前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:https://www.captainai.net/dongkelun
前面总结了Spark SQL增量查询Hudi表和Hive增量查询Hudi表。最近项目上也有Flink SQL增量查询Hudi表的需求,正好学习总结一下。
地址:https://hudi.apache.org/cn/docs/querying_data#incremental-query
我这里建表造数使用Hudi Spark SQL 0.9.0,目的是为了模拟项目上用Java Client和Spark SQL创建的Hudi表,以验证Hudi Flink SQL增量查询时是否兼容旧版本的Hudi表(大家没有这种需求的,可以使用任何方式正常造数)
-- Spark SQL Hudi 0.9.0
create table hudi.test_flink_incremental (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
preCombineField = 'ts',
type = 'cow'
);
insert into hudi.test_flink_incremental values (1,'a1', 10, 1000, '2022-11-25');
insert into hudi.test_flink_incremental values (2,'a2', 20, 2000, '2022-11-25');
update hudi.test_flink_incremental set name='hudi2_update' where id = 2;
insert into hudi.test_flink_incremental values (3,'a3', 30, 3000, '2022-11-26');
insert into hudi.test_flink_incremental values (4,'a4', 40, 4000, '2022-12-26');
用show_commits看一下有哪些commits(这里查询用的是Hudi的master,因为show_commits是在0.11.0版本开始支持的,也可以通过使用hadoop命令查看.hoodie文件夹下的.commit文件)
call show_commits(table => 'hudi.test_flink_incremental');
20221205152736
20221205152723
20221205152712
20221205152702
20221205152650
CREATE TABLE test_flink_incremental (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
price double,
ts bigint,
dt VARCHAR(10)
)
PARTITIONED BY (dt)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://cluster1/warehouse/tablespace/managed/hive/hudi.db/test_flink_incremental'
);
建表时不指定增量查询相关的参数,我们在查询时动态指定,这样比较灵活。
动态指定参数方法,在查询语句后面加上如下形式的语句
/*+
options(
'read.start-commit' = '20221205152723',
'read.end-commit'='20221205152736'
)
*/
Flink SQL读Hudi有两种模式:批读和流读。默认批读,先看一下批读的增量查询
select * from test_flink_incremental
/*+
options(
'read.start-commit' = '20221205152723' --起始时间对应id=3的记录
)
*/
结果包含起始时间,不指定结束时间默认读到最新的数据
id name price ts dt
4 a4 40.0 4000 dt=2022-12-26
3 a3 30.0 3000 dt=2022-11-26
select * from test_flink_incremental
/*+
options(
'read.start-commit' = '20221205152712', --起始时间对应id=2的记录
'read.end-commit'='20221205152723' --结束时间对应id=3的记录
)
*/
结果包含结束时间
id name price ts dt
3 a3 30.0 3000 dt=2022-11-26
2 hudi2_update 20.0 2000 dt=2022-11-25
这种情况是指定结束时间,但不指定开始时间,如果都不指定,则读表所有的最新版本的记录。
select * from test_flink_incremental
/*+
options(
'read.end-commit'='20221205152712' --结束时间对应id=2的更新记录
)
*/
结果:只查询end-commit对应的记录
id name price ts dt
2 hudi2_update 20.0 2000 dt=2022-11-25
验证是否可以查询历史记录,我们更新id为2的name,更新前name为a2,更新后为hudi2_update,我们验证一下,是否可以通过Flink SQL查询Hudi历史记录,逾期结果查出id=2,name=a2
select * from test_flink_incremental
/*+
options(
'read.end-commit'='20221205152702' --结束时间对应id=2的历史记录
)
*/
结果:可以正确查询历史记录
id name price ts dt
2 a2 20.0 2000 dt=2022-11-25
开启流读的参数:
read.streaming.enabled = true
流读不需要设置结束时间,因为一般的需求是读所有的增量数据,我们只需要验证开始时间就好了
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4'
)
*/
结果:从最新的instantTime开始增量读取,也就是默认的read.start-commit为最新的instantTime
id name price ts dt
4 a4 40.0 4000 dt=2022-12-26
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20221205152712'
)
*/
结果:
id name price ts dt
2 hudi2_update 20.0 2000 dt=2022-11-25
3 a3 30.0 3000 dt=2022-11-26
4 a4 40.0 4000 dt=2022-11-26
如果想第一次查询全部的历史数据,可以将start-commit设置的早一点,比如设置到去年:‘read.start-commit’ = ‘20211205152712’
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20211205152712'
)
*/
id name price ts dt
1 a1 10.0 1000 dt=2022-11-25
2 hudi2_update 20.0 2000 dt=2022-11-25
3 a3 30.0 3000 dt=2022-11-26
4 a4 40.0 4000 dt=2022-11-26
验证新的增量数据进来,是否可以持续消费Hudi增量数据,验证数据的准确一致性,为了方便验证,我可以使用Flink SQL增量流读Hudi表然后Sink到MySQL表中,最后通过读取MySQL表中的数据验证数据的准确性
Flink SQL读写MySQL需要配置jar包,将
flink-connector-jdbc_2.12-1.14.3.jar放到lib下即可,下载地址:https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.12/1.14.3/flink-connector-jdbc_2.12-1.14.3.jar
先在MySQL中创建一张Sink表
-- MySQL
CREATE TABLE `test_sink` (
`id` int(11),
`name` text DEFAULT NULL,
`price` int(11),
`ts` int(11),
`dt` text DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Flink中创建对应的sink表
create table test_sink (
id int,
name string,
price double,
ts bigint,
dt string
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.468.44.128:3306/hudi?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8',
'username' = 'root',
'password' = 'root-123',
'table-name' = 'test_sink',
'sink.buffer-flush.max-rows' = '1'
);
然后流式增量读取Hudi表Sink Mysql
insert into test_sink
select * from test_flink_incremental
/*+
options(
'read.streaming.enabled'='true',
'read.streaming.check-interval' = '4',
'read.start-commit' = '20221205152712'
)
*/
这样会起一个长任务,一直处于running状态,我们可以在yarn-session界面上验证这一点
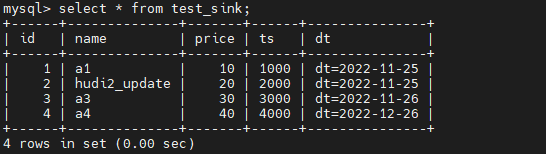
然后先在MySQL中验证一下历史数据的准确性
再利用Spark SQL往source表插入两条数据
-- Spark SQL
insert into hudi.test_flink_incremental values (5,'a5', 50, 5000, '2022-12-07');
insert into hudi.test_flink_incremental values (6,'a6', 60, 6000, '2022-12-07');
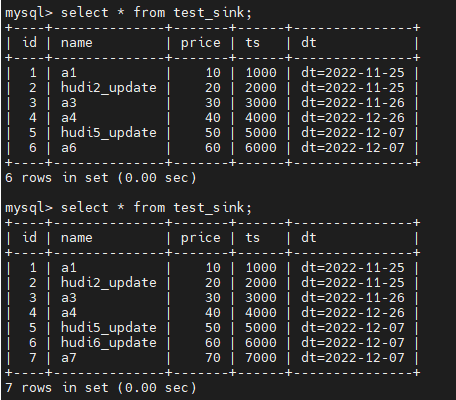
我们增量读取的间隔设置的4s,成功插入数据等待4s后,再在MySQL表中验证一下数据
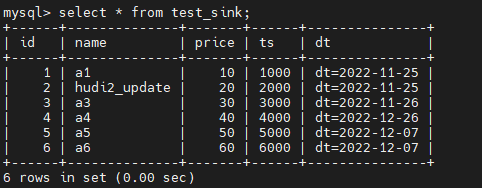
发现新增的数据已经成功Sink到MySQL中了,并且数据没有重复
最后验证一下更新的增量数据,Spark SQL更新Hudi source表
-- Spark SQL
update hudi.test_flink_incremental set name='hudi5_update' where id = 5;
继续验证结果
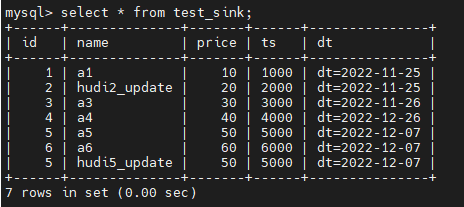
结果是更新的增量数据也会insert到MySQL中的sink表,但是不会更新原来的数据
那如果想实现更新的效果呢?我们需要在MySQL和Flink的sink表中加上主键字段,两者缺一不可,如下:
-- MySQL
CREATE TABLE `test_sink` (
`id` int(11),
`name` text DEFAULT NULL,
`price` int(11),
`ts` int(11),
`dt` text DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Flink SQL
create table test_sink (
id int PRIMARY KEY NOT ENFORCED,
name string,
price double,
ts bigint,
dt string
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.468.44.128:3306/hudi?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8',
'username' = 'root',
'password' = 'root-123',
'table-name' = 'test_sink',
'sink.buffer-flush.max-rows' = '1'
);
将刚才起的长任务关掉,重新执行刚才的insert语句,先跑一下历史数据,最后再验证一下增量效果
-- Spark SQL
update hudi.test_flink_incremental set name='hudi6_update' where id = 6;
insert into hudi.test_flink_incremental values (7,'a7', 70, 7000, '2022-12-07');
可以看到,达到了预期效果,对于id=6的执行更新操作,对于id=7的执行插入操作。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf
我正在寻找一种方便实用的方法来将编码值添加到Ruby中的URL查询字符串。目前,我有:require'open-uri'u=URI::HTTP.new("http",nil,"mydomain.example",nil,nil,"/tv",nil,"show="+URI::encode("Rosie&Jim"),nil)pu.to_s#=>"http://mydomain.example/tv?show=Rosie%20&%20Jim"这不是我要找的,因为我需要得到“http://mydomain.example/tv?show=Rosie%20%26%20Jim”,这样show=值就