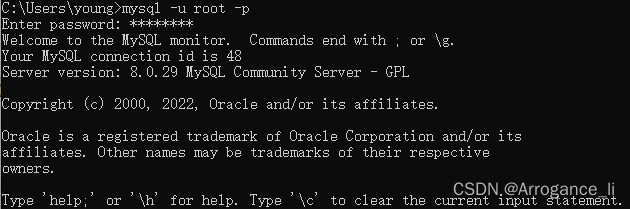
1.进入MySQL
WIN + R 输入cmd
输入mysql -u root -p
输入密码进入mysql
2.
输入show databases;
查询现有数据库

选择一个数据库
use 数据库名称
创建一个学生表
create table stu(
id int ,-- 编号
name varchar(10),-- 姓名
gender char(1),-- 性别
birthday date,-- 生日
score double(5,2) ,-- 分数
email varchar(64),-- 邮箱
tel varchar(20),-- 手机号
status tinyint-- 状态
);
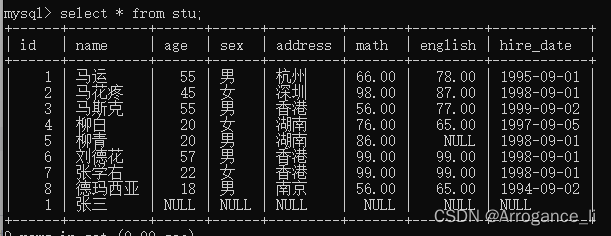
1.查询所有数据
select * from stu;

2.给指定列添加数据INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);
INSERT INTO stu (id, NAME)
VALUES
(1, '张三');
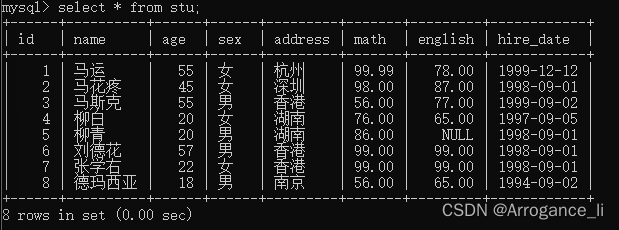
3.修改数据 UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件]
-- 将马运的性别改成女
update stu set sex = '女' where name = '马运';

-- 将张三的生日改为 1999-12-12 数学分数改为99.99
update stu set hire_date = '1999-12-12', math = '99.99' where name = '马运';
-- 注意:如果update语句没有加where条件,则会将表中所有数据全部修改!
4.删除数据 DELETE FROM 表名 [WHERE 条件] ;
-- 删除张三记录
delete from stu where name = '张三';

4.条件查询
-- 1.查询年龄大于20岁的学员信息
select * from stu where age > 20;

-- 2.查询年龄大于等于20岁的学员信息
select * from stu where age >=20;
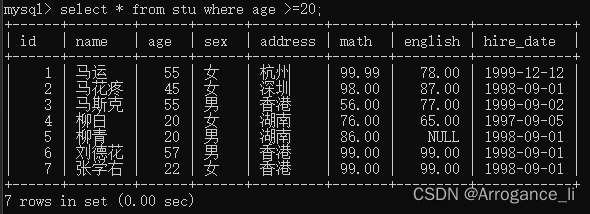
-- 3.查询年龄大于等于20岁 并且 年龄 小于等于 30岁 的学员信息
select * from stu where age > =20 && age <=30;
select * from stu where age > =20 and age <=30;
select * from stu where age between 20 and 30;
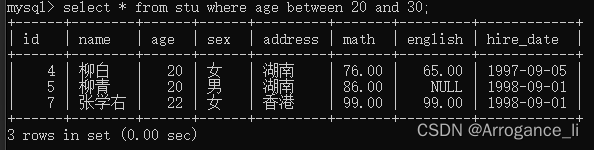
-- 4.查询入学日期在'1998-09-01' 到 '1999-09-01' 之间的学员信息
select *from stu where hire_date between '1998-09-01' and '1999-09-01';
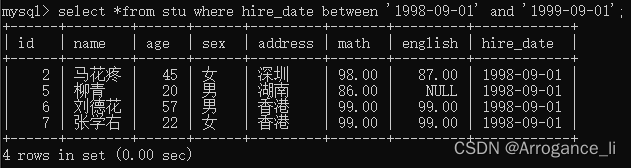
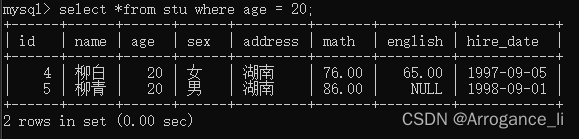
-- 5. 查询年龄等于20岁的学员信息
select *from stu where age = 20;
-- 6. 查询年龄不等于20岁的学员信息
select *from stu where age != 20;
select *from stu where age <> 20;

-- 7. 查询年龄等于20岁 或者 年龄等于22岁 或者 年龄等于55岁的学员信息
select *from stu where age = 20 or age = 22 or age =55;
select * from stu where age in (20,22 ,55);

-- 8. 查询英语成绩为 null的学员信息
-- 注意: null值的比较不能使用 = != 。需要使用 is is not
select * from stu where english = null; -- 不行的
select * from stu where english is null;
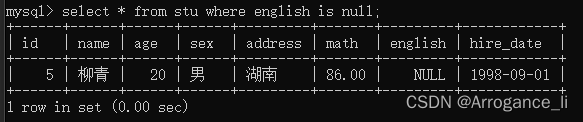
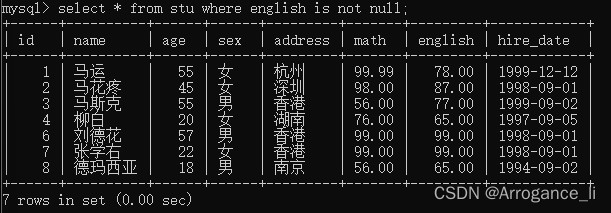
select * from stu where english is not null;
5.模糊查询
-- 模糊查询 like =====================
/*
通配符:
(1)_:代表单个任意字符
(2)%:代表任意个数字符
*/
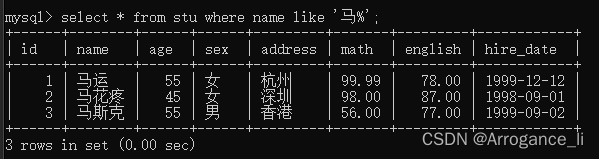
-- 1. 查询姓'马'的学员信息
select * from stu where name like '马%';
-- 2. 查询第二个字是'花'的学员信息
select * from stu where name like '_花%';

-- 3. 查询名字中包含 '德' 的学员信息
select * from stu where name like '%德%';

6.排序查询
排序查询:
* 语法:SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
* 排序方式:
* ASC:升序排列(默认值)
* DESC:降序排列
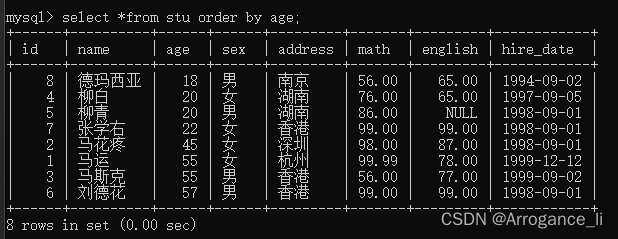
-- 1.查询学生信息,按照年龄升序排序
select *from stu order by age;
-- 2.查询学生信息,按照数学成绩降序排列
select *from stu order by age desc;
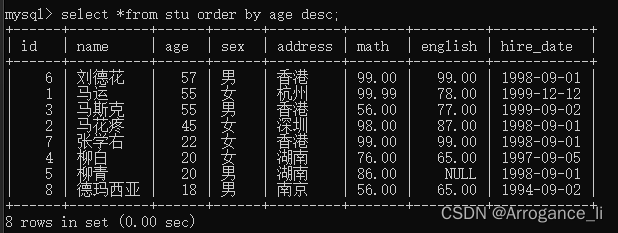
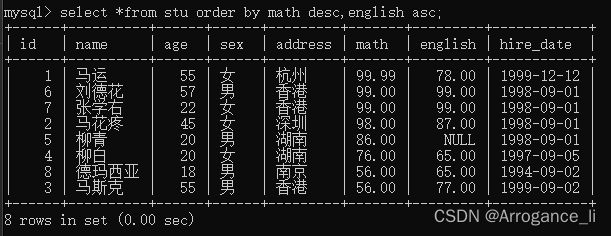
-- 3.查询学生信息,按照数学成绩降序排列,如果数学成绩一样,再按照英语成绩升序排列
select *from stu order by math desc,english asc;
7.分组函数
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤]…;
-- 1. 查询男同学和女同学各自的数学平均分
select sex,avg(math) from stu group by sex;
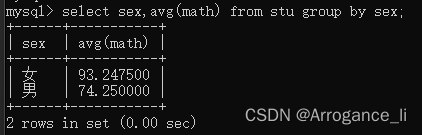
注意:分组之后,查询的字段只能为聚合函数和分组函数,查询其他字段无意义
-- 2. 查询男同学和女同学各自的数学平均分,以及各自人数
select sex,avg(math),count(*) from stu group by sex;

-- 3. 查询男同学和女同学各自的数学平均分,以及各自人数,要求:数学分数低于70分的不参与分组
select sex,avg(math),count(*) from stu where math > 70 group by sex ;

-- 4. 查询男同学和女同学各自的数学平均分,以及各自人数,要求:数学分数低于70分的不参与分组,分组之后人数大于1个的。
select sex,avg(math),count(*) from stu where math > 70 group by sex having count(*) > 1 ;

8.分页查询:
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数
* 起始索引:从0开始
-- 1. 从0开始查询,查询3条数据
select * from stu limit 0,3;
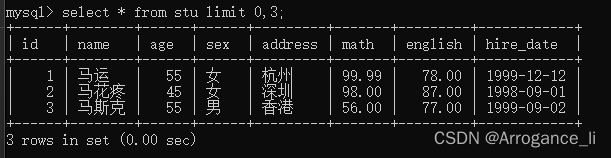
-- 2. 每页显示3条数据,查询第1页数据
select * from stu limit 0,3;
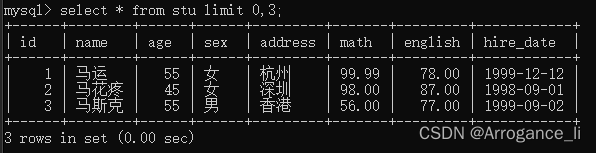
-- 3. 每页显示3条数据,查询第2页数据
select * from stu limit 3,3;
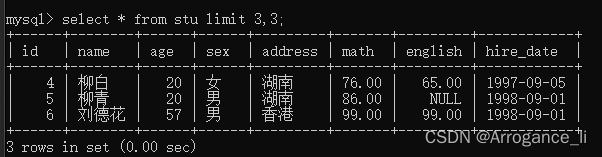
-- 4. 每页显示3条数据,查询第3页数据
select * from stu limit 6,3;
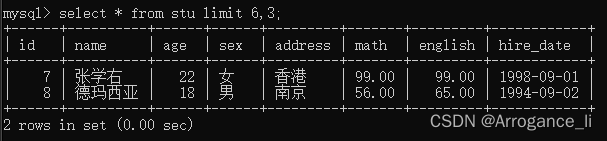
-- 起始索引 = (当前页码 - 1) * 每页显示的条数
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您