在之前这一篇中我们分享过使用chameleon工具完成MySQL到openGauss的全量数据复制、实时在线复制。9.30新发布的openGauss 3.1.0版本 ,工具的全量迁移和增量迁移的性能不但有了全面提升,而且支持数据库对象视图、触发器、自定义函数、存储过程的迁移。

本篇就来分享一下使用chameleon工具进行从MySQL到openGauss的数据库对象迁移。
[root@pekphisprb70593 chameleon]# pip3 uninstall chameleon
Uninstalling chameleon-3.0.0:
Would remove:
/usr/local/python3/bin/chameleon
/usr/local/python3/bin/chameleon.py
/usr/local/python3/lib/python3.6/site-packages/chameleon-3.0.0.dist-info/*
/usr/local/python3/lib/python3.6/site-packages/pg_chameleon/*
Proceed (y/n)? y
Successfully uninstalled chameleon-3.0.0
[root@pekphisprb70593 chameleon]# rm -rf chameleon-3.0.0-py3-none-any.whl
2.从官网https://opengauss.org/zh/supporttools.html 获取获取工具包,chameleon-3.1.0-py3-none-any.whl
3.将新的3.1.0工具上传到openGauss数据库所在节点的chameleon文件夹下。
[root@pekphisprb70593 chameleon]# python3 -m venv venv
[root@pekphisprb70593 chameleon]# source venv/bin/activate
(venv) [root@pekphisprb70593 chameleon]# pip3 install ./chameleon-3.1.0-py3-none-any.whl
最后提示“Successfully installed chameleon-3.1.0”说明安装成功。
4. 设置配置文件。这里继续使用之前已经配置好的 default.yml ,不清楚的小伙伴移步上一篇。
切换到omm 用户进行操作。
(venv) [root@pekphisprb70593 chameleon]# su - omm
Last login: Tue Oct 25 16:24:30 CST 2022 on pts/0
[omm@pekphisprb70593 ~]$ cd /opt/software/chameleon/
[omm@pekphisprb70593 chameleon]$ python3 -m venv venv
[omm@pekphisprb70593 chameleon]$ source venv/bin/activate
(venv) [omm@pekphisprb70593 chameleon]$ chameleon set_configuration_files
updating configuration example with /home/omm/.pg_chameleon/configuration//config-example.yml
(venv) [omm@pekphisprb70593 chameleon]$ chameleon create_replica_schema --config default
(venv) [omm@pekphisprb70593 chameleon]$ chameleon add_source --config default --source mysql
除了基础数据同步,chameleon还支持将视图、触发器、自定义函数、存储过程从MySQL迁移到openGauss。以下四个命令无先后之分。若不想日志输出到控制台,可去掉–debug参数。
复制视图:
chameleon start_view_replica --config default --source mysql --debug
复制触发器:
chameleon start_trigger_replica --config default --source mysql --debug
复制自定义函数:
chameleon start_func_replica --config default --source mysql --debug
复制存储过程:
chameleon start_proc_replica --config default --source mysql --debug
此外,工具还提供了可以在对象迁移信息表sch_chameleon.t_replica_object中查看迁移对象的记录能力。下表展示了t_replica_object表的字段说明。
| 字段 | 类型 | 描述 |
|---|---|---|
| i_id_object | bigint | id |
| i_id_source | bigint | 与sch_schema.t_sources的id相对应 |
| en_object_type | 枚举类型 | 迁移对象所属类型(VIEW/TRIGGER/FUNC/PROC) |
| ts_created | timestamp with time zone | 迁移时间 |
| b_status | boolean | 迁移状态。true表示迁移成功,false表示迁移失败 |
| t_src_object_sql | text | 原始sql语句 |
| t_dst_object_sql | text | 翻译后的语句。若无法翻译或者翻译出现error的情况为空;openGauss不支持的字段被注释 |
mysql> create view test1_view as
-> select * from test1 where id=1;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from test1_view;
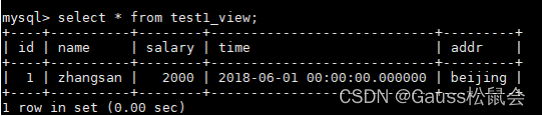
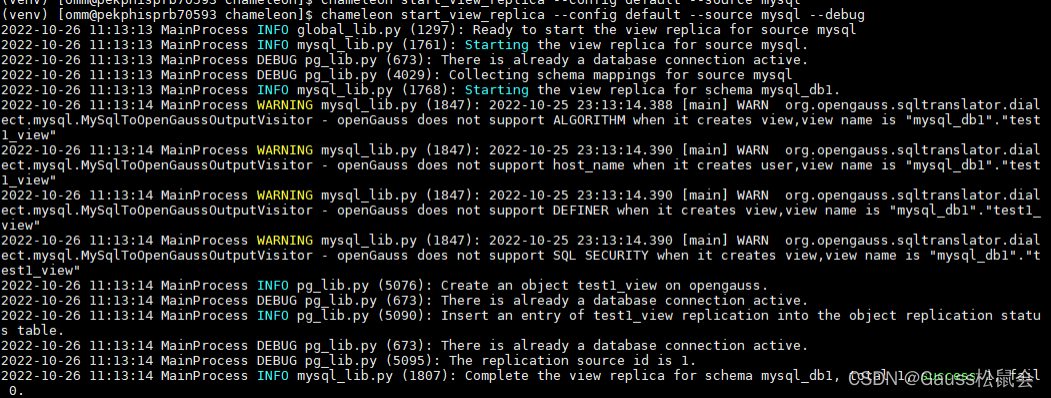
3.在openGauss侧查询视图,迁移成功。注意查询的时候需要携带schema: mysql_db1_sch,视图名称和mysql 中定义的一致,都是test1_view。

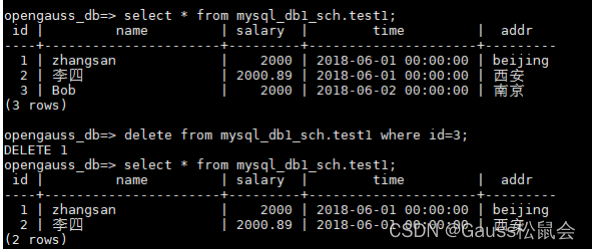
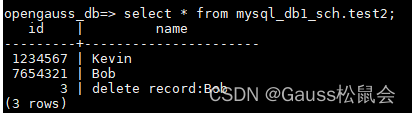
1.mysql 构造如下触发器:每删除一条test1中的数据,就向test2表中插入一条记录。
DELIMITER //
CREATE TRIGGER del_log
AFTER DELETE
ON test1
FOR EACH ROW
BEGIN
INSERT INTO test2(id,name) VALUES (old.id,concat("delete record:",old.name));
END; //
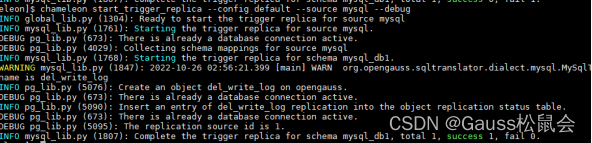
2.工具执行命令,成功
chameleon start_trigger_replica --config default --source mysql --debug
DELIMITER //
create function mysql_func2(x smallint unsigned, y smallint unsigned) returns smallint deterministic
BEGIN
DECLARE a, b SMALLINT UNSIGNED DEFAULT 10;
SET a = x, b = y;
RETURN a+b;
END; //
create function mysql_func1(s char(20))
returns char(50) deterministic
return concat('mysql_func1, ',s,'!')//
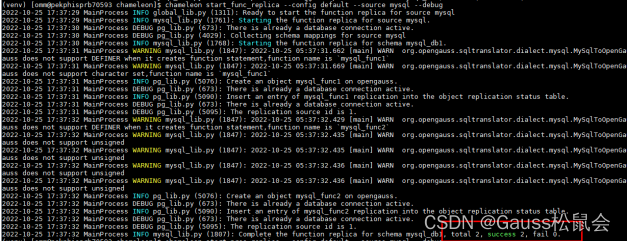
启动迁移操作,如下图所示,总共两个,成功两个。
chameleon start_func_replica --config default --source mysql --debug

DELIMITER //
CREATE PROCEDURE mysql_sp(IN x SMALLINT ,IN y SMALLINT ,OUT sum int)
BEGIN
SET sum = x + y;
END //
DELIMITER ;
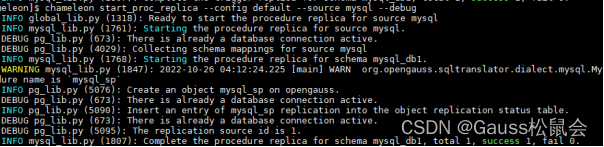
2.工具侧执行迁移,提示总共一个,成功一个。
chameleon start_proc_replica --config default --source mysql --debug
3.openGauss直接测试调用,也是OK的。
1、迁移数据库对象过程中报类似错误“‘replica_engine’ object has no attribute ”
(venv) [omm@pekphisprb70593 configuration]$ chameleon start_func_replica --config default --source mysql --debug
Traceback (most recent call last):
File "/opt/software/chameleon/venv/bin/chameleon", line 5, in <module>
exec(compile(open(__file__).read(), __file__, 'exec'))
File "/opt/software/chameleon/venv/bin/chameleon.py", line 58, in <module>
getattr(replica, args.command)()
AttributeError: 'replica_engine' object has no attribute 'start_func_replica'
这个错误的话是工具3.0.0之前版本还不支持 ,请确认工具版本是3.1.0。
2、迁移触发器限制
create table test1_log(id int not null auto_increment,operation varchar(200) ,oper_time date, primary key (id));
DELIMITER //
CREATE TRIGGER del_write_log
AFTER DELETE
ON test1
FOR EACH ROW
BEGIN
set @t_name = old.name;
INSERT INTO test1_log(operation,oper_time) VALUES (concat("delete record:",@t_name),NOW());
END; //
工具执行迁移命令 ,结果失败了。
2022-10-26 14:37:56 MainProcess ERROR mysql_lib.py (1845): 2022-10-26 02:37:56.294 [main] ERROR org.opengauss.sqltranslator.dialect.mysql.MySqlToOpenGaussOutputVisitor - openGauss does not support set @T_NAME,trigger name is del_write_log
2022-10-26 14:37:56 MainProcess ERROR mysql_lib.py (1845): 2022-10-26 02:37:56.295 [main] ERROR org.opengauss.sqltranslator.dialect.mysql.MySqlToOpenGaussOutputVisitor - openGauss does not support variable started with @,trigger name is del_write_log
openGauss不支持这种变量名加@,因此,实际迁移前需要仔细查看工具使用约束。
🍒如果您觉得博主的文章还不错或者有帮助的话,请关注一下博主,如果三连点赞评论收藏就更好啦!谢谢各位大佬给予的支持!
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,