优点: 写入是一次性完成的,消耗的时间比列式存储少,并且能够保证数据的完整性
缺点: 数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量较大可能会影响到数据的处理效率。
行式存储适合插入不适合查询
优点:在读取过程中不会产生冗余数据,这对数据完整性要求不高的大数据领域极其重要。
缺点: 写入效率、保证数据的完整性上都不如行式存储
列式存储适合查询不适合插入
文本格式是Hadoop生态系统内部和外部的最常见的格式,通常按照行存储,以回车换行符区分不同的行数据
优点:易读性好。至少是人能读懂的
缺点: 解析开销一般比二进制格式的开销大,特别是XML和JSON
最大的特点: 不支持块级别压缩,因此在进行压缩是会带来较高的读取成本
注意:Text File 不仅仅是指的是TXT文件,还包括CSV、JSON、XML等
Key、Value键值对进行序列化存储(二进制格式)序列化文件与文本文件相比更加紧凑,且支持record、block块级压缩。压缩的同时支持文件切分 作为中间数据存储格式,例如:将大量小文件合并放入到Sequence File文件中。record 就是一个kv键值对,其中数据保存在value中,可以选择是否针对value进行压缩
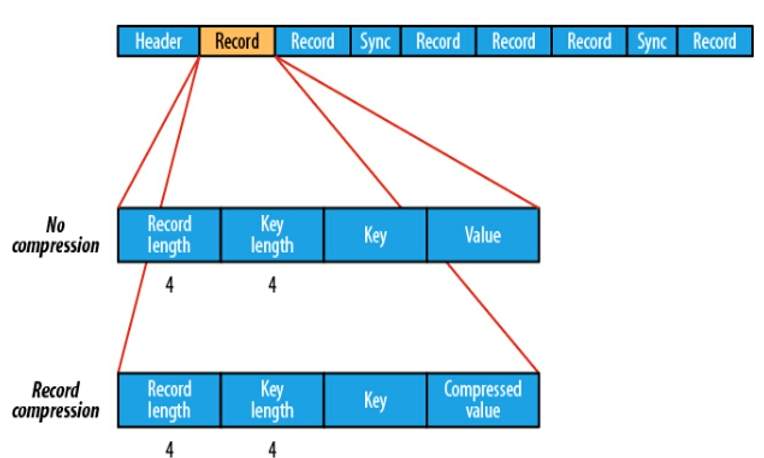
block就是多个record的集合,block级别的压缩性能更好
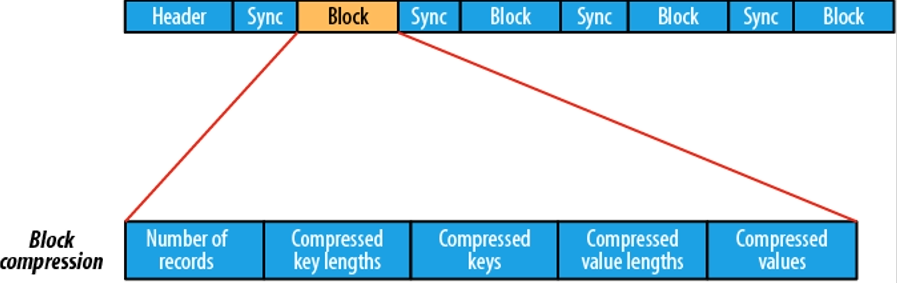
与语言无关的序列化系统,由hadoop 之父进行开发基于行的存储格式,他在每个文件中都包括Json格式的schema定义,从而提高了互操作性并允许schema的变法(删除列、添加行)。除了支持可切分以外,还支持快压缩。自描述格式,他将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。适合于大量频繁写入宽表数据(字段多、列多)的场景,其序列化、反序列化很快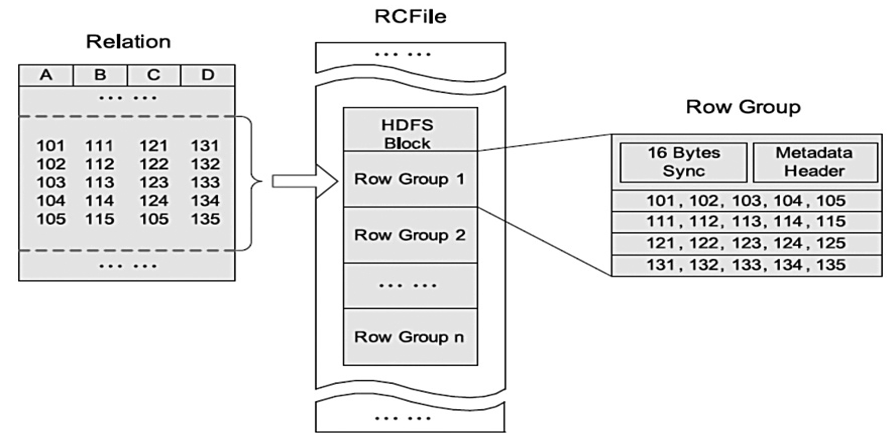
带均包括索引、数据和页脚,索引存储每列的最大值和最小值以及列中每一行的位置有多种文件压缩方式,并且有着很高的压缩比,文件时可切分的。二进制方式存储的,所以是不可以直接读取的。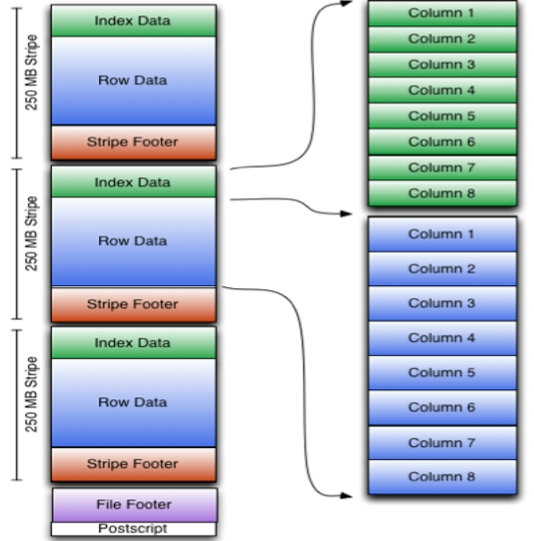
行组、列块、页组成。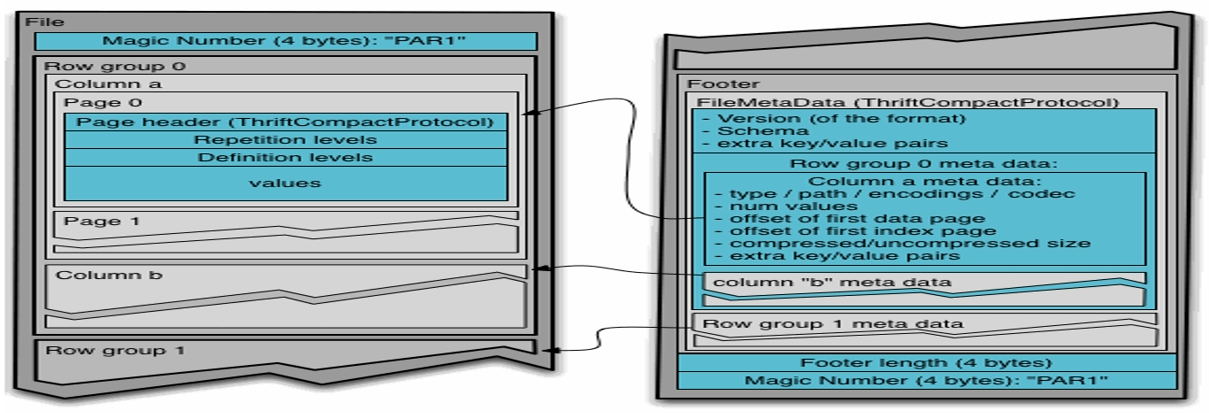
列式内存数据结构,主要用于构建数据系统

不适用Arrow:
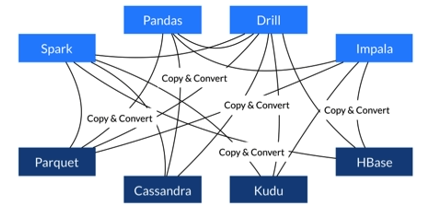
使用Arrow:
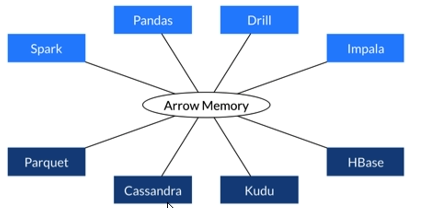
在内存中直接查找,大大提升了效率
压缩比
原先占100份的空间的东西经压缩后变成了20份空间,那么压缩比就是5,显然压缩比越高越好
压缩/解压缩吞吐量(时间)
压缩算法实现是否简单、开源
是否为无损压缩、回复效果是否够好
压缩后的文件是否支持split(切分)
Hadoop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口,所有的实现类都在org.apache.hadoop.io.compress包下。
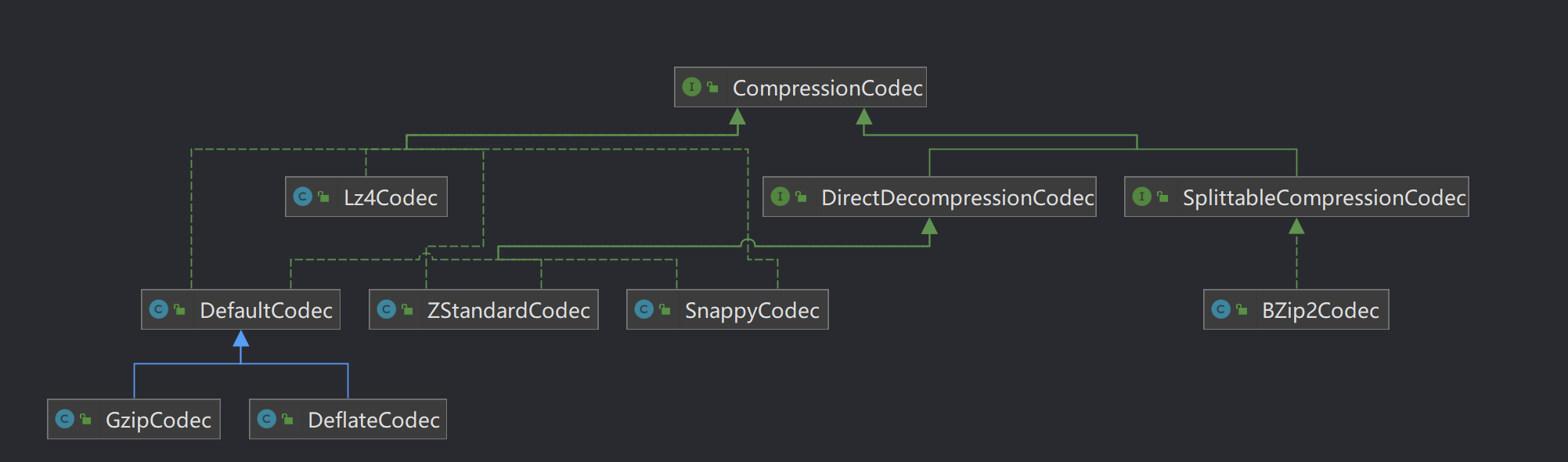
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码解码器 |
|---|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | gzip | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(切分点索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
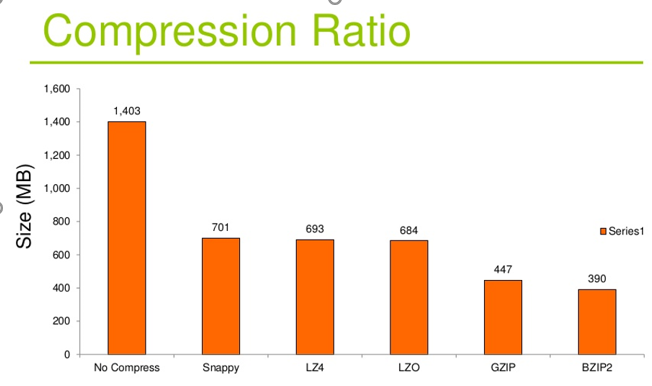
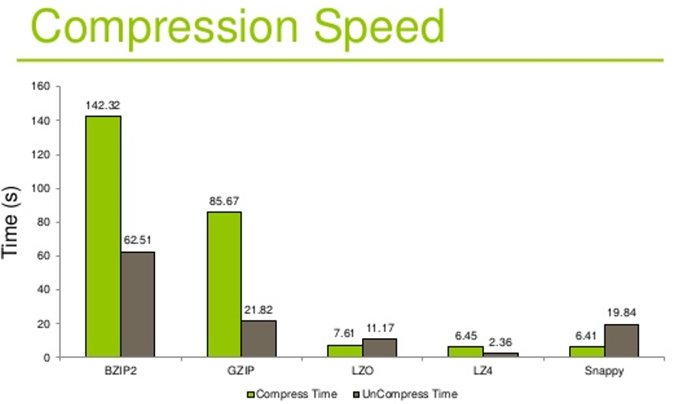
压缩的合理使用可以提高HDFS的内存效率
压缩解压意味着CPU、内存需要参与编码解码
选择压缩算法时不能够一味的追求某一指标的极致,要综合考虑性价比比较高的
文件的压缩解压程序或者工序需要对数据进行处理,大数据相关处理软件都支持直接设置
热数据:新传入的数据被大量地使用,这样的数据被标记成热数据。
暖数据:热数据随着时间的推移,访问次数在慢慢下滑,这时候就是一个暖数据
冷数据:暖数据的使用频率再次降低就是冷数据
冻数据:使用频率非常低,基本不使用甚至不用,则成为冻数据。
在Hadoop2.5及其以上就开始支持存储策略,在该策略下,不仅可以在默认的传统的磁盘上存储HDFS数据,还可以在SSD上存储数据
异构存储是Hadoop2.6.0版本以后出现的新特征,可以根据哥哥存储介质读写特征不同进行选择。
例如冷热数据的存储,对冷数据采用容量大但读写性能不高的存储介质如机器硬盘,热数据采用SSD进行存储
在读写效率上性能较大,异构特性允许我们对不同文件选择不同的存储介质进行保存,以实现机器性能的最大化
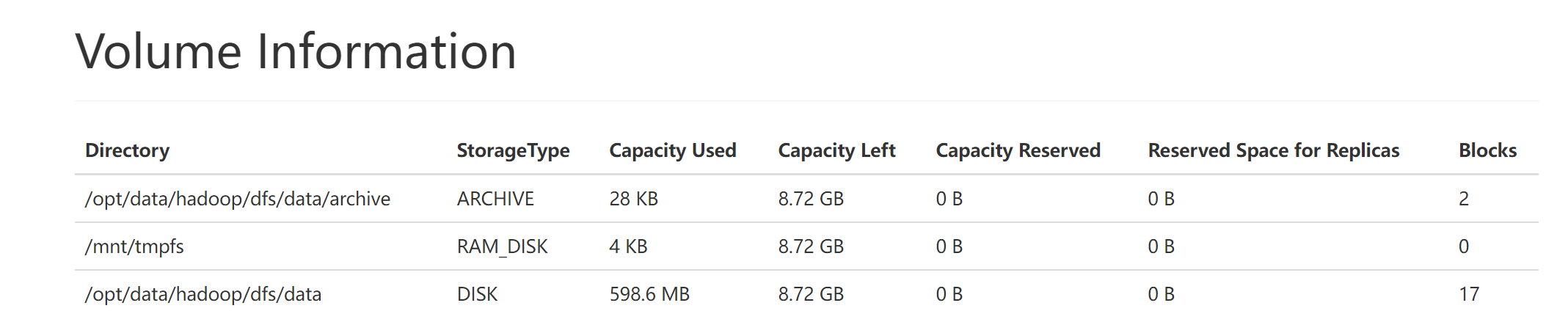
RAM_DISK(内存)
SSD(固态硬盘)
DISK(机器硬盘) 默认使用
ARCHIVE(高密度存储介质,存储档案历史数据)
配置属性时主动声明,HDFS没有自动检测的能力
dfs:datanode.data.dir=[SSD]file:///grid/dn/ssd0
如果目录前没有嗲上[SSD] [DISK] [ARCHIVE] [RAM_DISK]这四种类型中的任意一个,则默认为DISK
由于在本地我并没有生命该磁盘的类型,进行查看:

显然是DISK
块存储指的是对HDFS文件的数据块副本存储
对于数据的存储介质,HDFS的BlockStoragePolicySuite类内部定义了6中策略
Hot(默认策略)、 COLD、 WARM、 ALL_SSD 、 ONE_SSD、 LAZY_PERSIST策略
Hot:用于存储和计算,流行且仍用于处理的数据将保留在此策略中。所有的副本都保存在DISK中
COLD:仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热数据移动到冷数据。所有的副本都存储在APCHIVE中
WARM:部分热和部分冷,热时,其某些副本存储在DISK中,其余副本存储在ARCHIVE中
ALL_SSD: 所有副本都存储在SSD中
One_SSD:用于将副本之一存储在SSD中,其余副本存储在DISK中
Lazy_Persist: 用于在内存中写入具有单个副本的块,首先将副本写入到RAM_DISK,然后将其延迟保存在DISK中
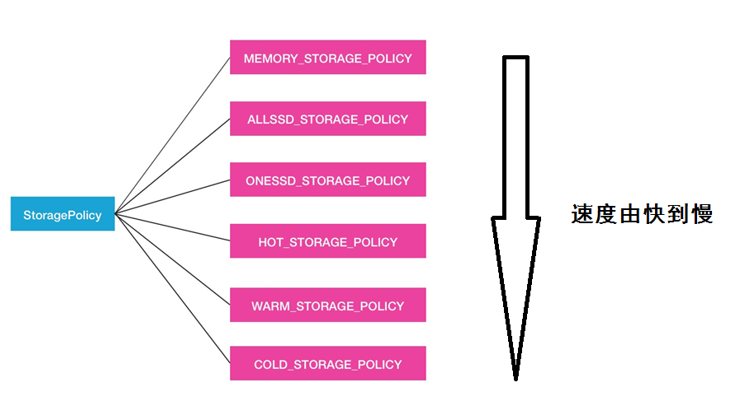
hdfs storagepolicies -listPolicies
测试结果:

hdfs storagepolicies -setStoragePolicy -path <path> -ploicy <policy>
hdfs storagepolicies -unsetStoragePolicy -path <path>
在执行unset之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则采用默认的存储策略
hdfs storagepolicies -getStoragePolicy -path <path>
| 规划目录 | 用途 |
|---|---|
| /data/hot | 热阶段数据 |
| /data/warm | 温阶段数据 |
| /data/cold | 冷阶段数据 |
进入到hadoop的目录下的etc/hadoop下
编写hist-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive</value>
</property>
保存后将文件分发到其他文件
rsync -av /opt/module/hadoop-3.3.1/etc/hadoop/ root@hadoop134:/opt/module/hadoop-3.3.1/etc/hadoop/
通过rsync将其进行分发
一共三个节点,我们随便找到一个节点,查看其状态:

显然已经识别成功。
创建文件夹
hadoop fs -mkdir -p /data/hot
hadoop fs -mkdir -p /data/warm
hadoop fs -mkdir -p /data/cold
创建成功
hdfs storagepolicies -setStoragePolicy -path /data/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/cold -policy COLD

检查各个文件的策略:
hdfs storagepolicies -getStoragePolicy -path /data/hot
hdfs storagepolicies -getStoragePolicy -path /data/warm
hdfs storagepolicies -getStoragePolicy -path /data/cold

这里将hello.txt文件上传到hdfs文件系统中
hadoop fs -put /root/hello.txt /data/hot
hadoop fs -put /root/hello.txt /data/warm
hadoop fs -put /root/hello.txt /data/cold
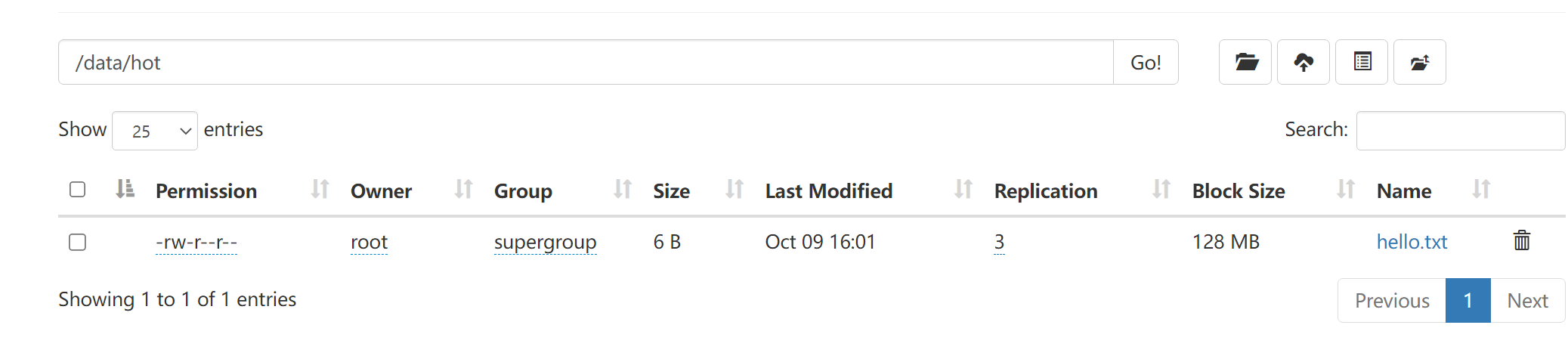
通过检查发现全部上传成功。
指令:
hdfs fsck /data/hot/hello.txt -files -blocks -locations
查看hot下文件的存储位置
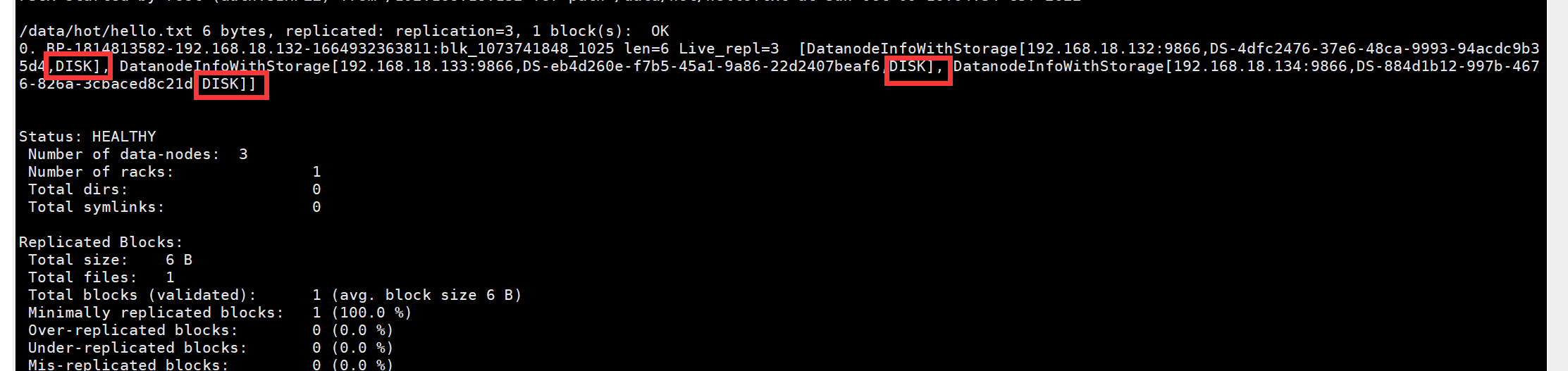
可见hot策略下,三个备份文件都存储在DISK(机器硬盘)下
hdfs fsck /data/warm/hello.txt -files -blocks -locations

可见WARM策略下部分存在DISK上,部分存在ARCHIVE中
hdfs fsck /data/cold/hello.txt -files -blocks -locations

在CLOD策略下,全部存储在ARCHIVE中
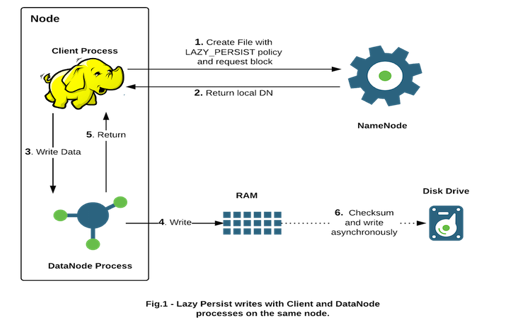
使用的时tmpfs,tmpfs一种基于内存的文件系统。最好的RAM文件系统。
mount -t tmpfs -o size=200m tmpfs /mnt/tmpfs/
通过指令查看是否挂在成功:
df -h
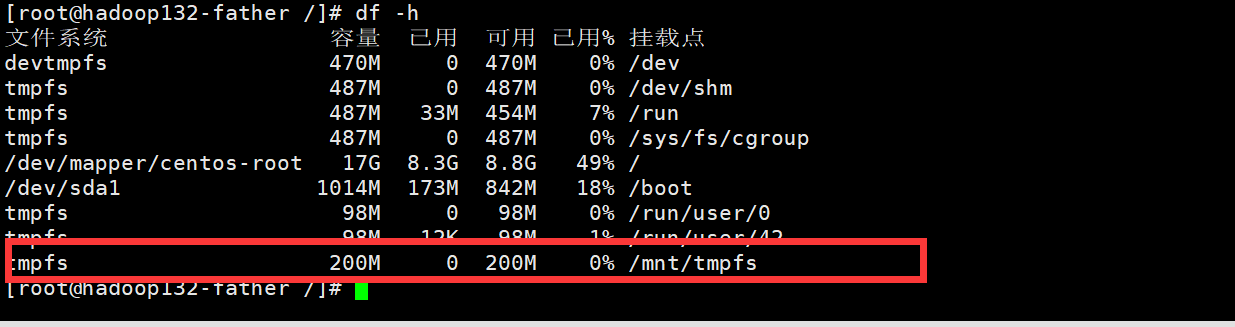
显然挂载成功
将机器中已经完成好的虚拟内存盘配置到dfs.datanode.data.dir中,其次还需要带上RAM_DISK标签
配置文件如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive,[RAM_DISK]/mnt/tmpfs</value>
</property>
随后通过rsync进行分发
然后重启hadoop 或者hdfs
查看是否能够识别:
显然识别成功
dfs.storage.policy.enabled
是否开启异构存储,默认为true,所以可以不进行设置
dfs.datanode.max.locked.memory
用于在数据节点上的内存中缓存块副本的内存量。默认情况下此参数设置为0,这将禁用内存中缓存。内存之国小会导致内存中的总的可存储的数据块变小,但如果超过DataNode能承受的最大内存大小的话,部分内存块会被直接移出
<!-- 用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内存大小的话,部分内存块会被直接移出 。byte 类型 -->
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
先创建文件夹
hadoop fs -mkdir -p /data/lazy
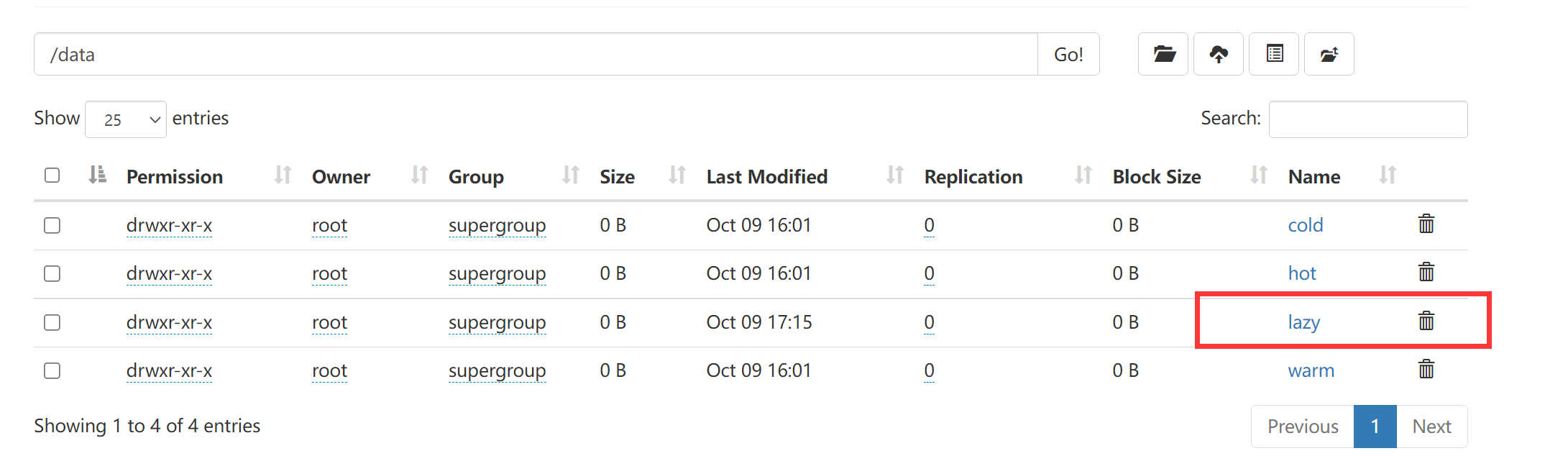
设置策略
hdfs storagepolicies -setStoragePolicy -path /data/lazy -policy LAZY_PERSIST
查看策略是否设置成功:
hdfs storagepolicies -getStoragePolicy -path /data/lazy

显然设置成功
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta