"Writing in C or C++ is like running a chain saw with all the safety guards removed. " - Bob Gray
“用C或C++写代码就像是在挥舞一把卸掉所有安全防护装置的链锯。” —— 鲍勃·格雷
学生管理系统、学生成绩管理系统、教师管理系统、图书管理系统、通讯录管理系统、进销存管理系统……这一个个耳熟能详的名字,正是无数C语言练习生除了唱、跳、RAP和篮球之外,必须迈过去的一道坎,无论是作为课程设计,还是期末作业,都坑倒了一大批新手。照着书上的例程修修改改就是跑不通,网上查到的代码比自己写的还不靠谱……毕竟老夫也是渡过此劫的魔鬼。
其中很大一部分原因就是因为XXX管理系统的核心数据结构——链表,没有int、long和char这些基础数据类型长得那么可爱单纯,让人学起来一脸辛酸。
简单的链表大家都会,这边文章要讲的其实是Linux的内核链表,拿个旧瓶装点新酒。
链表是线性表的一种。它通过指针将一系列数据节点连接成一条数据链,相对于静态数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随机分配空间,可以高效地在链表中插入数据。
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点,因此,对单链表的遍历只能从头至尾顺序进行。尾节点指针域通常指向NULL空指针。

双链表在单链表的基础上增加了一个指向前驱节点的指针域,可以实现双向遍历。

循环链表的尾节点指针域指向首节点。它的特点是从任意节点出发,都可以访问到整个链表。如果在双链表的基础上实现循环链表,则可以实现从任意节点双向访问整个链表。

链表的节点通常由数据域和指针域构成,以喜闻乐见的学生管理系统为例:
struct student
{
char id[48];
char name[64];
char clazz[24];
}
struct list_node
{
struct student data; // 数据域
struct list_node *next;// 指针域
}
void list_init(struct list_node *list);
void list_add(struct list_node *list, struct student *stu);
void list_del(struct list_node *list, struct student *stu);
......
可以看到,这样的链表对于维护单一数据来说,比如上面的struct student,没有任何问题,但如果在另一个程序上下文中,我们的数据域不是struct student,而是struct teacher或者struct any_thing,显然,我们必须为这些不同的数据类型重新定义一套链表的操作接口,我们的代码没办法完全复用(Ctrl+C,Ctrl+V)。简而言之,我们需要一个通用的链表。
要实现一个通用的链表,我们首先要将数据和结构解耦,这也是实现任意一种抽象数据类型的基础。很遗憾,C语言既没有C++的模板,也没有C#和Java的泛型。但是我们可以考虑这样的结构:
struct list_node
{
void *data; // 数据域
struct list_node *next;// 指针域
}
void list_init(struct list_node *list);
void list_add(struct list_node *list, void *data);
void list_del(struct list_node *list, void *data);
......
无类型的指针,可以实现某种程度上的抽象数据类型,但是这意味着我们代码会到处充斥强制转换和回调函数,必须时刻注意自行检查数据类型,一个不小心就会发生内存错误。
显然,这不是我们想要的。我们向Linux内核的链表实现取下经,既然是一个与数据解耦的链表,那这个链表的节点不应该包含数据域本身,像这样:
struct list_node
{
struct list_node *next, *prev;// 仅有指针域
}
节点里面仅包含了指向前驱节点和后继节点的指针,那么我们的数据存放在哪里呢?
还是以学生管理系统为例,我们把代码调整一下,将链表的节点放在数据结构体内,这样,抽象(链表结构)不再依赖于细节(数据类型),细节(数据类型)依赖于抽象(链表结构),利用依赖倒置的思想,完成了数据与结构的解耦。如下:
struct list_node
{
struct list_node *next, *prev;
}
struct student {
char id[48];
char name[64];
char clazz[24];
struct list_node list;// 链表节点反置于数据结构体内
}
void list_init(struct list_node *list);
void list_add(struct list_node *new_node, struct list_node *head);
void list_del(struct list_node *node);
......
可以发现,对比之前的代码,进行调整之后,我们的链表操作函数中不再关心数据结构体struct student的具体细节,所有的操作都基于struct list_node链表节点,也就是说,我们可以轻松的将struct student替换成struct teacher,而不用修改链表操作的任何代码。
用一张普通链表和通用链表的节点对比图可以更直观的看出两者在结构上的差异,对于普通链表来说,节点本身包含了数据,对节点的操作是对数据域和指针域整体的操作;对于通用链表来说,则是数据本身包含了节点,对节点的操作只与局部的指针域有关,与数据域无关。
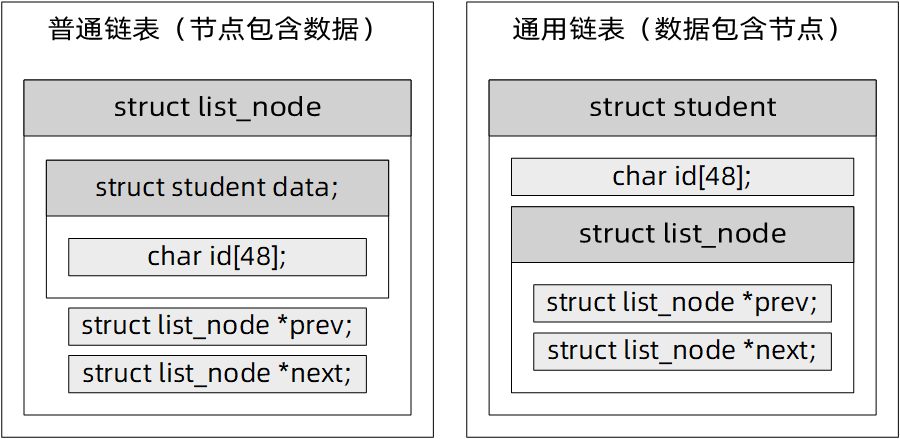
经过上面的调整,我们确立了通用链表的实现方向,但是随之而来的是新的问题:如何通过链表节点list_node取得对应的数据成员struct student?我们的标题提出了解决方法,答案就是利用地址偏移。
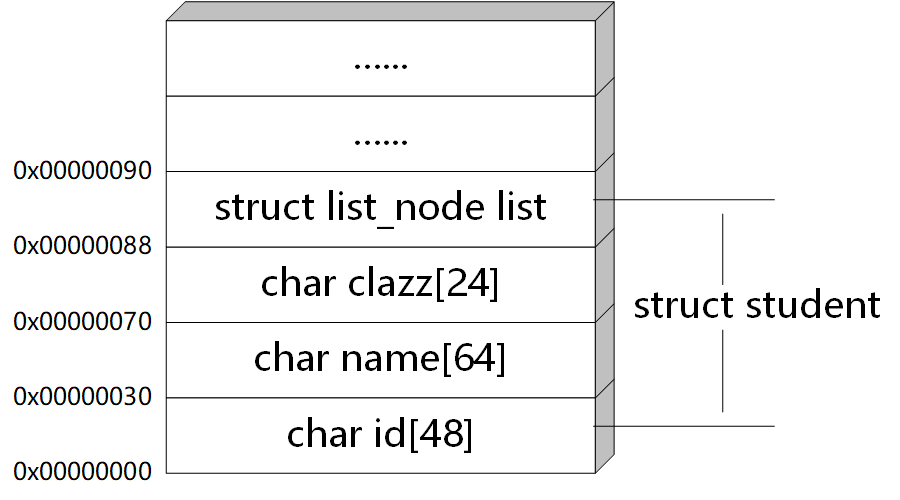
如图,我们知道结构体的指针指向的是该结构体在内存中的起始地址,不妨假设结构体类型(type)为struct student的数据存储在内存的 0x00000000 到 0x00000090 单元, 0x00000088 到 0x00000090 单元存储的是类型为struct list_node的结构体成员(member)list,注意编址从下往上逐渐增大,如果已知成员的起始地址,那么该成员相对于结构体的偏移量(offset)为 0x00000088 - 0x00000000 = 136。显然,我们可以得出以下公式:
结构体起始地址 = 成员起始地址 - 成员在结构体的偏移量
有了上面的公式,还需要知道如何获取成员在结构体的偏移量。offsetof 是定义在C标准库头文件<stddef.h>中的一个宏,它会生成一个类型为size_t的无符号整型,代表一个结构成员相对于结构体起始的字节偏移量(offset)。一种可能的写法为:
#define offsetof(type, member) ((size_t) &((type *)0)->member)
其中member表示的是结构体成员的名称,type表示的是结构体的类型,这里我们以struct student为例,如果要得到成员list相对于结构体struct student的偏移量:
// 注意list必须与在结构体中定义的变量名称一致
int offset = offsetof(struct student, list);
// 将宏展开得到
int offset = ((size_t) &((struct student *)0)->list);
把表达式分解一下,可以得到:
(1)(struct student *)0,将0强制转换为struct student结构体指针类型,可以理解为将该结构体指针偏移到0地址
(2)((struct student *)0)->list),通过指针访问结构体成员list
(3)&((struct student *)0)->list),对结构体成员member进行取地址运算,获得结构体成员的地址
(4)(size_t) &((struct student *)0)->list,将结构体地址强制转换为无符号整型表示的数值
由于我们将结构体起始地址偏移到了0地址,所以成员list的地址数值上就等于list相对于结构体起始地址的偏移量,这是一个常量,它在编译期间就可以被替换为具体的数值,而不用在运行时动态计算,因此,在某些编译器中,它会被定义为编译器内建实现,比如GCC编译器<stddef.h>中offsetof宏的定义如下:
#define offsetof(TYPE, MEMBER) __builtin_offsetof (TYPE, MEMBER)
它们得到的结果是一致的,这不会影响我们对原理的理解。
我们将求取成员偏移量的offsetof宏代入上面的公式,得到另一个宏cotainer_of:
#define container_of(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type,member)))
cotainer_of返回的是结构体成员所在结构体的起始地址(指针),其中ptr为指向结构体成员的指针(相当于成员的起始地址),type表示的是结构体的类型,member表示的是结构体成员的名称。老规矩,继续以struct student为例,便于理解:
......
struct student *ptr_of_stu;
// 通过成员list的指针ptr_of_list_node获取结构体指针ptr_of_stu
ptr_of_stu = container_of(ptr_of_list_node, struct student, list);
// 将宏展开后得到(offsetof前面已经分析过,这里就不赘述了)
ptr_of_stu = ((struct student *)((char *)(ptr_of_list_node) - offsetof(struct student,list)));
......
ptr_of_stu->id = "996";
......
把表达式分解一下,可以得到:
(1)offsetof(struct student,list),获得成员list在结构体struct student中的偏移量
(2)(char *)(ptr_of_list_node),将节点指针强制转换为字符型指针,保证计算结果正确,当指针变量进行运算时,会前进或后移相应类型数据的宽度,之所以进行转换是要确保我们的偏移量都是按字节计算的偏移量
(3)(char *)(ptr_of_list_node) - offsetof(struct student,list)),用成员变量指针(起始地址)减去成员的结构体偏移量,得到结构体的指针(起始地址),也即是公式的体现
(4)(struct student *)((char *)(ptr_of_list_node) - offsetof(struct student,list)),将计算得到的指针强制转换为struct student类型指针
到这里,我们就解决了如何通过链表节点list_node取得对应的数据成员struct student的问题。接下来只需要将链表的常用操作封装起来,就能够得到一个与具体数据类型无关的通用链表。
我们似乎花了很大的功夫去调整链表的节点,不禁要问,why? 像教科书例程一样简单粗暴地定义结构体类型和指针不好吗?好,但是也不好。好的地方是,代码直观,容易理解和操作。不好的地方呢?假设我们要写一个“教务管理系统”,它需要同时维护两种信息:学生信息和教师信息。我们用链表存储他们的所有数据,那么以插入数据为例:
struct student
{
char id[48];
}
struct teacher
{
char id[48];
}
struct student_node
{
struct student *data;// 普通链表,数据放在节点内
struct student_node *prev;
struct student_node *next;
}
struct teacher_node
{
struct teacher *data;// 普通链表,数据放在节点内
struct teacher_node *prev;
struct teacher_node *next;
}
// 普通链表插入一个节点
void list_add_student(struct student_node *head, struct student *data)
{
struct student_node *entry = (struct student_node *)malloc(sizeof(struct student_node));
entry->data = data;
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 普通链表插入一个节点
void list_add_teacher(struct teacher_node *head, struct teacher *data)
{
// 为节点申请内存
struct teacher_node *entry = (struct teacher_node *)malloc(sizeof(struct teacher_node));
entry->data = data;
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 插入操作
struct student_node *student_head; // 假设链表已经初始化
struct teacher_node *teacher_head; // 假设链表已经初始化
struct student new_student; // 省略结构体成员赋值
struct teacher new_teacher; // 省略结构体成员赋值
list_add_student(student_head, &new_student);
list_add_teacher(teacher_head, &new_teacher);
看到了吗,每增加一种数据类型,就必须多定义一套操作函数,代码成倍增加不说,还必须注意类型不能混用,否则分分钟一个大大的内存错误扔给你。我们看看通用链表可以怎么做:
struct list_node
{
struct list_node *next, *prev;
}
struct student
{
char id[48];
struct list_node; // 通用链表,节点放置在数据结构体内
}
struct teacher
{
char id[48];
struct list_node; // 通用链表,节点放置在数据结构体内
}
// 通用链表插入一个节点
void list_add(struct list_node *new_node, struct list_node *head)
{
// 由于节点随着数据结构体一起被分配,这里不需要再动态申请内存
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 插入操作
struct list_node *student_head; // 假设链表已经初始化
struct list_node *teacher_head; // 假设链表已经初始化
struct student new_student; // 省略结构体成员赋值
struct student new_teacher; // 省略结构体成员赋值
list_add(student_head, &new_student.list_node);
list_add(teacher_head, &new_teacher.list_node);
注意,上述的代码只是为了对比和说明普通链表与通用链表的泛用性,省略了很多初始化和检查代码,不能直接使用。从代码可以知道,通用链表的list_add函数只需要被定义一次,就可以被用于任意数据类型,只需要在数据结构体内包含list_node结构体,该结构体类型便可以作为链表节点进行管理。
对于通用链表的各种基本操作和代码示例,将在下一篇文章中进行展开和说明。期待与你下次再见。
前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息)【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客目录前言一、带头双向循环链表是什么?二、实现带头双向循环链表1.结构体和要实现函数2.初始化和打印链表3.头插和尾插4.头删和尾删5.查找和返回结点个数6.在pos位置之前插入结点7.删除指定pos结点8.摧毁链表三、完整代码1.DSLinkList.h2.DSLinkList.c3.test.c总结前言带头双向循环链表,是链表中最为复杂的一种结
我在网上查了几个Ruby教程,他们似乎什么都用数组。那么如何在Ruby中实现以下数据结构呢?堆栈队列链表map组 最佳答案 (从评论中移出)好吧,通过限制堆栈或队列方法(push、pop、shift、unshift),数组可以是堆栈或队列。使用push/pop提供LIFO(后进先出)行为(堆栈),而使用push/shift或unshift/pop提供FIFO行为(队列)。map是hashes,和一个Set类已经存在。您可以使用类实现链表,但数组将使用标准数组方法提供类似于链表的行为。 关
我是JS的新手,组织数据的概念让我有些困惑,我试图从特定的数组格式中获取数据(因为这是我必须使用的格式)并将其输出为另一种特定的JSON格式。这是给D3sankey模块传递数据https://github.com/d3/d3-plugins/blob/master/sankey/sankey.js我不知道如何将节点的索引添加到链接中,而不是名称。真的,我完全迷失了它!我在这里做了一个fiddle:https://jsfiddle.net/adamdavi3s/kw3jtzx4/下面是所需数据和输出的示例vardata=[{"source":"Agricultural'waste'","
文章目录1.题目描述2.解题思路方法1:方法2:1.题目描述题目链接:力扣21,合并两个有序链表将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。2.解题思路方法1:首先我们能够想到的就是遍历一遍数组,判断两个结点的大小,将数值小的结点放在前面,数值大的不断尾插在后面。是不是听着挺简单的?具体实现:我们可以创建两个空指针,head用来存放链表的头结点,tail用来遍历两条链表,将两条链表链接起来。当某个链表为空时,我们可以直接返回另一条链表当两个链表都不为空时,我们可以不断比较两条链表的大小,当head和tail为空时,我们将较小的结点同时赋给head
所以我在JS中玩弄链表并提出了以下问题:比方说,我们有一个数组和一个链表,它们都有5000个元素。我们想在索引10处插入新元素。数组方式非常简单。我们在给定索引处插入新元素,并将其余元素向前移动一个索引。所以我尝试用链表来做这件事,并以下面的方式结束它:从NicholasZakas获取链表的实现并添加附加方法addOnPosition(data,index)。最后是代码:functionLinkedList(){this._head=null;this._length=0;}LinkedList.prototype={constructor:LinkedList,add:functio
✨个人主页:bitme✨当前专栏:数据结构✨刷题专栏:基础算法链表OJ🏳️一.移除链表元素🏴二.反转链表🏁三.链表的中间结点🚩四.链表中倒数第k个结点🏳️🌈五.合并两个有序链表🏳️⚧️六.链表的回文结构🏴☠️七.链表分割🏴八.相交链表🏳️🌈九.环形链表🍹十.环形链表II 🏳️一.移除链表元素简介:给你一个链表的头节点head和一个整数val,请你删除链表中所有满足Node.val==val的节点,并返回新的头节点。示例1:输入:head=[1,2,6,3,4,5,6],val=6输出:[1,2,3,4,5]示例2:输入:head=[],val=1输出:[]示例3:输入:he
我正在学习Go并编写了以下代码来反转链表。但是,代码没有按预期工作。这是一个节点结构以及用于打印和反转列表的函数。typeNodestruct{numberintprevious*Nodenext*Node}funcPrintList(node*Node){forn:=node;n!=nil;n=n.next{fmt.Println(n)}}funcReverseList(node*Node){varnextNodeRef*Nodeforn:=node;n!=nil;n=n.previous{ifn.next==nil{n.next=n.previousn.previous=nil*n
魔王的介绍:😶🌫️一名双非本科大一小白。魔王的目标:🤯努力赶上周围卷王的脚步。魔王的主页:🔥🔥🔥大魔王.🔥🔥🔥❤️🔥大魔王与你分享:很喜欢宫崎骏说的一句话:“不要轻易去依赖一个人,它会成为你的习惯当分别来临,你失去的不是某个人而是你精神的支柱,无论何时何地,都要学会独立行走,它会让你走得更坦然些。”文章目录一、前言二、链表实现1、创建结构体类型2、创建结点3、打印单链表4、单链表尾插5、单链表头插6、单链表尾删7、单链表头删8、单链表查找9、单链表插入☃️该位置之后插入☃️该位置之前插入(插入正常理解)10、单链表删除11、单链表销毁三、总代码SeqListNode.hSeqListNod
对于我正在处理的一项任务,我们被指示创建两个实现Stack接口(interface)(包括push、pop等方法)的数据结构。当我完成第一个结构时,链表部分让我不知所措。作为正在编写他们的第一个Go项目的人,我不确定如何处理以下指令:1.创建一个名为StackLinked的新结构,它实现了Stacker,并使用单(或双)链表作为其内部表示。2.除了实现Stacker中的所有方法外,还编写一个makeStackLinked()函数(不是方法!),该函数使用链表表示返回一个新的空堆栈我曾尝试这样实现:typeStackLinkedstruct{top*StackLinkednext*Sta
我的问题是,当我将head指向head.next时input.Val仍然是1而不是2(这是下一个值)。typeListNodestruct{ValintNext*ListNode}functest(head*ListNode)*ListNode{head=head.Nextreturnhead}funcmain(){varinput,input2ListNodeinput=ListNode{Val:1,Next:&input2}}input2=ListNode{Val:2}test(&input)fmt.Println(input.Val)} 最佳答案