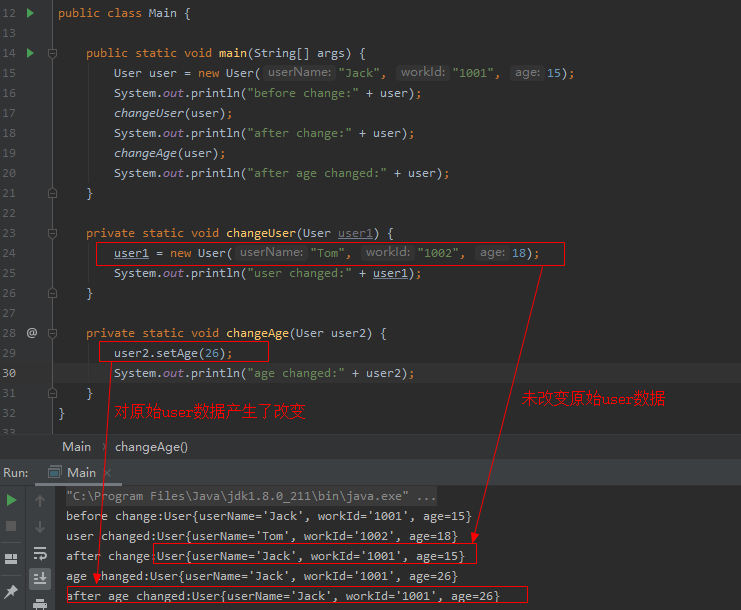
这里涉及到JAVA中一个值传递和引用传递的概念。
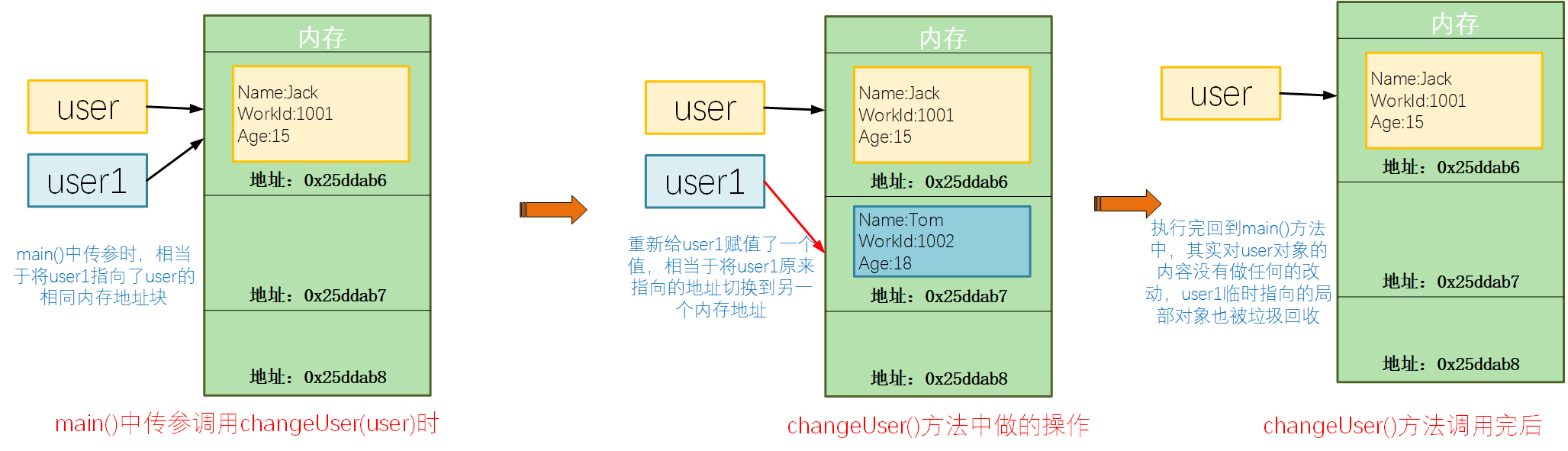
对于一个引用类型而言,参数传递的时候,本质上是将一个引用对象对应内存地址传递过去,参数对象与实际对象指向同一个内存块。对于示例代码中的changeUser()方法,将入参重新赋值了一个新的对象,本质上其实是将user1对应指向的内存地址信息更改了,对于原始的user而言,并没有被改变。
而对于chageAge()方法而言,对user2的操作,本质上是对user2所指向的具体内存对象进行操作,也即user对应的内存对象数据,所以这种情况下,变更是会生效的。
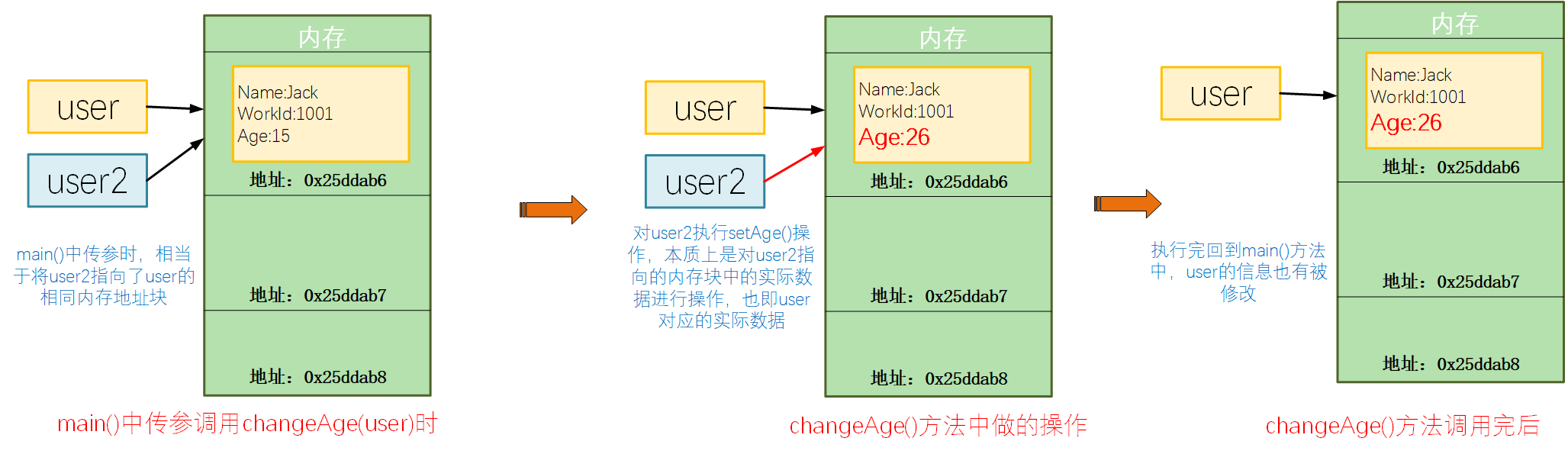
所以呢,编码的时候,要注意不能在方法里面对入参进行重新赋值,可以采用返回值的方式返回个新的结果对象,然后进行赋值操作。
先看一个例子:
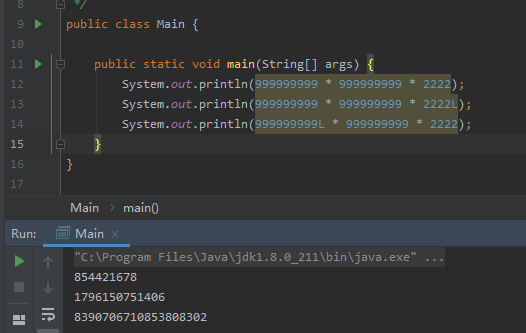
同样相同的三个数字的相乘,L标识的位置不同,得到的结果也不一样,那到底哪个是对的呢?
很明显这个一个JAVA隐式类型转换的问题。

TIPS:
int运算转long的时候,最好将第一个运算的数字标识为L(long)型,避免中途数据溢出。
再看个例子:
public static void main(String[] args) {
System.out.println(2 * 2l);
}
第一眼看完,想一下答案应该是几?是42吗?
其实结果是4,为什么?因为第二个2后面的是个字母l。虽然这种写法对于程序而言没有问题,但是很容易让开发人员混淆,造成认知上的错误。
TIPS:
long数字标识的时候,使用大写字母L来表示。
打开的流或者连接,在用完之后需要可靠的退出。但是有一种循环中打开流的场景,需要特别注意,笔者在多年的代码review经历中发现,基本每个项目都会存在循环中打开的流没有全部可靠释放的问题。

上面的示例代码中,虽然最后finally里面也有执行流的关闭操作,但是try分支中,inputStream是在一个for循环里面被多次创建了,而最终finally分支中仅关闭了最后一个,之前的流都处于未关闭状态,造成资源的泄漏。
很多的项目中都使用SimpleDateFormat来做日期的格式化操作,但是要注意SimpleDataFormat是非线程安全的,所以使用的时候需要注意。
但是实际使用的时候,如果每次需要格式化的时候,都去new SimpleDateFormat()对象,这个成本开销有点大,会对整体的性能造成一定的影响。
所以使用的时候可以采取一些措施,保证线程安全的同时也兼顾其处理性能:

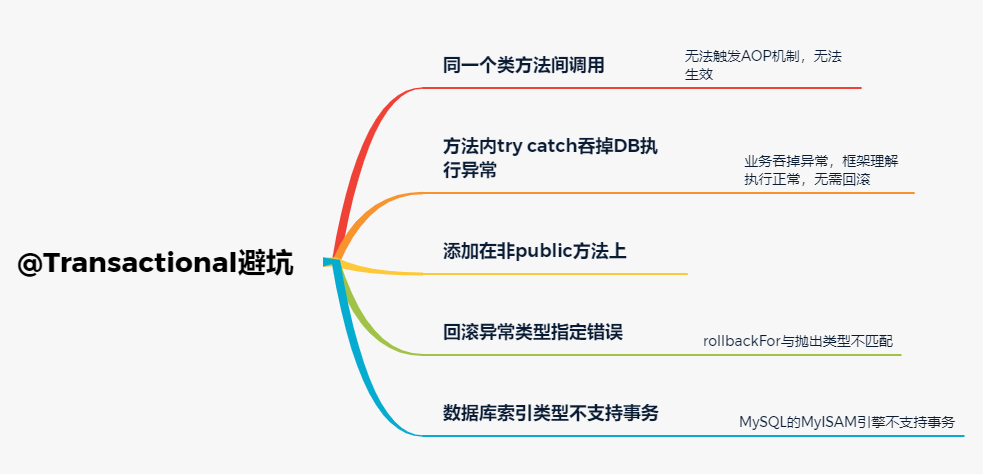
JAVA开发中,经常会使用Spring的@Transactional注解来指定事务回滚的相关策略,但是有时候会发现@Transactional并没有生效,下面介绍下可能的几种情况。
finally分支一般伴随着try...catch语句一起使用,用来当所有操作退出前执行一些收尾处理逻辑,比如资源释放、连接关闭等等。但是如果使用不当,也会造成我们的业务逻辑不按预期执行,所以使用的时候要注意。

finally分支中对返回值重新修改
先看下如下代码写法,在try...catch分支中都有return操作,然后再finally中进行返回值修改,最终返回结果并不会被finally中的逻辑修改:
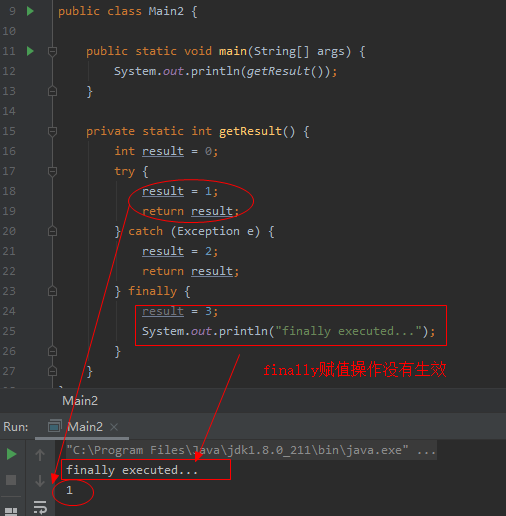
因为如果存在 finally 代码块,try...catch中的return语句不会立马返回调用者,而是记录下返回值的副本,待 finally代码块执行完毕之后再向调用者返回其值,然后即使在finally中修改了返回值,也不会返回修改后的值。
再看另一种常见的写法:
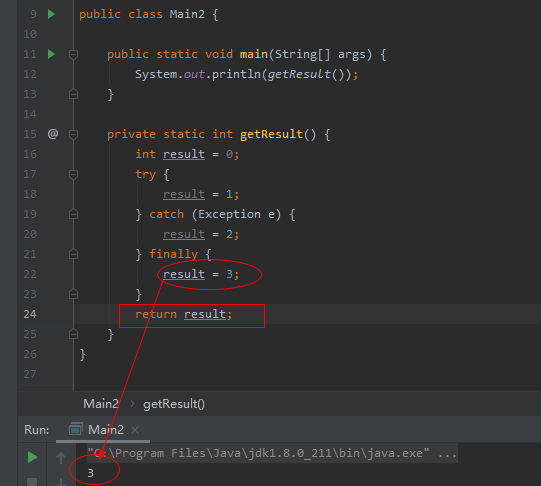
与上面的差异点在于,try...catch分支里面并没有return语句,而是finally外面统一执行返回操作,这种情况下就可以生效。其实也很好理解,try...catch...finally这个语句块里面没有return操作,所以也就不会有暂存return副本的逻辑了。
finally分支中直接return
在finally分支里面存在return语句是一个很不好的实践。一般的IDEA中也会智能提示finally里面存return分支。
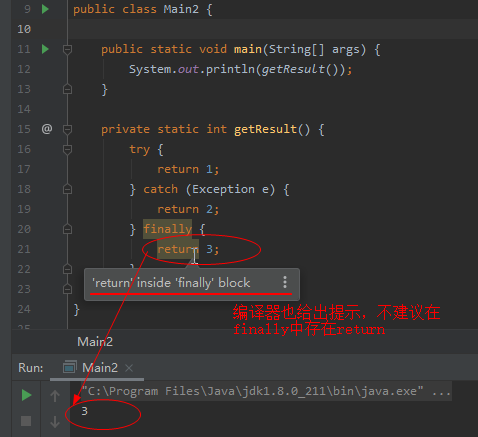
finally里面如果存在return分支,则finally里面的返回值会覆盖掉try...catch逻辑中处理后计划返回的结果,也即导致try...catch部分的逻辑失效,容易引起业务逻辑上的问题。
finally分支中抛出异常
一般的编码规范中,都会要求finally分支里面的处理逻辑要增加catch保护,防止其抛出异常。
原因说明:
相对而言,finally里面执行的都是一些资源释放类的操作,而try...catch部分则是业务维度的核心逻辑,人们更关心的是catch部分发生的业务层面的异常,如果finally里面抛出异常,会导致catch中原本应该要往外抛的异常被丢弃,可能会影响上层逻辑的后续处理。
全局类型的集合类,使用的时候需要注意两个关键点:
参考下redis之类的依赖内存的缓存中间件,都有一个绕不开的兜底策略,即数据淘汰机制。对于业务类编码实现的时候,如果使用Map等容器类来实现全局缓存的时候,应该要结合实际部署情况,确定内存中允许的最大数据条数,并提供超出指定容量时的处理策略。比如我们可以基于LinkedHashMap来定制一个基于LRU策略的缓存Map,来保证内存数据量不会无限制增长。
public class FixedLengthLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public FixedLengthLinkedHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定义数据淘汰触发条件,在每次put操作的时候会调用此方法来判断下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
看一段很简单的代码:
public static void main(String[] args) {
System.out.println(0.1 + 0.2);
}
上面的执行后,输出结果应该是多少?很明显应该是0.3呀!然而实际上,运行之后,输出结果为:
0.30000000000000004
这是因为浮点数是不精确的,因为浮点数是存在小数点位的,而十进制的0.1换算为二进制是一个无限循环小数,所以实际上存储的其实是一个近似0.1的值、而不是精确的0.1。
也正是这个原因,一般实现中,判断两个float是否相等时,往往不用==,而是判断两个浮点数之差绝对值是否小于一个很小的数。
对于一些需要精确计算的场景,显然是不能使用浮点数来运算的,比如一些银行金融领域涉及金钱数额相关的场景,是绝对不允许使用float或者double进行运算,而是推荐使用BigDecimal来替代。
大家都知道在JAVA中,HashMap的key是不可以重复的,相同的key对应值会进行覆盖。但是,如果使用自定义对象作为HashMap的key,就要小心了,因为如果操作不当,很容易造成内存泄漏的问题。
如果一定要使用,确保此Object一定是覆写了hashCode()和equals()方法,并且保证覆写的equals和hashCode方法中一定不能有频繁易变更的字段参与计算。
好啦,关于JAVA中常见的十大陷阱,这里就给大家分享到这里。希望大家在实际编码的时候可以注意提防,避免踩坑。
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注,也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg