 首先,到底啥是分布式事务呢,比如我们在执行一个业务逻辑的时候有两步分别操作A数据源和B数据源,当我们在A数据源执行数据更改后,在B数据源执行时出现运行时异常,那么我们必须要让B数据源的操作回滚,并回滚对A数据源的操作;这种情况在支付业务时常常出现;比如买票业务在最后支付失败,那之前的操作必须全部回滚,如果之前的操作分布在多个数据源中,那么这就是典型的分布式事务回滚;了解了什么是分布式事务,那分布式事务在java的解决方案就是JTA(即Java Transaction API);springboot官方提供了 Atomikos or Bitronix的解决思路;其实,大多数情况下很多公司是使用消息队列的方式实现分布式事务。
首先,到底啥是分布式事务呢,比如我们在执行一个业务逻辑的时候有两步分别操作A数据源和B数据源,当我们在A数据源执行数据更改后,在B数据源执行时出现运行时异常,那么我们必须要让B数据源的操作回滚,并回滚对A数据源的操作;这种情况在支付业务时常常出现;比如买票业务在最后支付失败,那之前的操作必须全部回滚,如果之前的操作分布在多个数据源中,那么这就是典型的分布式事务回滚;了解了什么是分布式事务,那分布式事务在java的解决方案就是JTA(即Java Transaction API);springboot官方提供了 Atomikos or Bitronix的解决思路;其实,大多数情况下很多公司是使用消息队列的方式实现分布式事务。本篇文章重点讲解springboot环境下,整合 Atomikos +mysql+mybatis+tomcat/jetty;
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>transactions-jms、transactions-jta、transactions-jdbc、javax.transaction-apispring.datasource.type 是com.alibaba.druid.pool.xa.DruidXADataSource;spring.jta.transaction-manager-id的值在你的电脑中是唯一的,这个详细请阅读官方文档; 完整的yml文件如下:
完整的yml文件如下:spring:
datasource:
type: com.alibaba.druid.pool.xa.DruidXADataSource
druid:
systemDB:
name: systemDB
url: jdbc:mysql://localhost:3306/springboot-mybatis?useUnicode=true&characterEncoding=utf-8
username: root
password: root
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initialSize: 5
minIdle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30
validationQuery: SELECT 1
validationQueryTimeout: 10000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,wall
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
businessDB:
name: businessDB
url: jdbc:mysql://localhost:3306/springboot-mybatis2?useUnicode=true&characterEncoding=utf-8
username: root
password: root
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initialSize: 5
minIdle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30
validationQuery: SELECT 1
validationQueryTimeout: 10000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,wall
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
useGlobalDataSourceStat: true
#jta相关参数配置
jta:
log-dir: classpath:tx-logs
transaction-manager-id: txManagerpackage com.zjt.config;
import com.alibaba.druid.filter.stat.StatFilter;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import com.alibaba.druid.wall.WallConfig;
import com.alibaba.druid.wall.WallFilter;
import com.atomikos.icatch.jta.UserTransactionImp;
import com.atomikos.icatch.jta.UserTransactionManager;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.jta.atomikos.AtomikosDataSourceBean;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.env.Environment;
import org.springframework.transaction.jta.JtaTransactionManager;
import javax.sql.DataSource;
import javax.transaction.UserTransaction;
import java.util.Properties;
/**
* Druid配置
*
*
*/
@Configuration
public class DruidConfig {
@Bean(name = "systemDataSource")
@Primary
@Autowired
public DataSource systemDataSource(Environment env){
AtomikosDataSourceBean ds = new AtomikosDataSourceBean();
Properties prop = build(env, "spring.datasource.druid.systemDB.");
ds.setXaDataSourceClassName("com.alibaba.druid.pool.xa.DruidXADataSource");
ds.setUniqueResourceName("systemDB");
ds.setPoolSize(5);
ds.setXaProperties(prop);
return ds;
}
@Autowired
@Bean(name = "businessDataSource")
public AtomikosDataSourceBean businessDataSource(Environment env){
AtomikosDataSourceBean ds = new AtomikosDataSourceBean();
Properties prop = build(env, "spring.datasource.druid.businessDB.");
ds.setXaDataSourceClassName("com.alibaba.druid.pool.xa.DruidXADataSource");
ds.setUniqueResourceName("businessDB");
ds.setPoolSize(5);
ds.setXaProperties(prop);
return ds;
}
/**
* 注入事物管理器
* @return
*/
@Bean(name = "xatx")
public JtaTransactionManager regTransactionManager (){
UserTransactionManager userTransactionManager = new UserTransactionManager();
UserTransaction userTransaction = new UserTransactionImp();
return new JtaTransactionManager(userTransaction, userTransactionManager);
}
private Properties build(Environment env, String prefix){
Properties prop = new Properties();
prop.put("url", env.getProperty(prefix + "url"));
prop.put("username", env.getProperty(prefix + "username"));
prop.put("password", env.getProperty(prefix + "password"));
prop.put("driverClassName", env.getProperty(prefix + "driverClassName", ""));
prop.put("initialSize", env.getProperty(prefix + "initialSize", Integer.class));
prop.put("maxActive", env.getProperty(prefix + "maxActive", Integer.class));
prop.put("minIdle", env.getProperty(prefix + "minIdle", Integer.class));
prop.put("maxWait", env.getProperty(prefix + "maxWait", Integer.class));
prop.put("poolPreparedStatements", env.getProperty(prefix + "poolPreparedStatements", Boolean.class));
prop.put("maxPoolPreparedStatementPerConnectionSize",
env.getProperty(prefix + "maxPoolPreparedStatementPerConnectionSize", Integer.class));
prop.put("maxPoolPreparedStatementPerConnectionSize",
env.getProperty(prefix + "maxPoolPreparedStatementPerConnectionSize", Integer.class));
prop.put("validationQuery", env.getProperty(prefix + "validationQuery"));
prop.put("validationQueryTimeout", env.getProperty(prefix + "validationQueryTimeout", Integer.class));
prop.put("testOnBorrow", env.getProperty(prefix + "testOnBorrow", Boolean.class));
prop.put("testOnReturn", env.getProperty(prefix + "testOnReturn", Boolean.class));
prop.put("testWhileIdle", env.getProperty(prefix + "testWhileIdle", Boolean.class));
prop.put("timeBetweenEvictionRunsMillis",
env.getProperty(prefix + "timeBetweenEvictionRunsMillis", Integer.class));
prop.put("minEvictableIdleTimeMillis", env.getProperty(prefix + "minEvictableIdleTimeMillis", Integer.class));
prop.put("filters", env.getProperty(prefix + "filters"));
return prop;
}
@Bean
public ServletRegistrationBean druidServlet(){
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
//控制台管理用户,加入下面2行 进入druid后台就需要登录
//servletRegistrationBean.addInitParameter("loginUsername", "admin");
//servletRegistrationBean.addInitParameter("loginPassword", "admin");
return servletRegistrationBean;
}
@Bean
public FilterRegistrationBean filterRegistrationBean(){
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new WebStatFilter());
filterRegistrationBean.addUrlPatterns("/*");
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
filterRegistrationBean.addInitParameter("profileEnable", "true");
return filterRegistrationBean;
}
@Bean
public StatFilter statFilter(){
StatFilter statFilter = new StatFilter();
statFilter.setLogSlowSql(true); //slowSqlMillis用来配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢。
statFilter.setMergeSql(true); //SQL合并配置
statFilter.setSlowSqlMillis(1000);//slowSqlMillis的缺省值为3000,也就是3秒。
return statFilter;
}
@Bean
public WallFilter wallFilter(){
WallFilter wallFilter = new WallFilter();
//允许执行多条SQL
WallConfig config = new WallConfig();
config.setMultiStatementAllow(true);
wallFilter.setConfig(config);
return wallFilter;
}
}package com.zjt.config;
import com.zjt.util.MyMapper;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.io.support.ResourcePatternResolver;
import javax.sql.DataSource;
/**
*
* @description
*/
@Configuration
// 精确到 mapper 目录,以便跟其他数据源隔离
@MapperScan(basePackages = "com.zjt.mapper", markerInterface = MyMapper.class, sqlSessionFactoryRef = "sqlSessionFactory")
public class MybatisDatasourceConfig {
@Autowired
@Qualifier("systemDataSource")
private DataSource ds;
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(ds);
//指定mapper xml目录
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
factoryBean.setMapperLocations(resolver.getResources("classpath:mapper/*.xml"));
return factoryBean.getObject();
}
@Bean
public SqlSessionTemplate sqlSessionTemplate() throws Exception {
SqlSessionTemplate template = new SqlSessionTemplate(sqlSessionFactory()); // 使用上面配置的Factory
return template;
}
//关于事务管理器,不管是JPA还是JDBC等都实现自接口 PlatformTransactionManager
// 如果你添加的是 spring-boot-starter-jdbc 依赖,框架会默认注入 DataSourceTransactionManager 实例。
//在Spring容器中,我们手工注解@Bean 将被优先加载,框架不会重新实例化其他的 PlatformTransactionManager 实现类。
/*@Bean(name = "transactionManager")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
//MyBatis自动参与到spring事务管理中,无需额外配置,只要org.mybatis.spring.SqlSessionFactoryBean引用的数据源
// 与DataSourceTransactionManager引用的数据源一致即可,否则事务管理会不起作用。
return new DataSourceTransactionManager(ds);
}*/
}package com.zjt.config;
import com.zjt.util.MyMapper;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.io.support.ResourcePatternResolver;
import javax.sql.DataSource;
/**
*
* @description
*/
@Configuration
// 精确到 mapper 目录,以便跟其他数据源隔离
@MapperScan(basePackages = "com.zjt.mapper2", markerInterface = MyMapper.class, sqlSessionFactoryRef = "sqlSessionFactory2")
public class MybatisDatasource2Config {
@Autowired
@Qualifier("businessDataSource")
private DataSource ds;
@Bean
public SqlSessionFactory sqlSessionFactory2() throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(ds);
//指定mapper xml目录
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
factoryBean.setMapperLocations(resolver.getResources("classpath:mapper2/*.xml"));
return factoryBean.getObject();
}
@Bean
public SqlSessionTemplate sqlSessionTemplate2() throws Exception {
SqlSessionTemplate template = new SqlSessionTemplate(sqlSessionFactory2()); // 使用上面配置的Factory
return template;
}
//关于事务管理器,不管是JPA还是JDBC等都实现自接口 PlatformTransactionManager
// 如果你添加的是 spring-boot-starter-jdbc 依赖,框架会默认注入 DataSourceTransactionManager 实例。
//在Spring容器中,我们手工注解@Bean 将被优先加载,框架不会重新实例化其他的 PlatformTransactionManager 实现类。
/*@Bean(name = "transactionManager2")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
//MyBatis自动参与到spring事务管理中,无需额外配置,只要org.mybatis.spring.SqlSessionFactoryBean引用的数据源
// 与DataSourceTransactionManager引用的数据源一致即可,否则事务管理会不起作用。
return new DataSourceTransactionManager(ds);
}*/
}TxAdviceInterceptor.java和TxAdvice2Interceptor.java中配置的事务管理器了;有需求的童鞋可以自己配置其他的事务管理器;(见DruidConfig.java中查看)classService.saveOrUpdateTClass(tClass);和teacherService.saveOrUpdateTeacher(teacher);实现先后操作两个数据源:然后我们可以自己debug跟踪事务的提交时机,此外,也可以在在两个方法全执行结束之后,手动制造一个运行时异常,来检查分布式事务是否全部回滚;注意:在实现类的方法中我使用的是:@Transactional(transactionManager = "xatx", propagation = Propagation.REQUIRED, rollbackFor = { java.lang.RuntimeException.class })package com.zjt.service3;
import java.util.Map;
public interface JtaTestService {
public Map<String,Object> test01();
}package com.zjt.service3.impl;
import com.zjt.entity.TClass;
import com.zjt.entity.Teacher;
import com.zjt.service.TClassService;
import com.zjt.service2.TeacherService;
import com.zjt.service3.JtaTestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
import java.util.LinkedHashMap;
import java.util.Map;
@Service("jtaTestServiceImpl")
public class JtaTestServiceImpl implements JtaTestService{
@Autowired
@Qualifier("teacherServiceImpl")
private TeacherService teacherService;
@Autowired
@Qualifier("tclassServiceImpl")
private TClassService tclassService;
@Override
@Transactional(transactionManager = "xatx", propagation = Propagation.REQUIRED, rollbackFor = { java.lang.RuntimeException.class })
public Map<String, Object> test01() {
LinkedHashMap<String,Object> resultMap=new LinkedHashMap<String,Object>();
TClass tClass=new TClass();
tClass.setName("8888");
tclassService.saveOrUpdateTClass(tClass);
Teacher teacher=new Teacher();
teacher.setName("8888");
teacherService.saveOrUpdateTeacher(teacher);
System.out.println(1/0);
resultMap.put("state","success");
resultMap.put("message","分布式事务同步成功");
return resultMap;
}
}package com.zjt.web;
import com.zjt.service3.JtaTestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.LinkedHashMap;
import java.util.Map;
@Controller
@RequestMapping("/jtaTest")
public class JtaTestContoller {
@Autowired
@Qualifier("jtaTestServiceImpl")
private JtaTestService taTestService;
@ResponseBody
@RequestMapping("/test01")
public Map<String,Object> test01(){
LinkedHashMap<String,Object> resultMap=new LinkedHashMap<String,Object>();
try {
return taTestService.test01();
}catch (Exception e){
resultMap.put("state","fail");
resultMap.put("message","分布式事务同步失败");
return resultMap;
}
}
}//分布式事务测试
$("#JTATest").click(function(){
$.ajax({
type: "POST",
url: "${basePath!}/jtaTest/test01",
data: {} ,
async: false,
error: function (request) {
layer.alert("与服务器连接失败/(ㄒoㄒ)/~~");
return false;
},
success: function (data) {
if (data.state == 'fail') {
layer.alert(data.message);
return false;
}else if(data.state == 'success'){
layer.alert(data.message);
}
}
});
});
<button class="layui-btn" id="JTATest">同时向班级和老师表插入名为8888的班级和老师</button> 点击这个按钮,跳转到controller:
点击这个按钮,跳转到controller: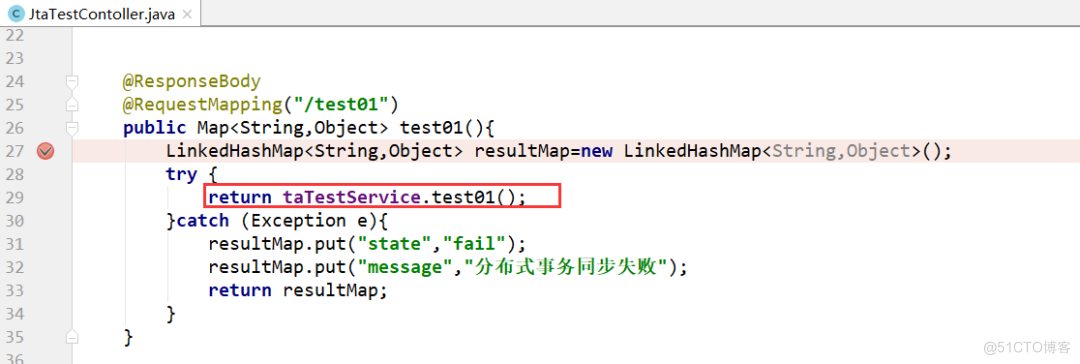 当正常执行了sql语句之后,我们可以发现数据库并没有变化,因为整个方法的事务还没有走完,当我们走到1/0这步时:
当正常执行了sql语句之后,我们可以发现数据库并没有变化,因为整个方法的事务还没有走完,当我们走到1/0这步时: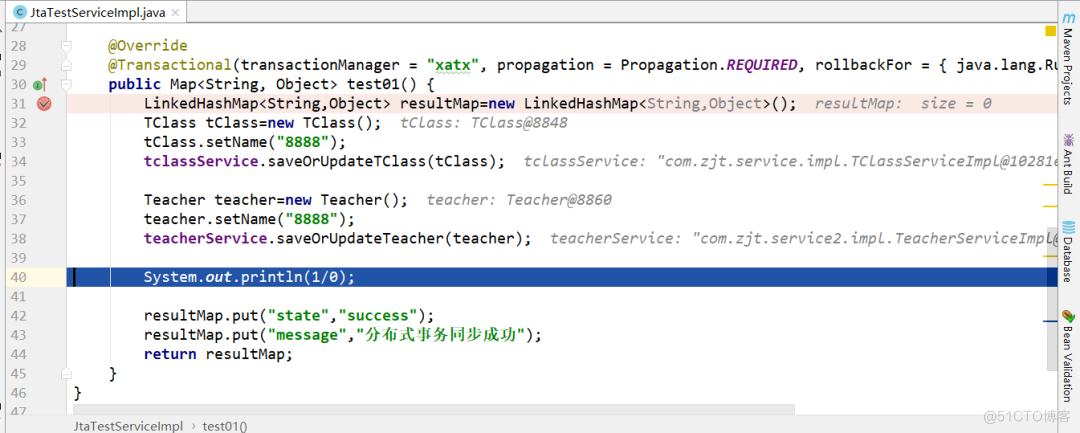 抛出运行时异常,并被spring事务拦截器拦截,并捕获异常:
抛出运行时异常,并被spring事务拦截器拦截,并捕获异常: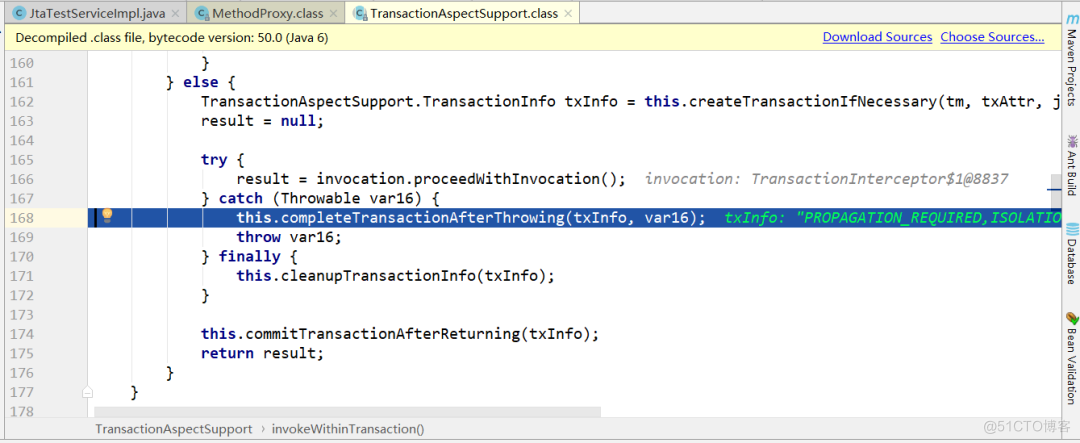 在
在this.completeTransactionAfterThrowing(txInfo, var16);方法中会将事务全部回滚:22:09:04.243 logback [http-nio-8080-exec-5] INFO c.a.i.imp.CompositeTransactionImp - rollback() done of transaction 192.168.1.103.tm0000400006在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
Enumerable#each和Enumerable#map的区别在于返回的是接收者还是映射后的结果。回到接收者是微不足道的,你通常不需要在each之后继续一个方法链,比如each{...}.another_method(我可能没见过这样的案例。即使你想回到接收者那里,你也可以通过tap来实现)。所以我认为所有或者大部分使用Enumerable#each的情况都可以用Enumerable#map代替。我错了吗?如果我是对的,each的目的是什么?map是否比each慢?编辑:我知道当您对返回值不感兴趣时使用each是一种常见的做法。我对这种做法是否存在不感兴趣,但感兴趣的是,除了从
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我想知道是否有人知道Ruby的rubyzip替代品,它可以处理各种格式,特别是zip/rar/7z?我知道libarchive,但它对我的目的来说并不完整(它是一个很好的gem)。(澄清一下,libarchive-对我不起作用-因为
我目前正在上一门数据库类(class),其中一个实验室问题让我困惑于如何实现上述内容,事实上,如果可能的话。我试过搜索docs但是定义的交易方式比较模糊。这是我第一次尝试在没有Rails的情况下进行任何数据库操作,所以我有点迷茫。我已经成功地创建了一个到我的postgresql数据库的连接并且可以执行语句,我需要做的最后一件事是根据一个简单的条件回滚一个事务。请允许我向您展示代码:require'pg'@conn=PG::Connection.open(:dbname=>'db_15_11_labs')@conn.prepare('insert','INSERTINTOhouse(ho
我爱Sanitize.这是一个了不起的实用程序。我遇到的唯一问题是,它需要永远准备一个开发环境,因为它使用Nokogiri,这对编译时间来说是一种痛苦。是否有任何程序可以在不使用Nokogiri的情况下执行Sanitize的操作(如果没有别的,只是温和地执行它的操作)?这将以指数方式提供帮助! 最佳答案 Rails有自己的SanitizeHelper。根据http://api.rubyonrails.org/classes/ActionView/Helpers/SanitizeHelper.html,它将Thissanitizehe