Eslint 是用来检测和规范代码格式的工具,应用在工程化项目中,可以保证项目代码格式的一致性和规范性,大大提升了代码的可读性。
本博客是讲述对一个已经引用 eslint 依赖Nuxt项目(vue项目应该相同),在使用VScode进行开发时,如何配置VScode在保存时,自动 eslint 格式化,并修改部分 eslint 规则,使其不与自动格式化的规则相冲突。这样可以大大提升我们的开发效率,并且如果对某些外部复制(抄)过来的代码,也可通过自动格式化,来使其符合 eslint 的格式。
在 VSCode 的插件市场中安装以下四个插件:

该插件是用来实现Vue语法高亮的。

格式化CSS

点击VSCode页面左下角的设置按钮,选择设置,选择扩展中的Eslint选项,并找到 在 settings.json 中编辑选项。
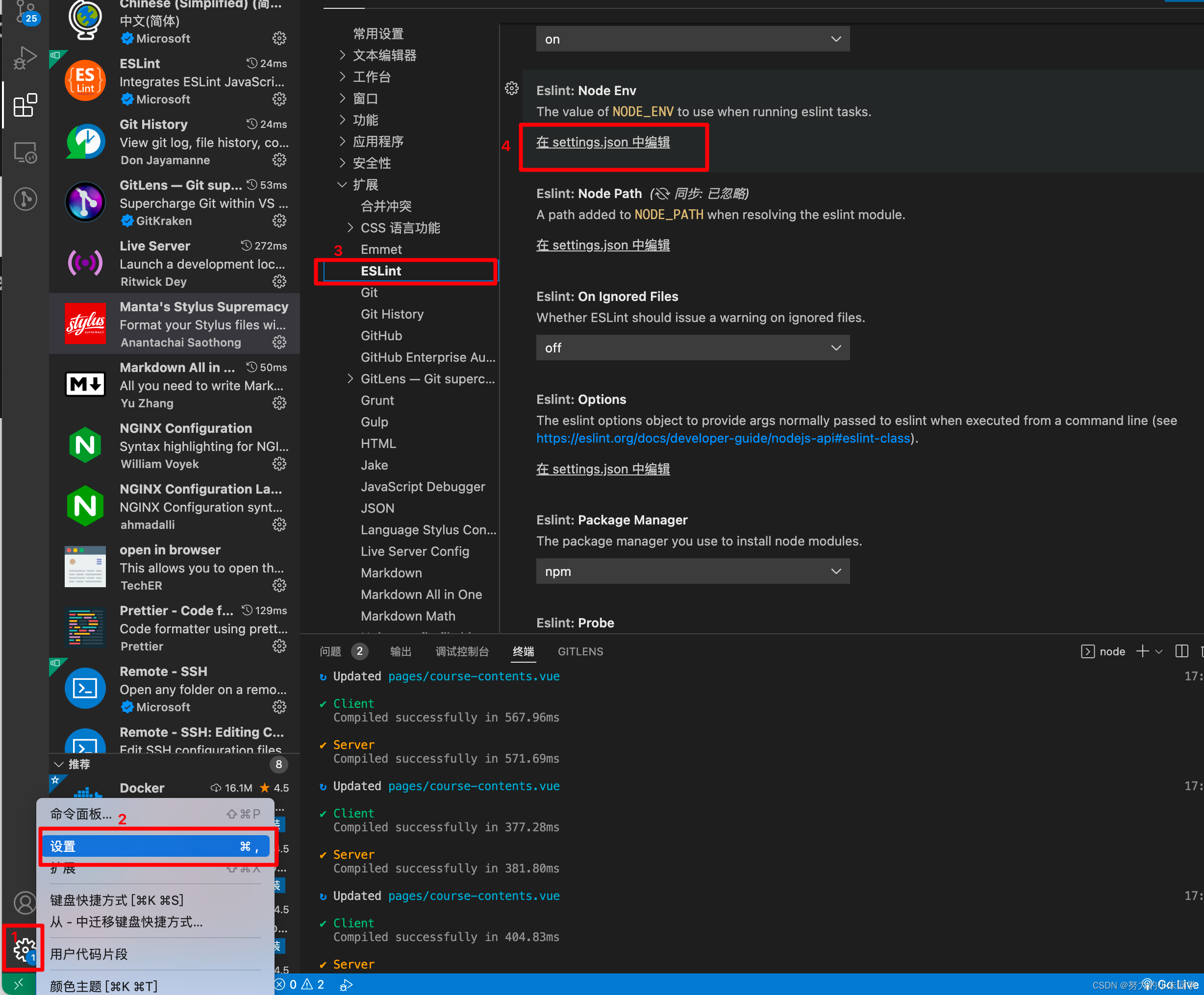
然后在该 配置文件中输入以下代码:
{
"workbench.colorTheme": "Default Dark+",
"editor.tabSize": 2,
"editor.fontSize": 14,
"[vue]": {
"editor.defaultFormatter": "octref.vetur"
},
"security.workspace.trust.untrustedFiles": "open",
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
},
"editor.detectIndentation": false,
"editor.formatOnSave": true,
"eslint.autoFixOnSave": true,
"eslint.validate": [
"javascript",
"javascriptreact",
{
"language": "vue",
"autoFix": true
}
],
"prettier.eslintIntegration": true,
"prettier.semi": false,
"prettier.singleQuote": true,
"javascript.format.insertSpaceBeforeFunctionParenthesis": true,
"vetur.format.defaultFormatter.html": "js-beautify-html",
"vetur.format.defaultFormatter.js": "vscode-typescript",
"vetur.format.defaultFormatterOptions": {
"js-beautify-html": {
"wrap_attributes": "force-aligned"
}
},
"stylusSupremacy.insertColons": false,
"stylusSupremacy.insertSemicolons": false,
"stylusSupremacy.insertBraces": false,
"stylusSupremacy.insertNewLineAroundImports": false,
"stylusSupremacy.insertNewLineAroundBlocks": false,
"editor.language.brackets": [
],
"eslint.nodeEnv": ""
}
在上面配置完成后,VSCode已经可以在保存时自动格式化了,但此时有两条格式化规则与eslint的规则相冲突,所以需要进行配置,在项目根目录的.eslintrc.js文件内,配置的是eslint的相关设置:
// 项目不同配置项可能不同,主要看rules项即可
module.exports = {
root: true,
env: {
browser: true,
node: true
},
parserOptions: {
parser: '@babel/eslint-parser',
requireConfigFile: false
},
extends: [
'@nuxtjs',
'plugin:nuxt/recommended'
],
plugins: [
],
// add your custom rules here
rules: {
// 修改标签属性的 eslint 规则 允许标签属性换行
'vue/first-attribute-linebreak': ['error', {
singleline: 'ignore',
multiline: 'ignore'
}],
// 修改 右标签 > 的 eslint 规则 无需单独一行
'vue/html-closing-bracket-newline': 0
}
}
Eslint的rules规则:
'规则名': [错误级别, '错误处理方式']
错误级别分为三种:
① “off” or 0 - 关闭规则
② “warn” or 1 - 将规则视为一个警告
③ “error” or 2 - 将规则视为一个错误
// 例如
rules: {
'semi': [2, 'never'], // 不使用分号,否则报错
'quotes': [2, 'single'] // 使用单引号,否则报错
}
在项目根目录下 新建 .eslintignore 文件,以文件相对路径的形式表示项目中那些文件应该被忽略,一般用于忽略某些引入的外部组件。以 # 开头的行会被当作注释,路径是相对于 .eslintignore 的位置或当前工作目录,以 ! 开头的行是否定模式,它将会重新包含一个之前被忽略的模式。
除了 .eslintignore 文件中的设置的被忽略文件,ESLint还会自动忽略 node_modules和 bower_components中的文件。
当 ESLint 运行时,在确定哪些文件要检测之前,它会在当前工作目录中查找一个 .eslintignore 文件。如果发现了这个文件,当遍历目录时,将会应用这些偏好设置。一次只有一个 .eslintignore 文件会被使用,所以,不是当前工作目录下的 .eslintignore 文件将不会被用到。
# eslint 忽略的文件夹 或某个单独文件
# components/pagination/*
assets/css/icon/*
# 把被忽略的文件夹中的某个文件拿出来,使其不再被忽略
!assets/css/icon/icon.css
# 忽略所有js文件
# **/*.js
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的