
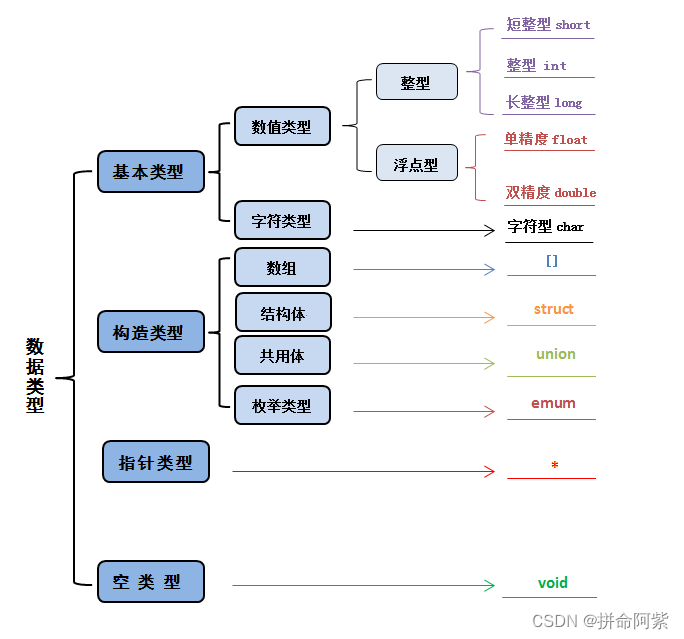
目录
在学习C语言数据类型之前,我们得先了解:为什么要有类型? 类型为什么有这么多种类?
①为什么要有类型?
答:类型本质是对内存进行合理化划分,按需索取
② 类型为什么有这么多种类?
答:应用场景不同,解决应用场景对应的计算方式不同,需要空间的大小也不同。 (本质:用最小成本,解决各种多样化的场景问题)
了解这两个问题之后我们也就知道了 变量定义:是什么?为什么?怎么办?
定义变量格式:类型 变量名 = 初始化;
(定义变量时 :类型决定了变量需要开辟多大内存空间)
辅助理解: 数据类型跟制作月饼模具很类似

如果我们要制作一个小月饼,我们肯定会运用小模具去制作,不会去用大模具去应用,原因是因为小模具可以制作不会造成空间浪费,大模具会造成空间浪费。
数据类型也是如此 如果我们要存储一个字符我们会选择运用 char 类型去存储,不会想着用 int 类型,因为一个字符只占一个字节,刚好 char 类型也只开辟一个字节,而 int 类型开辟4个字节就会造成空间浪费
那我们接来下我们学习一下C语言中常见的内置内类的大小:

为什么 long 跟 int 占用的空间一样大?
为什么说它是最冤枉的关键字?
sizeof是关键字不是函数,但是还是会有人认为它是函数。因为我们大部分使用它的时候后面会跟括号 例如:sizeof(int),函数的使用方法也是这样。
那下面我们一起来为这个关键字洗清冤屈吧,证明它不是函数吧!
我们用编译器来证明它是关键字不是函数:
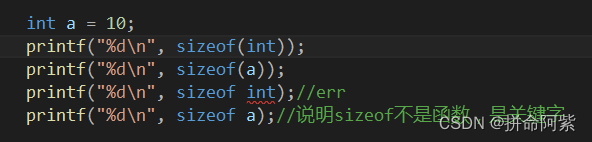
从哪看出来它不是函数而是关键字的了?为什么第三个 printf ( ) 会报错了?
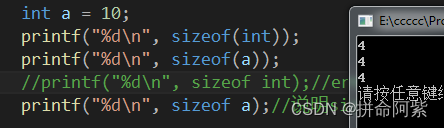
将第三个printf( )屏蔽后,程序也就可以正常运行了。
注:sizeof 在计算变量所占空间大小时,括号可以省略,而计算类型大小时不能省略。
一个变量的创建是要在内存中开辟空间的,空间的大小是根据不同的类型而决定的
那么整型数据在所开辟的内存中是如何存储的了?
①有符号数
int a = 10;
int b = -10;有符号数可以分为正数和负数
计算机内存储的整型必须是补码,由此我们便引出了原、反、补码的概念
正数的原码、反码、补码相同
负数的原码、反码、补码不相同,故负数的原码、反码、补码需要相互转换
任何数据在计算机中,都必须被转化成二进制,这是为什么呢?
答:因为计算机只认识二进制
计算机内存储的整型为什么必须是补码?
答:在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理; 同 时,加法和减法也可以统一处理(CPU只有加法器)。此外,补码与原码相互转换,其运算过程是相同的,不 需要额外的硬件电路
原码、反码、补码三种表示方法均有符号位和数值位两部分
例1:signed int a = 10
先将字面值转为补码,然后把补码放入变量 a 中
原码:00000000 00000000 00000000 00001010
因为 10 为正数,故 原码、反码 相同
反码:00000000 00000000 00000000 00001010
补码:00000000 00000000 00000000 00001010
例2:signed int a = -10
先将字面值转为补码,然后把补码放入变量 a 中
原码: 10000000 00000000 00000000 00001010
因为 -10 为负数,故 原码、反码 不相同
反码: 11111111 11111111 11111111 11110101
补码: 11111111 11111111 11111111 11110110
注:在vs中基本类型如果不带 signed 和 unsigned,默认都是有符号的,但是在其他编译器里面就不一定了(大部分不带都是表示有符号的)
补码转原码
方法一:补码 -1 = 反码 反码取反 = 原码
例如:
补码:11111111 11111111 11111111 11101100
反码:11111111 11111111 11111111 11101011
原码:10000000 00000000 00000000 00010100
方法二:补码符号位不变其他位按位取反,然后+1=原码
好处:可以使用一条硬件电路,完成转换
例如:
补码:11111111 11111111 11111111 11101100
10000000 00000000 00000000 00010011
原码: 10000000 00000000 00000000 00010100
②无符号数
没有符号位,也就说明了 原码 = 反码 = 补码,那我们在取一个无符号整型变量时 也就可以直接取
例如:unsigned int a = -10
原码: 10000000 00000000 00000000 00001010
反码: 11111111 11111111 11111111 11110101
补码: 11111111 11111111 11111111 11110110
把 -10 的补码存入 无符号整型 a 中,在读取 a 变量里面的值时默认它是无符号的 直接将它里面存的数值转换为十进制打印。


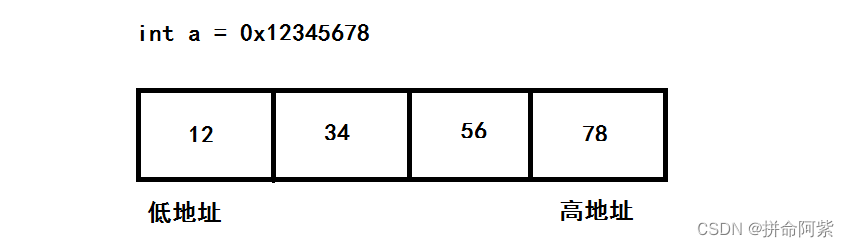
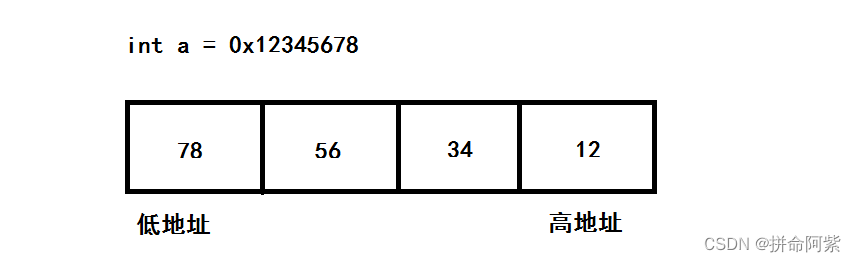
我们可以通过上图发现在给变量赋值时顺序是十六进制12345678,但在内存中显示的十六进制的顺序却相反了,由此我们可以引入一个概念 大小端

int a = 0x12345678

大小端就是把高权值放在高地址处还是低地址处的问题?
但是无论怎么放,只要用同等条件去取都可以
大端(存储)模式:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址 中
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地 址中
最后祝大家端午安康!

我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
我有一台生产机器和一台开发机器,都运行ubuntu8.10并且都运行最新的phusionpassenger。当我在osx上的本地开发机器上使用ruby1.9.1时,我想知道外面的人是否已经在使用带有ruby1.9.1甚至1.9.2的phusionpassenger?如果是这样,请告诉我们您的设置!此外,有没有办法在apache上使用phusionpassenger同时运行ruby1.8.7(ree)和1.9.1?感谢您的指点,我在任何地方都找不到任何提示... 最佳答案 是的,从某些2.2.x版本开始就正式支持它,我不记
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?