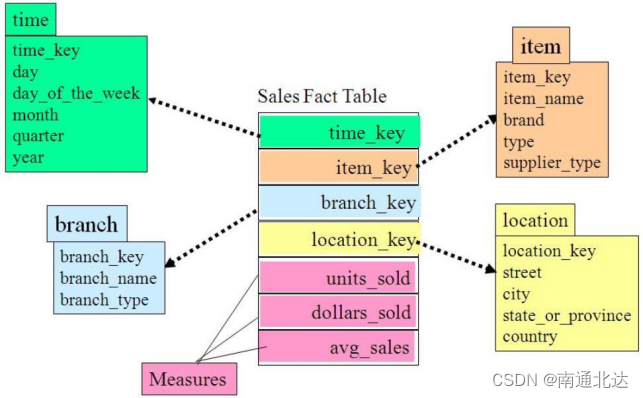
星型模式是维度模型中最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。
星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维度表。
星型模式的物理模型像一颗星星的形状,中心是一个事实表, 围绕在事实表周围的维度表表示星星的放射状分支,这就是星型模式这个名字的由来。
星型模式将业务流程分为事实和维度。事实包含业务的度量,是定量的数据,如销售价格、销售数量、距离、速度、重量等是事实。维度是对事实数据属性的描述,如日期、产品、客户、地理位置等是维度。一个含有很多维度表的星型模式有时被称为蜈蚣模式,显然这个名字也是因其形状而得来的。蜈蚣模式的维度往往只有很少的几个属性,这样可以简化对维度表的维护,但查询数据时会有更多的表连接,严重时会使模型难于使用,因此在设计中应该尽量避免蜈蚣模式。
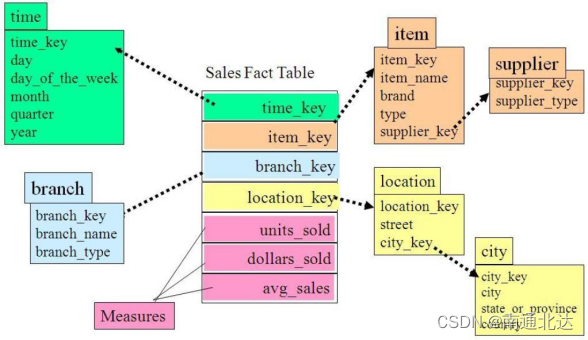
雪花模式是一种多维模型中表的逻辑布局,其实体关系图有类似于雪花的形状,因此得名。
与星型模式相同,雪花模式也是由事实表和维度表所组成。所谓的“雪花化”就是将行星模型中的维度表进行规范化处理。当所有的维度表完成规范化后,就形成了以事实表为中心的雪花型结构,即雪花模式。将维度表进行规范化的具体做法是,把低基数的属性从维度表中移除并形成单独的表。基数指的是一个字段中不同值的个数,如主键列具有唯一值, 所以有最高的基数,而像性别这样的列基数就很低。
在雪花模式中,一个维度被规范化成多个关联的表,而在星型模式中,每个维度由一个单一的维度表所表示。一个规范化的维度对应一组具有层次关系的维度表,而事实表作为雪花模式里的字表,存在具有层次关系的多个父表。
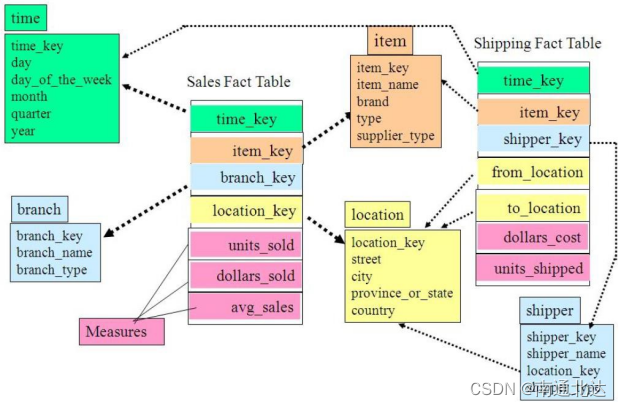
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
在数据仓库建模时,会涉及到模式的选择,我们要根据不同模式的特点选择适合具体业务的模式:
冗余:雪花模型符合业务逻辑设计,采用 3NF 设计,有效降低数据冗余;星型模型的维度表设计不符合 3NF(如果是雪花模型改造成了星型模型,那么肯定不符合 3NF,因为一定发生了表的整合,即降维,一定有传递依赖,但是,并不是所有的星型模型都不符合
3NF,很多星型模型的表是符合 3NF 的),反规范化,维度表之间不会直接相关,牺牲部分存储空间。(雪花模型的维度之间是有关联的)
性能:雪花模型由于存在维度间的关联,采用 3NF 降低冗余,通常在使用过程中,需要连接更多的维度表,导致性能偏低;星型模型反三范式,采用降维的操作将维度整合,以存储空间为代价有效降低维度表连接数,性能较雪花模型高。( 星型表的数据冗余大,是用存储空间换取效率 )( BI 的一些工具对于星型模型的支持更规范化 )
ETL:雪花模型符合业务 ER 模型设计原则,在 ETL 过程中相对简单,但是由于附属模型的限制,ETL 任务并行化较低(由于雪花模型中有很多的维度依赖,在 ETL 的时候, 需要在保持 3NF 的前提下对数据进行清洗,即对数据一致性/规范化的处理,例如数据来自于多个业务系统,各个系统对于用户的定义不一致,此时要对每个业务定义的用户数据进行规范化处理,在 3NF 的限制下必然会降低并行度);星型模型在设计维度表时反范式设计,所以在 ETL 过程中整合业务数据到维度表有一定难度,但由于避免附属维度,可并行化处理(不用关注太多的关联关系,避免了维度表之间的关联关系,并行度较高,注意,一般场景下星型模型的并行化程度更高,并不是所有场景)。
Hive 的分析通过 MapReduce 实现,每多一个 Join 就会多出一个 MapReduce 过程,对于雪花模型,由于存在着很多维度表之间的关联,这就会导致一次分析对应多个 MapReduce 任务,而星型模型由于不存在维度表的关联,因此一个 MapReduce 就可以实现分析任务。
MapReduce 本身是一个支持高吞吐量的任务,它的每个任务都要申请资源、分配容器、节点通信等待,需要 YARN 的调度,由于相互关联的维度表本身会很小,join 操作用时很少,
YARN 调度的时长可能都大于实际运算的时长,因此我们要尽可能减少任务个数,对于 Hive 来说就是尽可能减少不必要的表的关联。还有一点,雪花模型中拆分出的维度表,每个表对应至少一个文件,这就涉及到 I/O 方面的性能损耗。
因此,我们要采用适当的数据冗余,避免不必要的表之间的关联。
在实际项目中,不会刻意地去考虑雪花模型,而是刻意地去考虑星型模型,特别是大数据领域的建模,倾斜于使用数据冗余来提高查询效率,倾向于星型模型;雪花模型只会应用在一些我们要求模型的灵活性,要求保证模型本身稳定性的场景下,但是雪花模型并不是首选。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
是否可以让这段代码更紧凑?我在这里错过了什么吗?ifvaluemax_ratemax_rateelsevalueend 最佳答案 这里有一些完全不同的东西:[min_rate,value,max_rate].sort[1] 关于ruby-如何更优雅地记下这三种情况?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/13309740/
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo