
文 | 智商掉了一地
你有没有想过,让一台计算机诊断和修复自己生成的错误代码?一篇最新的研究论文介绍了一种名为 Self-Debugging 的技术,通过在生成的代码中添加自解释的信息,让计算机像一个可以自己修复代码的程序员一样调试自己的 BUG。
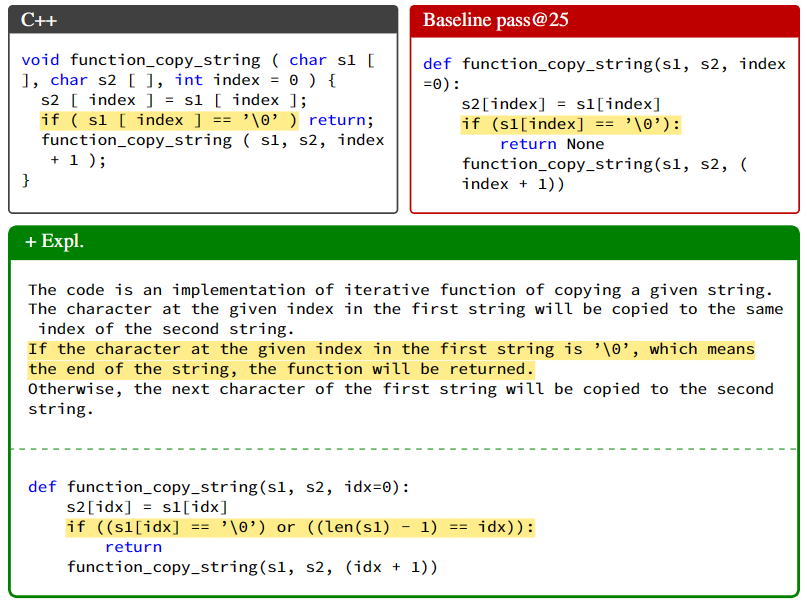
随着大型语言模型(LLMs)在代码生成领域的不断发展,取得了令人瞩目的性能。然而在面对复杂的编程任务时,一次性生成正确的解决方案变得越来越具有挑战性。为了解决这一问题,先前的研究提出了一些代码修复方法来改善代码生成性能。而在本篇论文中,作者提出了一种名为 Self-Debugging 的方法,通过少量示范来教大型语言模型调试它所生成的代码。
该研究表明,Self-Debugging 方法可以教大型语言模型进行橡皮鸭调试,即在没有任何关于代码正确性或错误信息的反馈的情况下,通过自然语言解释生成的代码来识别其错误,这种方法对于提升代码生成性能具有潜在的巨大价值。
为了验证 Self-Debugging 方法的有效性,作者在多个代码生成基准测试上进行了实验,包括文本到 SQL 生成、C++ 到 Python 翻译和文本到 Python 生成。该方法不仅在提升预测准确性方面表现出色,同时还在样本效率上获得了显著的改进,通过利用反馈信息和重用失败的预测,能在样本效率上具有优势,并且在与生成超过 10 倍候选代码的基线模型相比时,能够取得匹敌甚至超越的表现。
综上所述,这篇文章提出的 Self-Debugging 方法为解决复杂编程任务中代码生成困难的问题提供了一种新颖且有效的解决方案。这一研究将为解决复杂编程任务中代码生成的难题带来了新的可能性,对推动大型语言模型在代码生成领域的应用和发展提供了有力支持。
论文题目:
Teaching Large Language Models to Self-Debug
论文链接:
https://arxiv.org/abs/2304.05128
近期的大型语言模型在生成代码方面有了显著的改进,但生成正确的代码仍然具有挑战性。研究表明从模型中采样多个程序时,选择最佳候选程序的准确性更高。即使对于人类程序员来说,第一次编写的代码并不总是正确的,他们通常会检查代码并根据执行结果更改来解决实现错误。因此,该研究提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试。
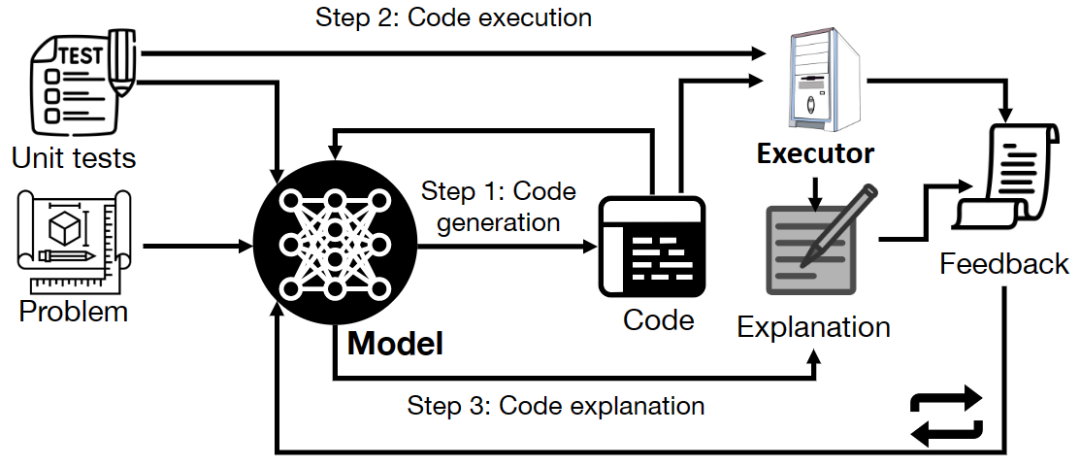
不同于需要额外模型训练的方法,Self-Debugging 通过代码解释来指导模型识别实现错误,类似于人类程序员通过逐行向橡皮鸭解释代码行来提高调试效率的方法。图 1 展示了 Self-Debugging 的完整过程。
在每一步调试中,模型首先生成新的代码,然后执行该代码并解释,代码解释和执行结果构成了反馈信息,然后将反馈信息发送回模型以执行更多的调试步骤。当单元测试不可用时,反馈可以完全基于代码解释。
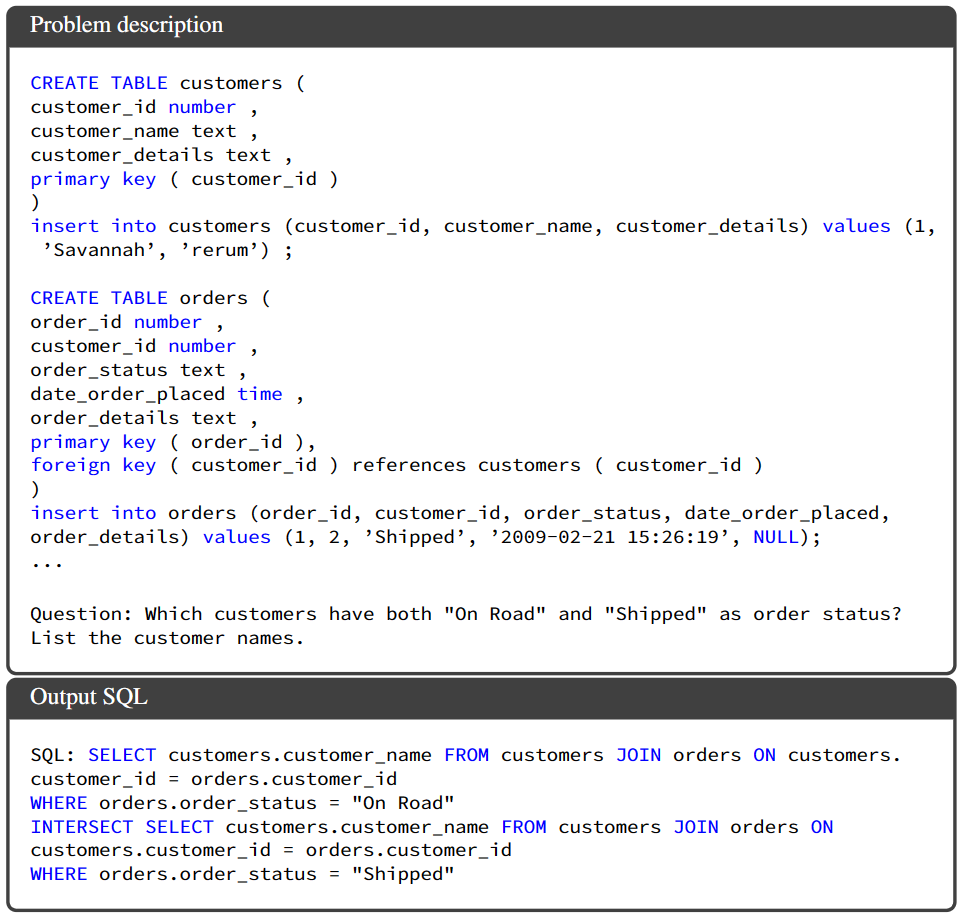
Few-shot prompting 是一种通过几个输入-输出演示来指导语言模型完成任务的方法。以文本到 SQL 生成为例,few-shot 提示在感兴趣的问题前面加上(question, SQL)对的列表,这样当模型被要求预测给定提示后的后续 token 时,它会按照提示的格式生成 SQL 查询语句。图 2 展示了一个示例的提示。此外,这种方法还可以在提示中添加指令来提供高级任务描述。
先前的研究表明,对于大型语言模型,在解码过程中生成多个预测结果可以显著提高性能,特别是在代码生成任务中,可以利用代码执行结果来选择最终的预测结果。有以下两种方法:
使用执行结果的多数投票来选择最终的预测结果;
设计重新排序方案来提高性能。
在本研究中,当存在多个预测结果时,遵循第一种方法,选择在执行时没有遇到错误的预测中具有最频繁执行结果的代码,并对其应用 Self-Debugging。一些代码生成任务伴随着单元测试,以指定程序的执行行为。在问题描述中给出单元测试时,执行基于多数投票的选择之前,会先过滤掉未通过单元测试的程序。
图 1 展示了 Self-Debugging 迭代调试框架,使用未经微调的预训练大型语言模型。在给定问题描述后,模型首先预测候选程序,然后推断程序的正确性,并生成反馈信息以进行后续的调试步骤。当反馈信息表明预测结果是正确的,或者达到了允许的最大调试轮数时,调试过程终止。
现有的研究表明,语言模型可以通过训练来理解人类对代码的反馈,并根据指令进行修正。然而,目前尚不清楚语言模型是否能够在没有人类辅助的情况下自行进行调试。在接下来的讨论中,将探讨如何利用代码执行和 few-shot 提示来生成不同类型的自动获取和生成的反馈信息。
最简单的自动反馈形式是一句话,仅指示代码的正确性,没有更详细的信息。例如,在文本到 SQL 生成任务中, few-shot 提示会依据正确或错误结果为所有 SQL 查询提供反馈信息:
“上面的SQL预测是正确的!”
“上面的 SQL 预测是错误的,请修正 SQL。”
对于包含单元测试的代码生成任务,除了通过代码执行来检查代码的正确性外,还可以在反馈信息中呈现单元测试的执行结果,从而为调试提供更丰富的信息。图 5 的示例包含了代码翻译任务的单元测试反馈信息。通过检查运行时错误消息和未通过的单元测试的执行结果,可以帮助人类程序员更有效地进行调试。实验结果表明,利用单元测试可以显著提高调试性能。
尽管大型语言模型在生成批评性反馈方面取得了一些进展,以避免生成有害的输出并在自然语言和推理任务中提高性能,但先前的研究尚未在代码生成任务中验证了反馈的有效性。然而,研究表明大型语言模型可以生成描述问题解决方案的文本和代码。基于这一启示,提出了一种新方法,即通过解释生成的代码来教模型进行自我调试,而不是教它预测错误消息。这种调试过程类似于程序员通过向橡皮鸭逐行解释代码来进行调试。研究验证了即使在没有单元测试的情况下,大型语言模型也可以从这种调试方法中获益。
在文本到 SQL 生成任务中,使用 Self-Debugging 方法旨在评估大型语言模型的性能,如图 3 所示。由于缺乏单元测试,模型更难推断预测的 SQL 查询的正确性。

调试过程包括三个步骤:
首先,模型通过提示对问题进行总结,并推断问题所需的返回类型,即对应 SQL 查询表的列数。
其次,模型执行 SQL 查询并将返回的表格添加到输入中,以进行代码解释。生成的 SQL 解释包括对每个子句的详细描述、包含在返回表格中的列数以及完整 SQL 查询的高层含义。如果返回表格超过两行,只有前两行包含在提示中。
最后,模型将推断的 SQL 解释和问题描述进行比较,并预测当前 SQL 查询的正确性。Self-Debugging 过程在第三步中认为 SQL 查询是正确的,或者达到最大的调试轮数时终止。
这种方法使得模型能够通过对生成的 SQL 查询进行解释和比较,从而自我调试并预测 SQL 查询的正确性。可以有望提高模型在文本到 SQL 生成任务中的性能,并弥补缺乏单元测试的限制。
在实验中,TransCoder 数据集包含了不同编程语言中的平行函数以及单元测试的测试集。根据先前研究的方法,将 Self-Debugging 应用于将 C++ 代码翻译成 Python 代码的任务,并且使用了相同的测试集,包含 560 个问题和每个问题 10 个单元测试,问题描述包括了 C++ 代码和所有单元测试,如图 4 所示。

由于单元测试的可用性,研究人员只在预测的 Python 代码未通过所有单元测试时才应用 Self-Debugging 技术,这样模型就不需要预测反馈信息。如图 5 所示,他们迭代地应用 Self-Debugging 技术,直到预测的代码通过了所有单元测试,或模型达到了预设的最大调试轮数。

在问题描述中包含了部分单元测试,MBPP 数据集包含了 500 个 Python 问题的文本描述,每个问题都包含3个单元测试。作者在提示中包含问题描述中的第一个单元测试,并将剩余的2个单元测试保留以进行完整的评估。与代码翻译类似,可以在反馈信息中利用单元测试的执行结果,但主要的区别在于,即使预测的 Python 代码通过了给定的单元测试,模型仍然需要推断代码的正确性。
这里对实验部分将不再赘述,作者在所有 Self-Debugging 的实验中,使用贪婪解码来生成代码解释、反馈信息和新的程序,并将最大调试轮数设置为 10。实验证明,成功的调试过程通常在 3 轮内结束。
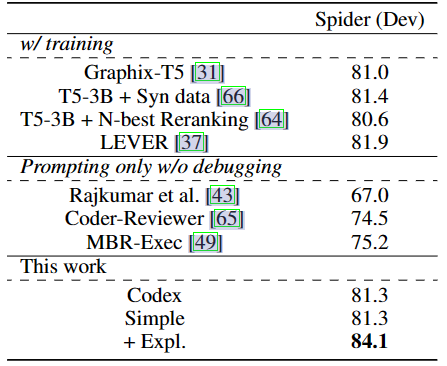

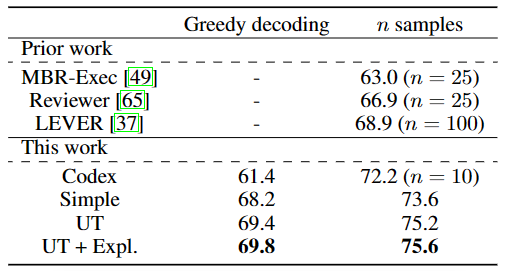
在表格 1、2 和 3 中,作者展示了 Self-Debugging 与现有方法的比较结果:
由于没有可用的单元测试,仅有简单的反馈并不能改善性能,因为模型无法仅通过少量的示例区分正确和错误的 SQL 查询,并且不能对初始预测的 SQL 查询进行有意义的修改。
简单的反馈利用了执行结果来推断代码的正确性,即使执行信息没有在反馈信息中呈现给模型。因此简单的反馈仍然改进了模型的预测性能。
对于所有任务,模型从更丰富的反馈信号中受益。尤其是代码解释使得模型可以在没有单元测试的情况下进行 Self-Debugging。
在消融实验中,作者主要指出以下几点:
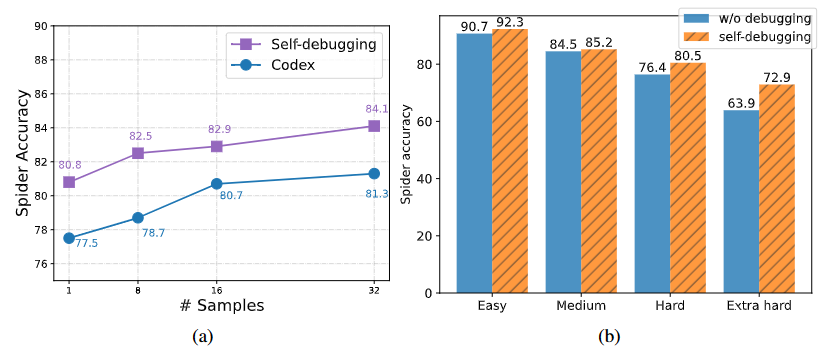
通常情况下,一个调试轮次已经足够。这些结果强调了利用大型语言模型解释代码进行调试的优势。
在图 6b 中进一步展示了不同难度级别问题上的准确性细分情况,其中每个问题的难度在数据集中根据目标 SQL 查询的复杂性进行了注释。在不同难度级别的问题上,Self-Debugging 对于较难的问题改进更加显著。
解决难题的能力:特别是在额外困难问题上,Self-Debugging 将准确性提高了 9%。图 7 展示了一个额外困难问题中,Self-Debugging 修复了预测的 SQL 查询的例子。
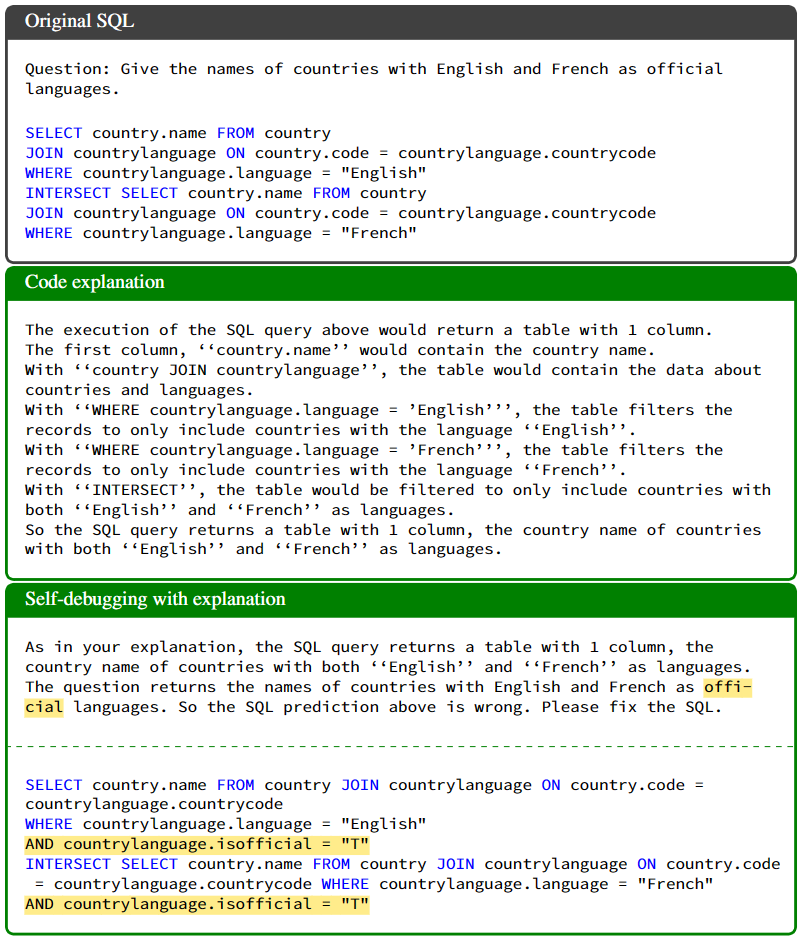
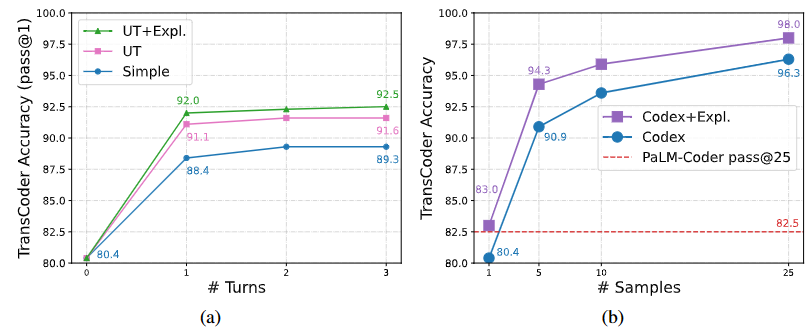
图 8a 展示了不同调试轮次上的准确性,图 8b 展示了不同初始样本数量上的准确性。
将单元测试执行和代码解释结合起来可以提高调试性能,在图 9 和图 10 中展示了这些例子。
如图 8b 所示,单独利用代码解释而不进行 Self-Debugging 也可以在不同数量的样本上提供一致的性能提升。
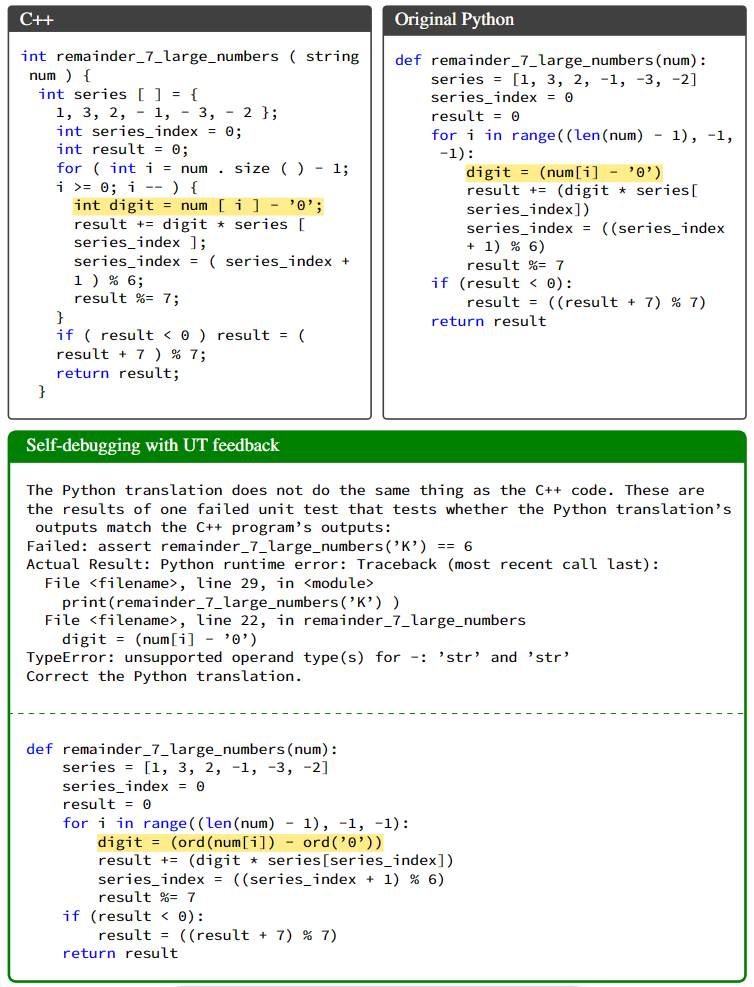

发现在初始预测代码与正确解之间差距较大时,代码解释的作用较小,此时模型更倾向于生成新的程序而不是依赖于初始预测中的代码片段。在图 11 中展示了一个例子,其中 Self-Debugging 后的预测代码与初始代码差异很大。
本文介绍了 Self-Debugging 技术,它使得大型语言模型能够自行调试所生成的代码,该方法使模型能够进行橡皮鸭子调试,从而使模型能够在没有人类指导的情况下识别和修复错误。在多个代码生成领域,它实现了最先进的性能,并且显著提高了样本效率。
在文本到 SQL 生成任务中,由于该任务没有指定单元测试,利用代码解释进行 Self-Debugging 以及在最困难的问题上可以始终有好效果。对于代码翻译和文本到 Python 生成任务,在有单元测试可用的情况下,Self-Debugging 准确性提高了多达 12%。
本工作强调了通过教大型语言模型迭代来自己调试预测的方法,从而改进其编码性能的潜力,而非要求模型从零开始生成正确的代码。Self-Debugging 指导模型理解代码、识别错误,并根据错误信息修复错误。
未来的研究方向可以包括进一步提高模型在调试过程中的能力。例如:
探索让模型更好地描述代码的高级语义含义和实现细节,从而提高其代码解释能力。
考虑在模型的反馈中包含更多的调试信息(例如潜在错误的描述),以提供更加丰富的指导。
相信这些改进将进一步推动大型语言模型在编码任务中的性能提升,并在实际应用中发挥更大的潜力。若是有朝一日,用大模型的问答工具准确地辅助我们写代码,少了焦头烂额 Debug 的内耗时刻,岂不美哉?

卖萌屋作者:智商掉了一地
北理工计算机硕士在读,近期沉迷于跟 ChatGPT 唠嗑,对一切新颖的 NLP 应用充满好奇,正在努力成为兴趣广泛的斜杠青年~
作品推荐
如何提升大规模Transformer的训练效果?Primer给出答案
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co