我正在尝试使用 node.js 来构建一些服务器端逻辑,并且已经实现了 here 中描述的菱形正方形算法的一个版本。在 CoffeeScript 和 Java 中。鉴于我听到的对 node.js 和 V8 性能的所有赞誉,我希望 node.js 不会落后于 java 版本太远。
但是在 4096x4096 的 map 上,Java 在 1 秒内完成,但 node.js/coffeescript 在我的机器上占用了 20 多秒...
这些是我的完整结果。 x 轴是网格大小。对数和线性图表:

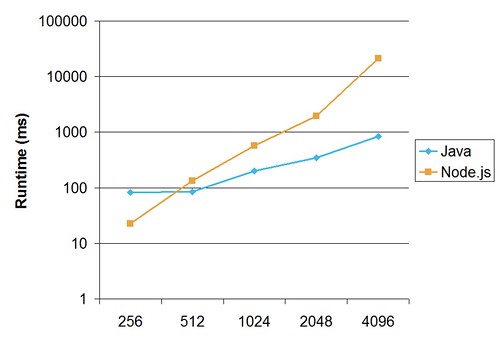
这是因为我的 coffeescript 实现有问题,还是这只是 node.js 的本质?
genHeightField = (sz) ->
timeStart = new Date()
DATA_SIZE = sz
SEED = 1000.0
data = new Array()
iters = 0
# warm up the arrays to tell the js engine these are dense arrays
# seems to have neligible effect when running on node.js though
for rows in [0...DATA_SIZE]
data[rows] = new Array();
for cols in [0...DATA_SIZE]
data[rows][cols] = 0
data[0][0] = data[0][DATA_SIZE-1] = data[DATA_SIZE-1][0] =
data[DATA_SIZE-1][DATA_SIZE-1] = SEED;
h = 500.0
sideLength = DATA_SIZE-1
while sideLength >= 2
halfSide = sideLength / 2
for x in [0...DATA_SIZE-1] by sideLength
for y in [0...DATA_SIZE-1] by sideLength
avg = data[x][y] +
data[x + sideLength][y] +
data[x][y + sideLength] +
data[x + sideLength][y + sideLength]
avg /= 4.0;
data[x + halfSide][y + halfSide] =
avg + Math.random() * (2 * h) - h;
iters++
#console.log "A:" + x + "," + y
for x in [0...DATA_SIZE-1] by halfSide
y = (x + halfSide) % sideLength
while y < DATA_SIZE-1
avg =
data[(x-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)][y]
data[(x+halfSide)%(DATA_SIZE-1)][y]
data[x][(y+halfSide)%(DATA_SIZE-1)]
data[x][(y-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)]
avg /= 4.0;
avg = avg + Math.random() * (2 * h) - h;
data[x][y] = avg;
if x is 0
data[DATA_SIZE-1][y] = avg;
if y is 0
data[x][DATA_SIZE-1] = avg;
#console.log "B: " + x + "," + y
y += sideLength
iters++
sideLength /= 2
h /= 2.0
#console.log iters
console.log (new Date() - timeStart)
genHeightField(256+1)
genHeightField(512+1)
genHeightField(1024+1)
genHeightField(2048+1)
genHeightField(4096+1)
import java.util.Random;
class Gen {
public static void main(String args[]) {
genHeight(256+1);
genHeight(512+1);
genHeight(1024+1);
genHeight(2048+1);
genHeight(4096+1);
}
public static void genHeight(int sz) {
long timeStart = System.currentTimeMillis();
int iters = 0;
final int DATA_SIZE = sz;
final double SEED = 1000.0;
double[][] data = new double[DATA_SIZE][DATA_SIZE];
data[0][0] = data[0][DATA_SIZE-1] = data[DATA_SIZE-1][0] =
data[DATA_SIZE-1][DATA_SIZE-1] = SEED;
double h = 500.0;
Random r = new Random();
for(int sideLength = DATA_SIZE-1;
sideLength >= 2;
sideLength /=2, h/= 2.0){
int halfSide = sideLength/2;
for(int x=0;x<DATA_SIZE-1;x+=sideLength){
for(int y=0;y<DATA_SIZE-1;y+=sideLength){
double avg = data[x][y] +
data[x+sideLength][y] +
data[x][y+sideLength] +
data[x+sideLength][y+sideLength];
avg /= 4.0;
data[x+halfSide][y+halfSide] =
avg + (r.nextDouble()*2*h) - h;
iters++;
//System.out.println("A:" + x + "," + y);
}
}
for(int x=0;x<DATA_SIZE-1;x+=halfSide){
for(int y=(x+halfSide)%sideLength;y<DATA_SIZE-1;y+=sideLength){
double avg =
data[(x-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)][y] +
data[(x+halfSide)%(DATA_SIZE-1)][y] +
data[x][(y+halfSide)%(DATA_SIZE-1)] +
data[x][(y-halfSide+DATA_SIZE-1)%(DATA_SIZE-1)];
avg /= 4.0;
avg = avg + (r.nextDouble()*2*h) - h;
data[x][y] = avg;
if(x == 0) data[DATA_SIZE-1][y] = avg;
if(y == 0) data[x][DATA_SIZE-1] = avg;
iters++;
//System.out.println("B:" + x + "," + y);
}
}
}
//System.out.print(iters +" ");
System.out.println(System.currentTimeMillis() - timeStart);
}
}
最佳答案
正如其他回答者所指出的,JavaScript 的数组是您正在执行的操作类型的主要性能瓶颈。因为它们是动态的,所以访问元素自然要比使用 Java 的静态数组慢得多。
好消息是,JavaScript 中的静态类型数组有一个新兴标准,已经在某些浏览器中得到支持。虽然 Node 本身还不支持,但您可以使用库轻松添加它们:https://github.com/tlrobinson/v8-typed-array
通过 npm 安装 typed-array 后,这是我修改后的代码版本:
{Float32Array} = require 'typed-array'
genHeightField = (sz) ->
timeStart = new Date()
DATA_SIZE = sz
SEED = 1000.0
iters = 0
# Initialize 2D array of floats
data = new Array(DATA_SIZE)
for rows in [0...DATA_SIZE]
data[rows] = new Float32Array(DATA_SIZE)
for cols in [0...DATA_SIZE]
data[rows][cols] = 0
# The rest is the same...
其中的关键行是data[rows]的声明。
使用 data[rows] = new Array(DATA_SIZE) 行(基本上等同于原来的),我得到了基准数字:
17
75
417
1376
5461
通过 data[rows] = new Float32Array(DATA_SIZE) 行,我得到
19
47
215
855
3452
这样一个小改动就可以将运行时间缩短约 1/3,即速度提高 50%!
它仍然不是 Java,但它是一个相当大的改进。预计 Node/V8 的 future 版本将进一步缩小性能差距。
警告:必须提到的是,普通的 JS 数字是 double 的,即 64 位 float 。因此,使用 Float32Array 会降低精度,使这有点像苹果和橘子的比较——我不知道使用 32 位数学能带来多少性能改进,以及有多少是从更快的阵列访问。 Float64Array 是 V8 规范的一部分,但尚未在 v8-typed-array 中实现图书馆。)
关于performance - Node.js/coffeescript 在数学密集型算法上的表现,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/7046509/
我目前对后台队列不太满意。我正在尝试让Resque工作。我已经安装了redis和Resquegem。Redis正在运行。一个worker正在运行(rakeresque:workQUEUE=simple)。使用Web界面,我可以看到工作人员正在运行并等待工作。当我运行“rakeget_updates”时,作业已排队但失败了。我已经用defself.perform和defperform试过了。发条.raketask:get_updates=>:environmentdoResque.enqueue(GetUpdates)end类文件(app/workers/get_updates.rb)c
我开始了一个新的Rails3.2.5项目,Assets管道不再工作了。CSS和Javascript文件不再编译。这是尝试生成Assets时日志的输出:StartedGET"/assets/application.css?body=1"for127.0.0.1at2012-06-1623:59:11-0700Servedasset/application.css-200OK(0ms)[2012-06-1623:59:11]ERRORNoMethodError:undefinedmethod`each'fornil:NilClass/Users/greg/.rbenv/versions/1
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
我有一个包含多个组件的存储库,其中大部分是用JavaScript(Node.js)编写的,一个是用Ruby(RubyonRails)编写的。我想要一个.travis.yml文件来触发一个运行每个组件的所有测试的构建。根据thisTravisCIGoogleGroupthread,目前还没有官方支持。我的目录结构是这样的:.├──构建服务器├──核心├──扩展├──网络应用├──流浪文件├──package.json├──.travis.yml└──生成文件我希望能够运行特定版本的Ruby(2.2.2)和Node.js(0.12.2)。我已经有了一个make目标,所以maketest在每
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。多年来,我一直在使用多种语言进行编程,并且认为自己总体上相当擅长。但是,我从未编写过任何自动化测试:没有单元测试,没有TDD,没有BDD,什么都没有。我已经尝试开始为我的项目编写适当的测试套件。我可以看到在进行任何更改后能够自动测试项目中所有代码的理论值(value)。我可以看到像RSpec和Mocha这样的测试框架应该如何使设置和运行所述测试变得相当容易
情况:我正在编写一个程序来求解素数。我需要解决4x^2+y^2=n的问题,其中n是一个已知变量。是的,必须是Ruby。我愿意在这个项目上花费大量时间。我最好自己编写方程式的求解算法,并将其作为该项目的一部分。我真正喜欢的是:如果任何人都可以向我提供指南、网站的链接,或者关于与求解代数方程特别相关的形式算法的构造的歧义消除,或者向我提供似乎你是读者它会帮助我完成任务。请不要建议我使用其他语言。如果您在回答之前接受我真的非常想这样做,我将不胜感激。该项目没有范围或时间限制,也不以营利为目的。这是为了我自己的教育。注意:我并不直接反对为Ruby实现和使用现存的数学库/模块/其他东西,但我更喜
我需要一些指导来了解如何将Angular整合到rails中。选择Rails的原因:我喜欢他们偏执的做事方式。还有迁移,gem真的很酷。使用angular的原因:我正在研究和寻找最适合SPA的框架。Backbone似乎太抽象了。我不得不在Angular和Ember之间做出选择。我首先开始阅读Angular,它对我来说很有意义。所以我从来没有去读过关于ember的文章。使用Angular和Rails的原因:我研究并尝试使用小型框架,例如grape、slim(是的,我也使用php)。但我觉得需要坚持项目的长期范围。我个人喜欢用Rails的方式做事。这就是我需要帮助的地方,我在Rails4中有
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub
目标:我想从动画GIF中抓取最佳帧并将其用作静态预览图像。我相信最好的帧是显示最多内容的帧-不一定是第一帧或最后一帧。以这张动图为例:--这是第一帧:--这是第28帧:很明显,第28帧很好地代表了整个GIF。我如何以编程方式确定一帧是否比另一帧具有更多像素/内容?如果您能向我指出任何想法、想法、包/模块或文章,我们将不胜感激。 最佳答案 实现此目的的一种直接方法是估计entropy每个图像的帧,并选择具有最大熵的帧。在信息论中,熵可以被认为是图像的“随机性”。单一颜色的图像是非常可预测的,分布越平坦,越随机。这与Arthur-R描述