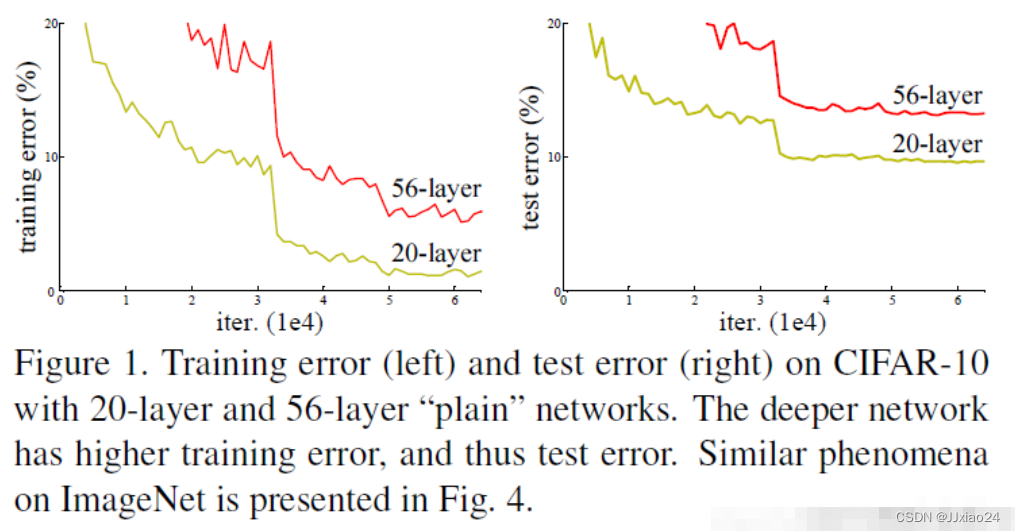
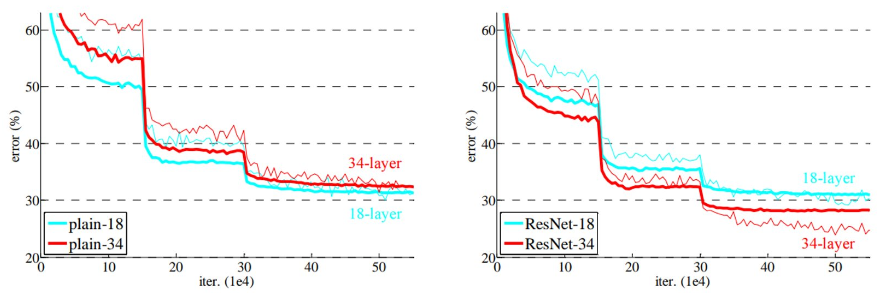
随着CNN的不断发展,为了获取深层次的特征,卷积的层数也越来越多。一开始的 LeNet 网络只有 5 层,接着 AlexNet 为 8 层,后来 VggNet 网络包含了 19 层,GoogleNet 已经有了 22 层。但仅仅通过增加网络层数的方法,来增强网络的学习能力的方法并不总是可行的,因为网络层数到达一定的深度之后,再增加网络层数,那么网络就会出现随机梯度消失的问题,也会导致网络的准确率下降。以下实验结果也表明确实出现了该现象,论文中称为网络退化现象,注意这和网络过拟合是两种情况。

上图是一个四层的全连接的网络,包括输入层、隐层(中间除了输入层跟输出层的总和)、输出层,假设每层网络激活后的输出为fi(x),其i表示第i层,x指的是第i层的输入,也就是第i-1层的输出,f是作为激活函数,那么就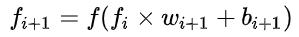 ,反向传播算法是基于梯度下降,以目标负梯度方向对参数进行调整,参数的更新为
,反向传播算法是基于梯度下降,以目标负梯度方向对参数进行调整,参数的更新为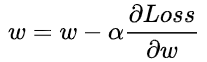 ,如果要更新第二层隐藏层的权值信息,根据链式求导法则:
,如果要更新第二层隐藏层的权值信息,根据链式求导法则: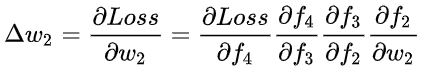 其实类似于
其实类似于 就是对激活函数进行求导,如果所求导结果大于1,那么随着层数的增加,求出的梯度的更新将以指数形式相应增加,发生前文所提到的梯度爆炸;如果小于1,求出的梯度的更新将以指数形式相应减少,就会发生梯度消失。
就是对激活函数进行求导,如果所求导结果大于1,那么随着层数的增加,求出的梯度的更新将以指数形式相应增加,发生前文所提到的梯度爆炸;如果小于1,求出的梯度的更新将以指数形式相应减少,就会发生梯度消失。
为了解决这一问题,传统的方法是采用数据初始化和正则化的方法,这解决了梯度消失的问题,但是网络准确率的问题并没有改善。而残差网络的出现可以解决梯度问题,而网络层数的增加也使其表达的特征也更好,相应的检测或分类的性能更强,再加上残差中使用了 1×1 的卷积,这样可以减少参数量,也能在一定程度上减少计算量。
ResNet 网络的关键就在于其结构中的残差单元,如下图所示,在残差网络单元中包含了跨层连接,图中的曲线可以将输入直接跨层传递,进行了同等映射,之后与经过卷积操作的结果相加。假设输入图像为 x,输出为H(x),中间经过卷积之后的输出为F(x)的非线性函数,那最终的输出为H(x) = F(x) + x,这样的输出仍然可以进行非线性变换,残差指的是“差”,也就是F(x),而网络也就转化为求残差函数F(x) = H(x) - x,这样残差函数要比 F(x) = H (x) 更加容易优化。

Resnet可以理解为三个人之间传话的游戏,第一个人传给第二个人,第二个人传给第三个人,那么第三个人收到的信息可能会由于第二个人理解错误,接收的信息受到影响,增加了传错的概率,所以Resnet的作用可以直跳过第二个人,直接把话给到第三个人。这个就是对于Resnet的简单理解。
ResNet提出了两种mapping:一种是identity mapping,指的就是图中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 H(x) = F(x) + x,identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是F(x) = H(x)−x,所以残差指的就是F(x)部分,这里有解释了一遍F(x) = H(x)−x。
Resnet50网络中包含了49 个卷积层,外加一个全连接层(FC)。如下图所示,Resnet50网络结构可以分成七个部分,第一部分不包含残差块,主要对输入进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块,图中的绿色图块不会改变残差块的尺寸,只用于改变残差块的维度。在Resnet50网络结构中,残差块都有三层卷 积,那网络总共就是有1+3 × (3+4+6+3) = 49个卷积层,加上最后的全连接层总共是50层,这也是Resnet50名称的由来。网络的输入为224×224×3,经过前五部分的卷积计算,输出为7×7×2048,池化层会将其转化成一个特征向量,最后分类器会对这个特征向量进行计算并输出类别概率。
下面这张图片是Resnet文章所展示的结构图,文章会对其进行剖析,让人好理解。

Resnet50的另外一种理解。
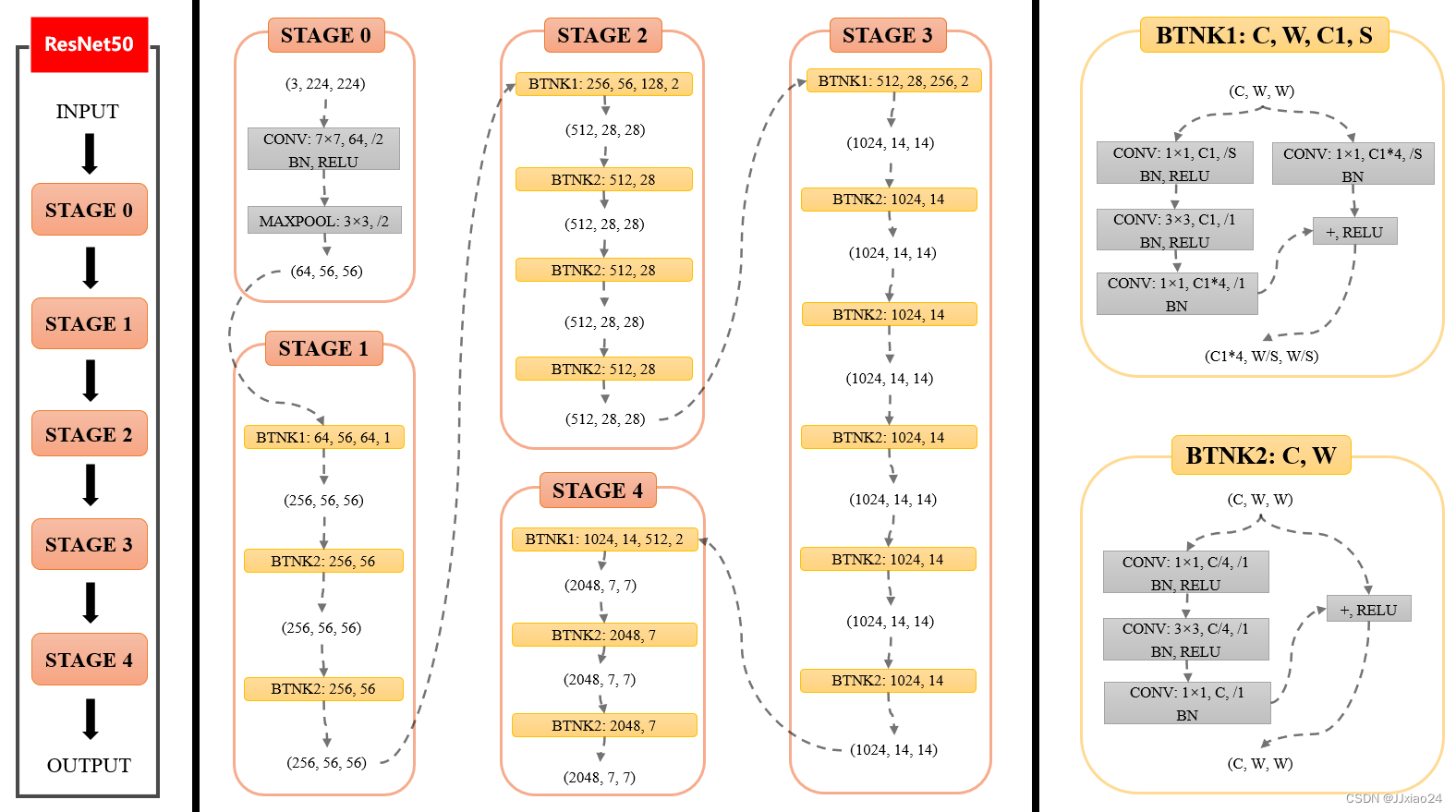
上图可划分为左、中、右3个部分,三者内容分别:Resnet50整体结构;Resnet50各个stage具体结构;Bottleneck具体结构。
整体结构部分分为5个stage,其中stage 0 的结构是比较简单,可以视其为对INPUT图像的预处理,后4个Stage都由Bottleneck组成,结构较为相似。Stage 1包含3个Bottleneck,剩下的3个stage分别包括4、6、3个Bottleneck。
(3,224,224) 指输入INPUT的通道数(channel)、高(height)和宽(width),即(C,H,W)。现假设输入的高度和宽度相等,所以用(C,W,W)表示。
该stage中第1层包括3个先后操作:
1.CONV
CONV是卷积(Convolution)的缩写,7×7指卷积核大小,64指卷积核的数量(即该卷积层输出的通道数),/2指卷积核的步长为2。
2.BN
BN是Batch Normalization的缩写,即常说的BN层。
3.RELU
RELU指ReLU激活函数。
该stage中第2层为MAXPOOL,即最大池化层,其卷积核大小为3×3、步长为2。
(64,56,56)是该stage输出的通道数(channel)、高(height)和宽(width),其中64等于该stage第1层卷积层中卷积核的数量,56等于224/2/2(步长为2会使输入尺寸减半)。
总体来讲,在Stage 0中,形状为(3,224,224)的输入先后经过卷积层、BN层、ReLU激活函数、MaxPooling层得到了形状为(64,56,56)的输出。
与stage 0类似,stage1输入的形状为(64,56,56),输出的形状为(64,56,56)。
现在要介绍2种Bottleneck的结构。“BTNK”指的是BottleNeck的缩写。
2种Bottleneck分别对应了2种情况:输入与输出通道数相同(BTNK2)、输入与输出通道数不同(BTNK1),这一点可以结合ResNet原文。
BTNK2有2个可变的参数C和W,即输入的形状(C,W,W)中的c和W。
令形状为(C,W,W)的输入为x,令BTNK2左侧的3个卷积块(以及相关BN和RELU)为函数F(x),两者相加(F(x)+x)后再经过1个ReLU激活函数,就得到了BTNK2的输出,该输出的形状仍为(C,W,W),即上文所说的BTNK2对应输入x与输出F(x)通道数相同的情况。
BTNK1有4个可变的参数C、W、C1和S。
与BTNK2相比,BTNK1多了1个右侧的卷积层,令其为函数G(x)。BTNK1对应了输入x与输出F(x)通道数不同的情况,也正是这个添加的卷积层将x变为G(x),起到匹配输入与输出维度差异的作用(G(x)和F(x)通道数相同),进而可以进行求和F(x)+G(x)。
ResNet后4个stage中都有BTNK1和BTNK2。
class Bottleneck(nn.Module):
expansion = 4 # 卷积核是前一个卷积核的四倍
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNormalization(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, bias=False,
stride=stride, padding=1)
self.bn2 = nn.BatchNormalization(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(out_channels=out_channel * self.expansion, kernel_size=1, stride=1,
bias=False)
self.bn3 = nn.BatchNormalization(out_channel * self.expansion)
# -----------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None: # 为None的话对应实线的残差结构,如果不为None则是虚线的
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.add([out, identity])
out = self.relu(out)
return out
参考:
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput