
❝ELK 是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个 FileBeat,它是一个轻量级的日志收集处理工具 (Agent),Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具。大致流程图如下:
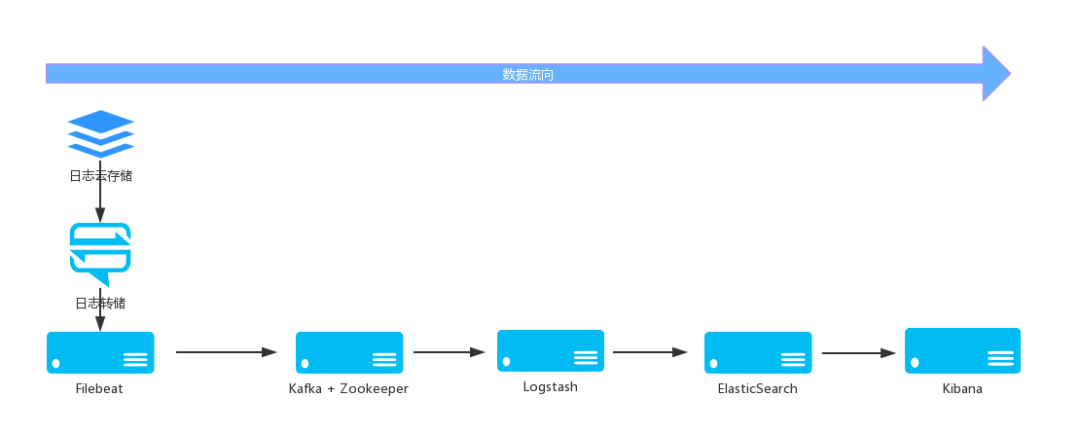
❝Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
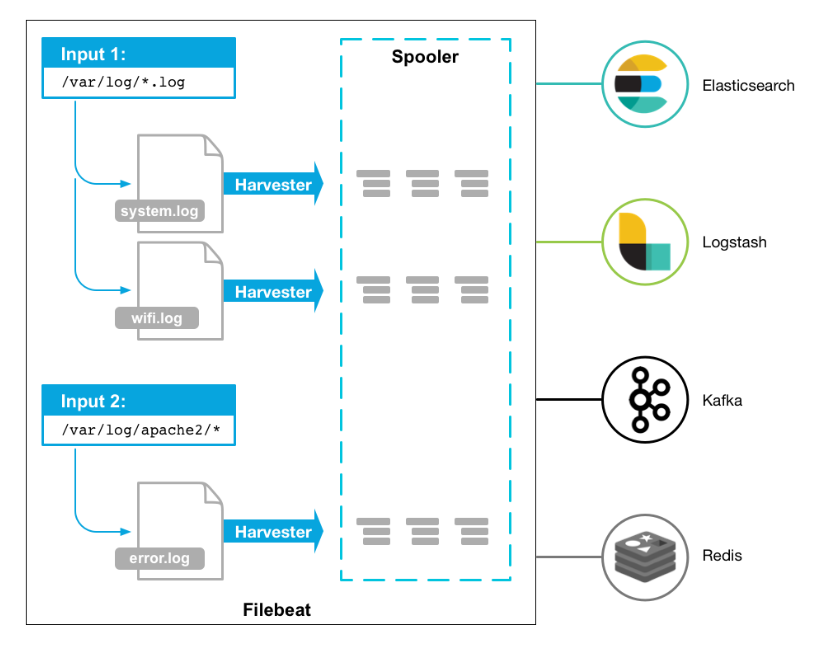
❝filebeat 是 Beats 中的一员,Beats 在是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。❝Filebeat 是用于转发和集中日志数据的轻量级传送工具。Filebeat 监视您指定的日志文件或位置,收集日志事件。目前 Beats 包含六种工具:
 优点
优点❝kafka 能帮助我们削峰。ELK 可以使用 redis 作为消息队列,但 redis 作为消息队列不是强项而且 redis 集群不如专业的消息发布系统 kafka。kafka 安装可以参考我之前的文章:Kafka 原理介绍+安装+基本操作(kafka on k8s)[1]。
❝Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch 上去。优点
❝节拍应该在一组 Logstash 节点之间进行负载平衡。建议至少使用两个 Logstash 节点以实现高可用性。每个 Logstash 节点只部署一个 Beats 输入是很常见的,但每个 Logstash 节点也可以部署多个 Beats 输入,以便为不同的数据源公开独立的端点。
❝Logstash 持久队列提供跨节点故障的保护。对于 Logstash 中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置 RAID。在云或容器化环境中运行时,建议您使用具有反映数据 SLA 的复制策略的永久磁盘。
❝对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。缺点
❝Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
❝因为 logstash 是 jvm 跑的,资源消耗比较大,所以后来作者又用 golang 写了一个功能较少但是资源消耗也小的轻量级的 logstash-forwarder。不过作者只是一个人,加入 http://elastic.co 公司以后,因为 es 公司本身还收购了另一个开源项目 packetbeat,而这个项目专门就是用 golang 的,有整个团队,所以 es 公司干脆把 logstash-forwarder 的开发工作也合并到同一个 golang 团队来搞,于是新的项目就叫 filebeat 了。

$ helm repo add elastic https://helm.elastic.co❝主要是设置 storage Class 持久化和资源限制,本人电脑资源有限,所以这里就把资源调小了很多,小伙伴们可以根据自己配置自定义哈。
# 集群名称
clusterName: "elasticsearch"
# ElasticSearch 6.8+ 默认安装了 x-pack 插件,部分功能免费,这里选禁用
esConfig:
elasticsearch.yml: |
network.host: 0.0.0.0
cluster.name: "elasticsearch"
xpack.security.enabled: falseresources:
requests:
memory: 1Gi
volumeClaimTemplate:
storageClassName: "bigdata-nfs-storage"
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 3Gi
service:
type: NodePort
port: 9000
nodePort: 31311❝禁用 Kibana 安全提示(Elasticsearch built-in security features are not enabled)xpack.security.enabled: false
❝安装过程比较慢,因为官方镜像下载比较慢
$ helm install es elastic/elasticsearch -f my-values.yaml --namespace bigdata
W1207 23:10:57.980283 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
W1207 23:10:58.015416 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
NAME: es
LAST DEPLOYED: Tue Dec 7 23:10:57 2021
NAMESPACE: bigdata
STATUS: deployed
REVISION: 1
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=bigdata -l app=elasticsearch-master -w2. Test cluster health using Helm test.
$ helm --namespace=bigdata test es$ kubectl get pod -n bigdata -l app=elasticsearch-master
$ kubectl get pvc -n bigdata
$ watch kubectl get pod -n bigdata -l app=elasticsearch-master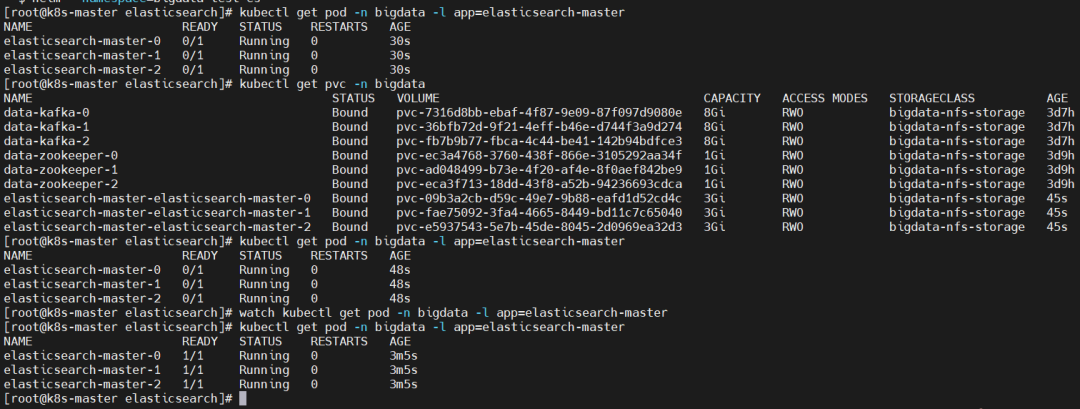
$ helm --namespace=bigdata test es
$ kubectl get pod,svc -n bigdata -l app=elasticsearch-master -o wide
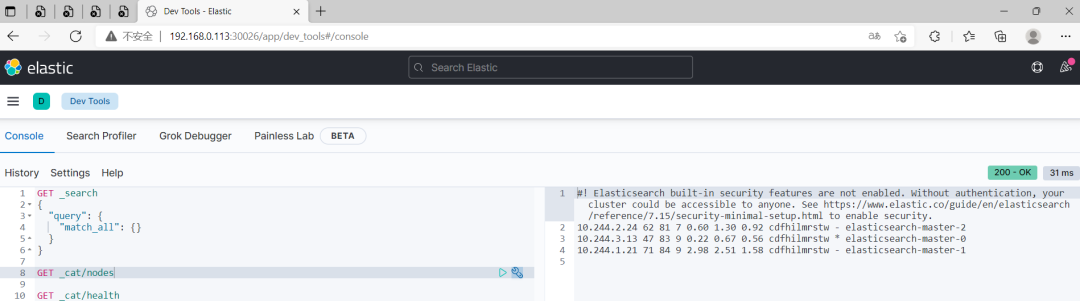
$ curl 192.168.0.113:31311/_cat/health
$ curl 192.168.0.113:31311/_cat/nodes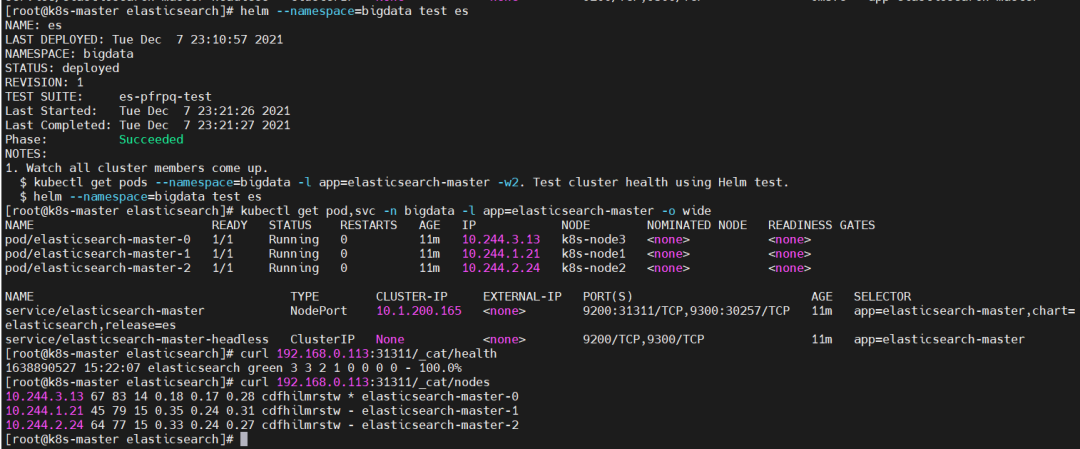
$ helm uninstall es -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-0 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-1 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-2 -n bigdata$ cat <<EOF> my-values.yaml
#此处修改了kibana的配置文件,默认位置/usr/share/kibana/kibana.yaml
kibanaConfig:
kibana.yml: |
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: [ "elasticsearch-master-headless.bigdata.svc.cluster.local:9200" ]resources:
requests:
cpu: "1000m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
service:
#type: ClusterIP
type: NodePort
loadBalancerIP: ""
port: 5601
nodePort: "30026"
EOF$ helm install kibana elastic/kibana -f my-values.yaml --namespace bigdata
$ kubectl get pod,svc -n bigdata -l app=kibana
$ helm uninstall kibana -n bigdata❝filebeat 默认收集宿主机上 docker 的日志路径:/var/lib/docker/containers。如果我们修改了 docker 的安装路径要怎么收集呢,很简单修改 chart 里的 DaemonSet 文件里边的 hostPath 参数:
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #改为docker安装路径❝默认是将数据存储到 ES,这里做修改数据存储到 Kafka
$ cat <<EOF> my-values.yaml
daemonset:
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
output.elasticsearch:
enabled: false
host: '${NODE_NAME}'
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
output.kafka:
enabled: true
hosts: ["kafka-headless.bigdata.svc.cluster.local:9092"]
topic: test
EOF$ helm install filebeat elastic/filebeat -f my-values.yaml --namespace bigdata
$ kubectl get pods --namespace=bigdata -l app=filebeat-filebeat -w

# 先登录kafka客户端
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
# 再消费数据
$ kafka-console-consumer.sh --bootstrap-server kafka.bigdata.svc.cluster.local:9092 --topic test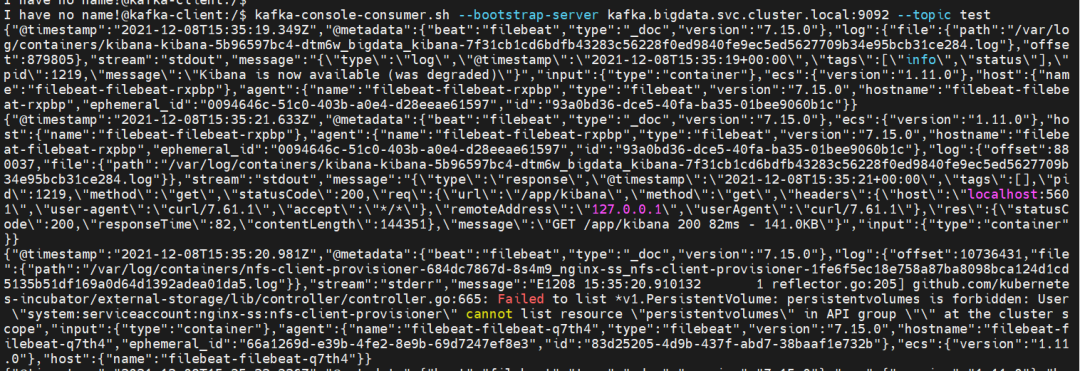 看到已经可以消费数据了,说明数据已经存储到 kafka 了。查看 kafka 数据积压情况
看到已经可以消费数据了,说明数据已经存储到 kafka 了。查看 kafka 数据积压情况$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup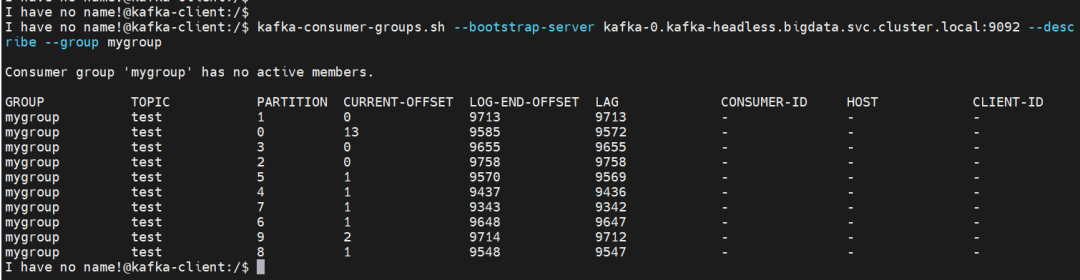 接下来就是部署 logstash 去消费 kafka 数据,最后存储到 ES。
接下来就是部署 logstash 去消费 kafka 数据,最后存储到 ES。$ helm uninstall filebeat -n bigdata❝【注意】记得把 ES 和 kafka 的地址换成自己环境的。
$ cat <<EOF> my-values.yaml
logstashConfig:
logstash.yml: |
xpack.monitoring.enabled: false
logstashPipeline:
logstash.yml: |
input {
kafka {
bootstrap_servers => "kafka-headless.bigdata.svc.cluster.local:9092"
topics => ["test"]
group_id => "mygroup"
#如果使用元数据就不能使用下面的byte字节序列化,否则会报错
#key_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
#value_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
consumer_threads => 1
#默认为false,只有为true的时候才会获取到元数据
decorate_events => true
auto_offset_reset => "earliest"
}
}
filter {
mutate {
#从kafka的key中获取数据并按照逗号切割
split => ["[@metadata][kafka][key]", ","]
add_field => {
#将切割后的第一位数据放入自定义的“index”字段中
"index" => "%{[@metadata][kafka][key][0]}"
}
}
}
output {
elasticsearch {
pool_max => 1000
pool_max_per_route => 200
hosts => ["elasticsearch-master-headless.bigdata.svc.cluster.local:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
# 资源限制
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 3Gi
EOF❝stdout { codec => rubydebug } // 开启 debug 模式,可在控制台输出
output{
stdout{
codec => "rubydebug"
}
}output{
file {
path => "/data/logstash/%{host}/{application}
codec => line { format => "%{message}"} }
}
}output{
kafka{
bootstrap_servers => "localhost:9092"
topic_id => "test_topic" #必需的设置。生成消息的主题
}
}output{
elasticsearch {
#user => elastic
#password => changeme
hosts => "localhost:9200"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
}$ helm install logstash elastic/logstash -f my-values.yaml --namespace bigdata
$ kubectl get pods --namespace=bigdata -l app=logstash-logstash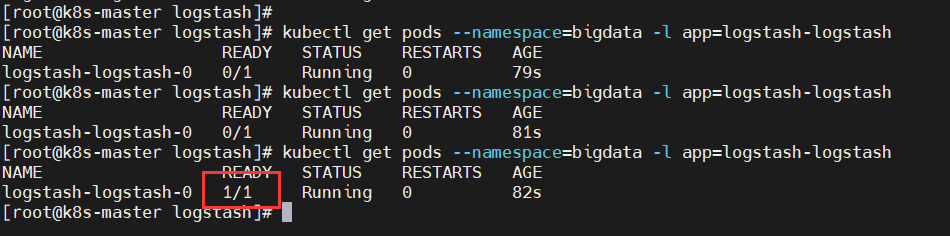
 (2)查看 logs
(2)查看 logs$ kubectl logs -f logstash-logstash-0 -n bigdata >logs
$ tail -100 logs (3)查看 kafka 消费情况
(3)查看 kafka 消费情况$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
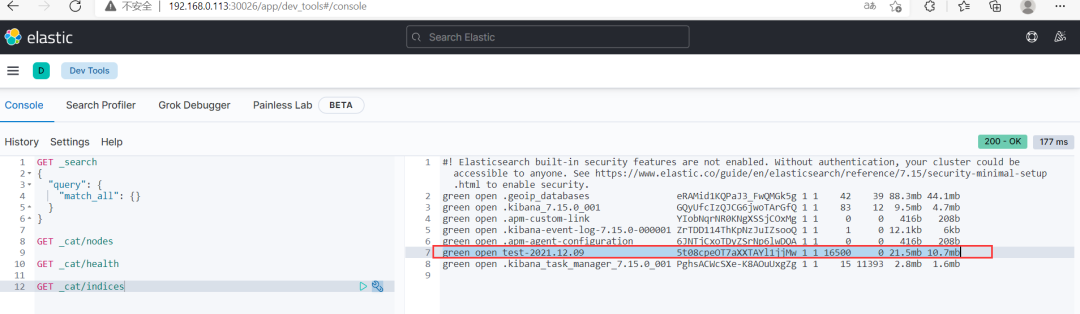
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup (4)通过 kibana 查看索引数据(Kibana 版本:7.15.0) 创建索引模式
(4)通过 kibana 查看索引数据(Kibana 版本:7.15.0) 创建索引模式❝Management-》Stack Management-》Kibana-》Index patterns
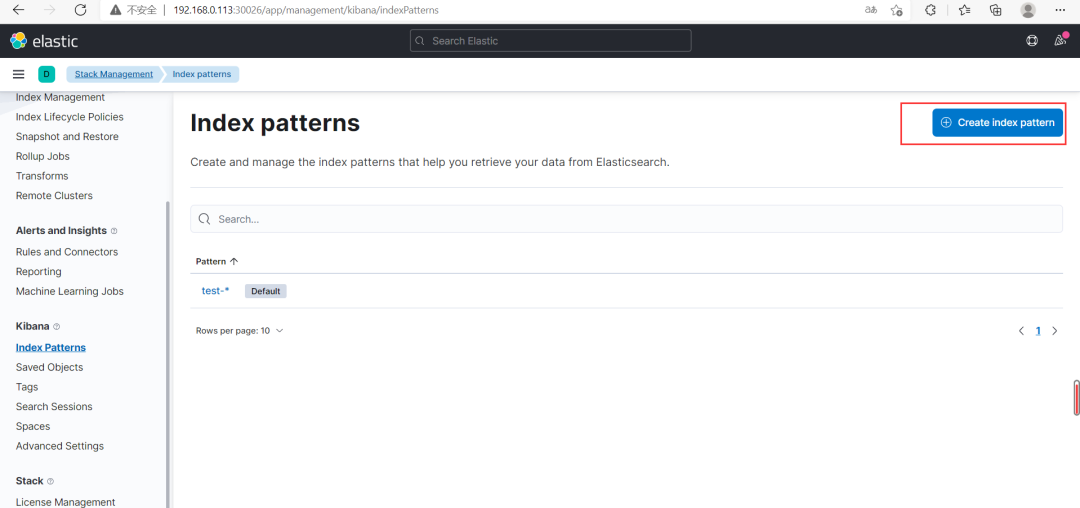
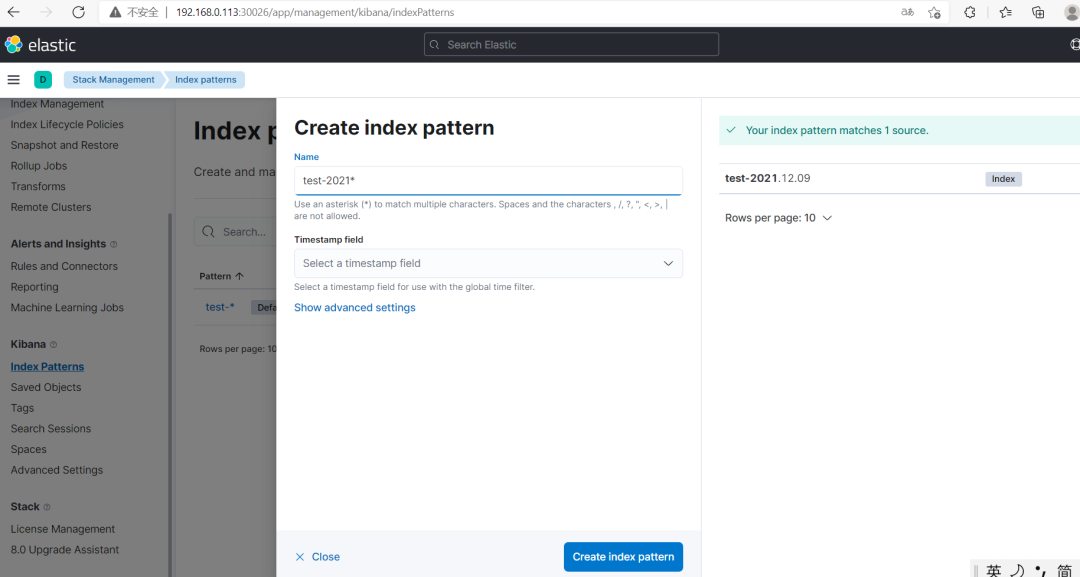
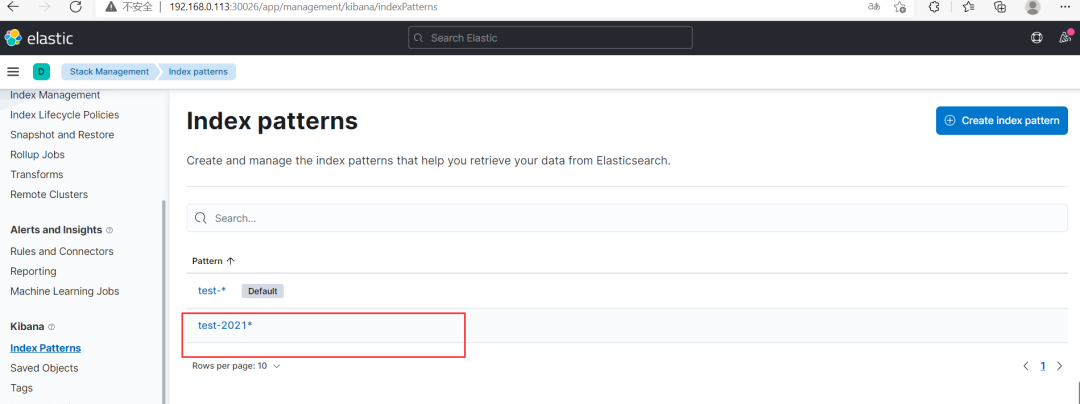 通过上面创建的索引模式查询数据(Discover)
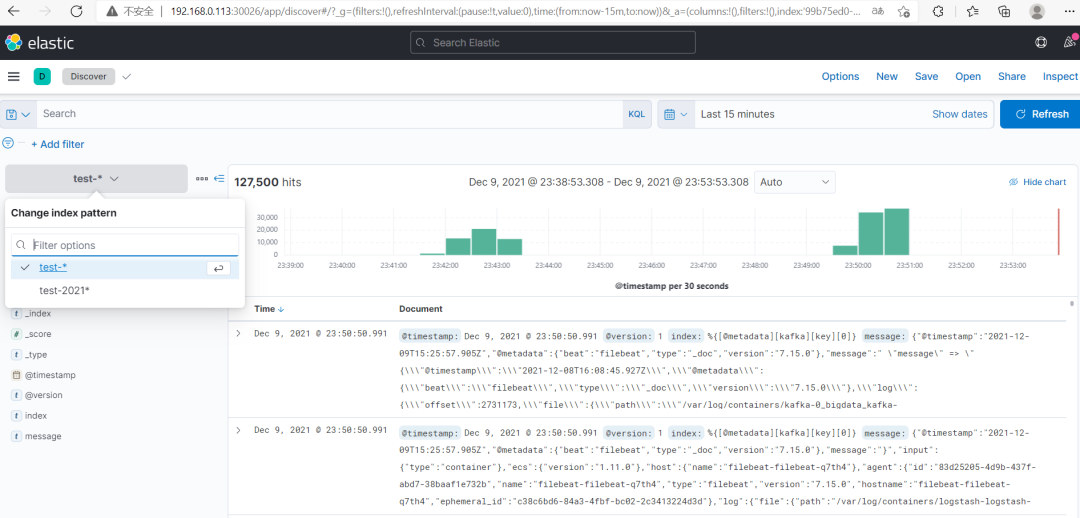
通过上面创建的索引模式查询数据(Discover)
$ helm uninstall logstash -n bigdatapath.repo: ["/mount/backups", "/mount/longterm_backups"]PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups/my_backup"
}
}PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true❝【温馨提示】wait_for_completion 为 true 是指该 api 在备份执行完毕后再返回结果,否则默认是异步执行的,我们这里为了立刻看到效果,所以设置了该参数,线上执行时不用设置该参数,让其在后台异步执行即可。
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true❝当执行完毕后,你会发现 /mount/backups/my_backup 体积变大了。这说明新数据备份进来了。要说明的一点是,当你在同一个 repository 中做多次 snapshot 时,elasticsearch 会检查要备份的数据 segment 文件是否有变化,如果没有变化则不处理,否则只会把发生变化的 segment file 备份下来。这其实就实现了增量备份。
POST /_snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "index_1",
"rename_replacement": "restored_index_1"
}# 导出索引Mapping数据
$ elasticdump \
--input=http://es实例IP:9200/index_name/index_type \
--output=/data/my_index_mapping.json \ # 存放目录
--type=mapping
# 导出索引数据
$ elasticdump \
--input=http://es实例IP:9200/index_name/index_type \
--output=/data/my_index.json \
--type=data# Mapping 数据导入至索引
$ elasticdump \
--output=http://es实例IP:9200/index_name \
--input=/home/indexdata/roll_vote_mapping.json \ # 导入数据目录
--type=mapping
# ES文档数据导入至索引
$ elasticdump \
--output=http:///es实例IP:9200/index_name \
--input=/home/indexdata/roll_vote.json \
--type=data$ elasticdump --input=http://127.0.0.1:9200/test_event --output=http://127.0.0.2:9200/test_event --type=data| type 类型 | 说明 |
| mapping | ES 的索引映射结构数据 |
| data | ES 的数据 |
| settings | ES 的索引库默认配置 |
| analyzer | ES 的分词器 |
| template | ES 的模板结构数据 |
| alias | ES 的索引别名 |
$ esm -s http://10.33.8.103:9201 -x "petition_data" -b 5 --count=5000 --sliced_scroll_size=10 --refresh -o=./es_backup.bin❝-w 表示线程数 -b 表示一次 bulk 请求数据大小,单位 MB 默认 5M -c 一次 scroll 请求数量 导入恢复 es 数据
$ esm -d http://172.16.20.20:9201 -y "petition_data6" -c 5000 -b 5 --refresh -i=./dump.bin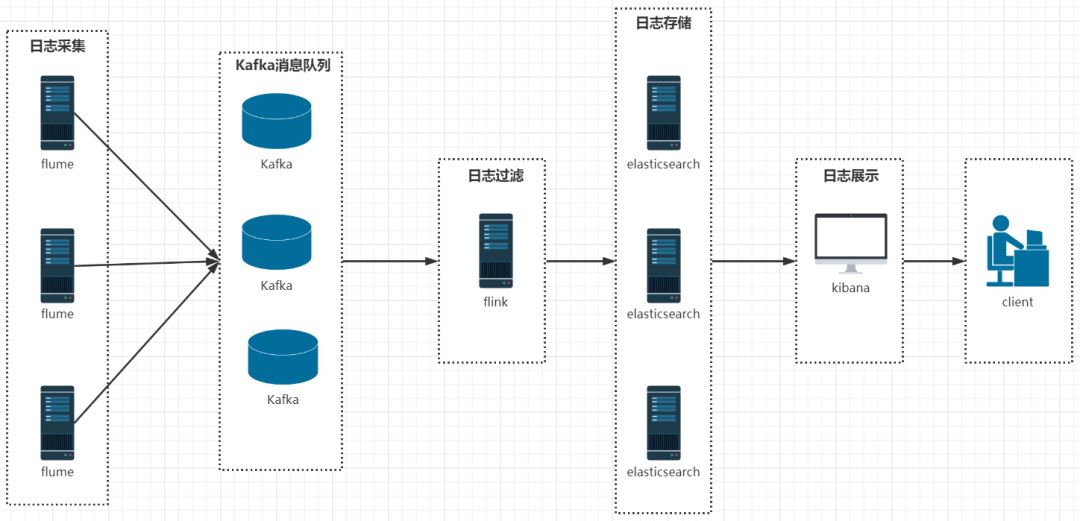
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser