采用遗传算法进行25个城市的TSP问题求解,通过遗传算法求解得出的最短路径值为29085.91,最优路径为24→15→25→20→19→6→8→17→3→13→7→5→11→1→2→14→4→9→12→21→10→16→22→18→23→24(数字为城市序号)。同时根据不同参数下的实验结果,得出结论,随着种群数量的增长及迭代次数的越来越多,遗传算法寻优的结果越来越好。当然,由于遗传算法本身具有一定的随机性,能否快速收敛得看具体参数设定。
遗传算法是一种基于自然选择和群体遗传机理的搜索算法,它模拟了自然选择和自然遗传过程中的繁殖、杂交和突变现象。
在利用遗传算法求解问题时,问题的每一个可能解都被编码成一个“染色体”,即个体,若干个个体构成了群体(所有可能解)。在遗传算法开始时,总是随机的产生一些个体(即初始解),根据预定的目标函数对每一个个体进行评估给出一个适应度值。基于此适应度值,选择一些个体用来产生下一代,选择操作体现了“适者生存"的原理,“好”的个体被用来产生下一代,“坏”的个体则被淘汰,然后选择出来的个体经过交叉和变异算子进行再组合生成新的一代,这一代的个体由于继承了上一代的一些优良性状,因而在性能上要优于上一代,这样逐步朝着最优解的方向进化。
因此,遗传算法可以看成是一个由可行解组成的群体初步进化的过程。
步骤一:设置 TSP 问题中25个城市的坐标值,限制每个城市只能拜访一次,并且回到出发的城市。本实验中25个城市坐标如下:
[1549,3408; 1561,2641; 3904,3453; 2216,1177; 1563,4906;
3554,827; 2578,4370; 3358,2054; 143,4789; 610,774;
1557,4064; 771,1823; 4753,4192; 2037,1897; 4692,1887;
839,415; 4314,2696; 428,3626; 2725,543; 2349,263;
770,2550; 1627,1361; 2139,3908; 1977,2775; 4345,11];步骤二:设置种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1;
步骤三:初始化种群,计算每个个体的适应度值(即路径长短),执行交叉、变异、选择操作,生成新的种群;
步骤四:判断终止条件(如果满足,则迭代结束。输出最终最短路径值以及绘制最优路径图;否则继续迭代优化,并实时更新最短路径值以及最优路径图)。
主程序源代码(mian.m文件)如下:
%% 采用遗传算法进行TSP问题求解
%% 清理参数及原始变量
clear al1;
close all;
clc;
%% 设置25个城市坐标
C=[1549,3408;1561,2641;3904,3453;2216,1177;1563,4906;
3554,827;2578,4370;3358,2054;143,4789;610,774;
1557,4064;771,1823;4753,4192;2037,1897;4692,1887;
839,415;4314,2696;428,3626;2725,543;2349,263;
770,2550;1627,1361;2139,3908;1977,2775;4345,11];
%% 设置参数
P=100; % 种群容量
N=size(C,1); % 城市个数
maxIter=1000; % 最大迭代次数
Pm=0.1; % 变异概率
%% 开始寻优
% 初始种群
Chro=[];
for i=1:P
temp=randperm(N);
Chro=[Chro;temp];
end
% 计算种群中每个染色的适应度
fit=fitness(Chro,C);
for iter=1:maxIter
% 交叉
for i=1:P/2
chro1=Chro(i,:); % 交叉配对中的第1个染色体
chro2=Chro(i+P/2,:); % 交叉配对中的第2个染色体
pos=randi(N-2)+1; % 随机选取交叉位置
new_chro1=[chro1(1:pos) chro2(pos+1:end)]; % 新的染色体
new_chro2=[chro2(1:pos) chro1(pos+1:end)]; % 新的染色体
chro1_handled=handle(new_chro1);
chro2_handled=handle(new_chro2);
Chro(i,:)=chro1_handled;
Chro(i+P/2,:)=chro2_handled;
end
% 变异
for i=1:P
if rand()<Pm
pos1=randi(N);
while 1
pos2=randi(N);
if pos2~=pos1
break;
end
end
temp=Chro(i,pos2);
Chro(i,pos2)=Chro(i,pos1);
Chro(i,pos1)=temp;
end
end
% 选择
fit=fitness(Chro,C);
fit=1./fit;
prob=fit/sum(fit);
prob=cumsum(prob);
Chro_sel=[];
for i=1:P
rand_p=rand(1);
for j=1:P
if rand_p<=prob(j)
Chro_sel=[Chro_sel;Chro(j,:)];
break;
end
end
end
Chro=Chro_sel;
%% 绘制找到的最好路径
clf
fit=fitness(Chro,C);
plot(C(:,1),C(:,2),'o');
hold on;
[minV,bestPos]=min(fit);
Optimalpath_length(iter)=minV;
minV1=min(Optimalpath_length);
if minV<=minV1
bestChro=Chro(bestPos,:);
bestChro=[bestChro bestChro(1)];
end
for j=1:N
plot(C(bestChro(j:j+1),1),C(bestChro(j:j+1),2),'r-');
end
grid ;%%显示网格
xlabel('横向空间位置');
ylabel('纵向空间位置');
title(['种群容量:' num2str(P) ' ' '迭代次数:' num2str(iter) ' ' '最优路径长度:' num2str(minV1)]);
pause(0.1);
end去重函数源代码(handle.m文件)如下:
%% 处理染色体中重复基因
function chro_handled=handle(chro)
bzw=zeros(1,length(chro)); % 标志位全置为0
bzw(chro)=1; % 有基因的位置置为1,没出现的基因还保持0
unused=find(bzw==0); % 找到标志位为0的索引,即没用过的基因
if isempty(unused) % 如果unused 为空,代表没有重复基因
chro_handled=chro; % 处理后的染色体为原来的染色体
else % 否则,将重复的基因替换位为用到的基因
for i=1:length(chro) % 找到重复的删掉,即置为0
if sum(chro(i)==chro(1:i-1))>0
chro(i)=0;
end
end
idx=find(chro==0); % 找到删掉的基因所在的位置
for i=1:length(idx) % 逐个替换位未使用的基因
chro(idx(i))=unused(i);
end
end
chro_handled=chro; % 返回值为处理后的染色体
end适应度函数源代码(fitness.m文件)如下:
%% 计算适应度,即路径的长度
function fit=fitness(Chro,C)
for i=1:size(Chro,1)
possible_sol=Chro(i,:); % 拿到1个染色体
possible_sol=[possible_sol possible_sol(1)]; % 将第一个城市坐标补充到末尾
dist=0; % 用于计算总距离
for j=1:length(possible_sol)-1
city1=possible_sol(j); % 第j个城市的编号
city2=possible_sol(j+1); % 第j+1个城市的编号
city1_C=C(city1,:); % 第j个城市的坐标
city2_C=C(city2,:); % 第j+1个城市的坐标
dist=dist+norm(city1_C-city2_C); % 第j个城市和第j+1个城市的距离
end
fit(i)=dist;
end
end种群数量 P=20,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:
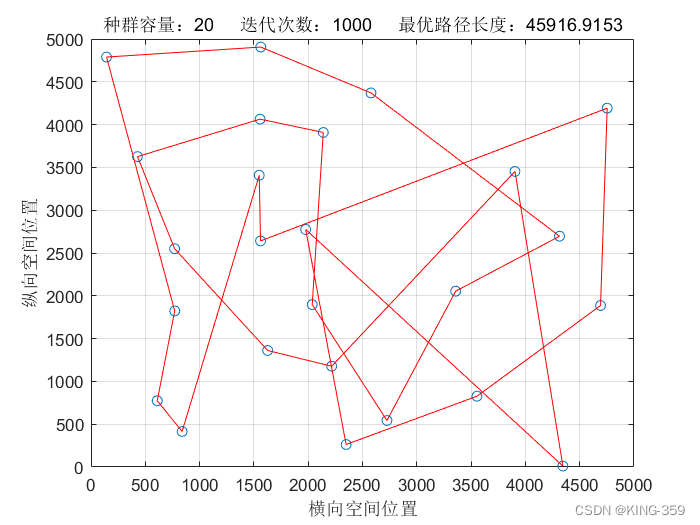
图1.1
种群数量 P=40,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:
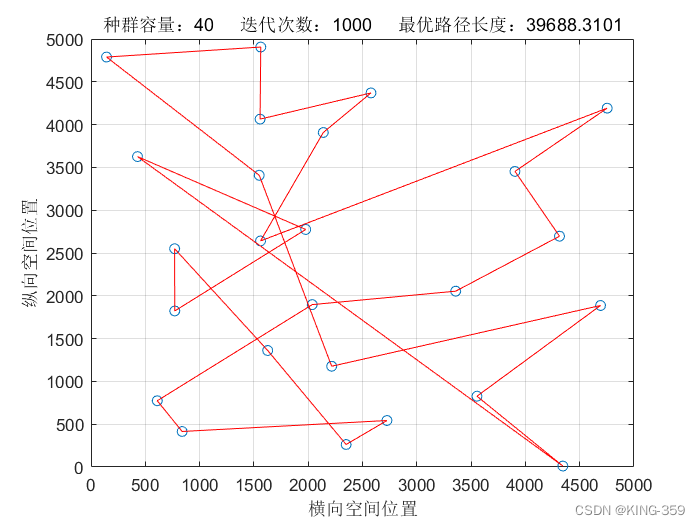
图1.2
种群数量 P=60,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:
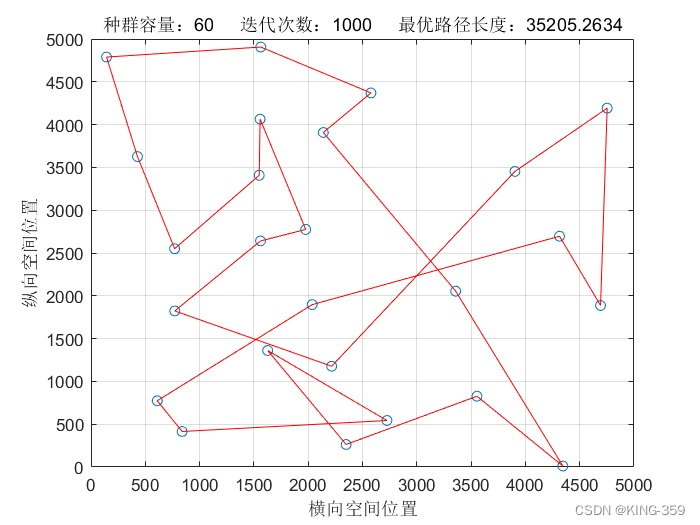
图1.3
种群数量 P=80,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:
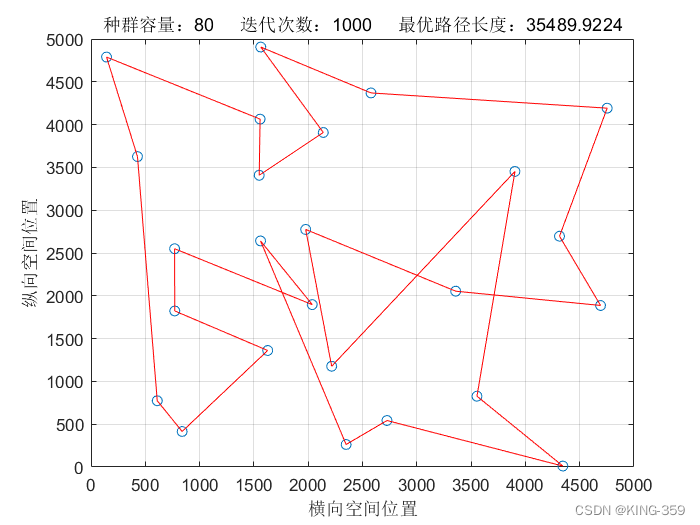
图1.4
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:

图1.5
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=200,变异概率 Pm=0.1时,实验结果如下图所示:
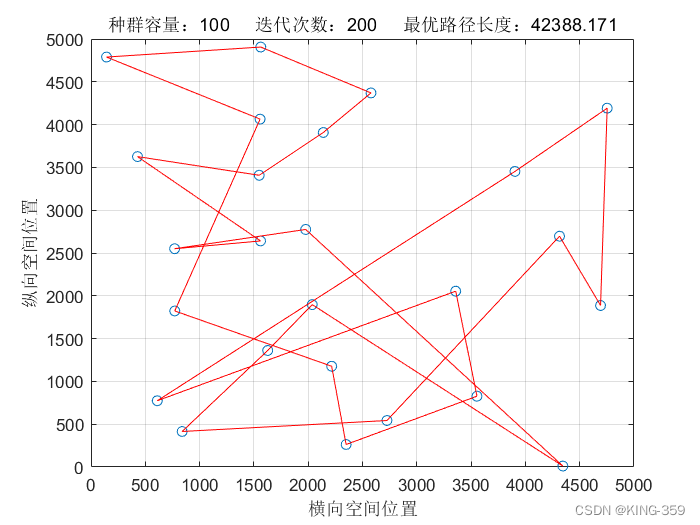
图1.6
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=400,变异概率 Pm=0.1时,实验结果如下图所示:
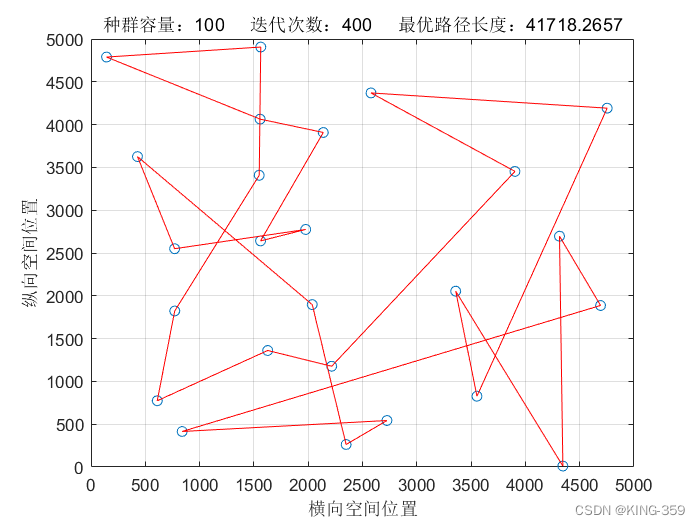
图1.7
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=600,变异概率 Pm=0.1时,实验结果如下图所示:
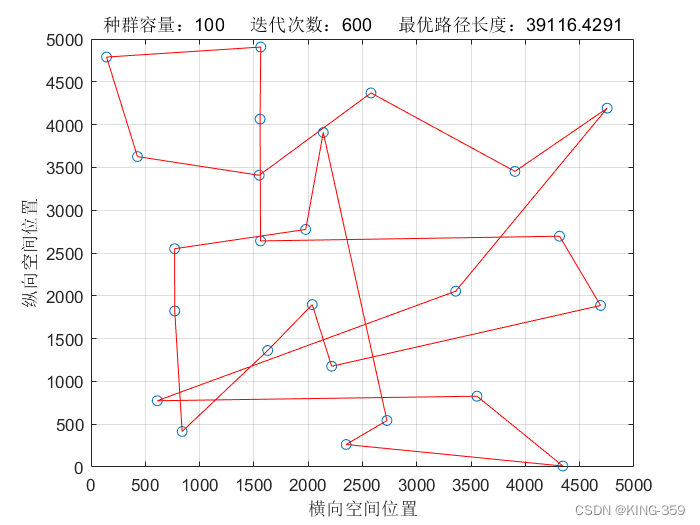
图1.8
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=800,变异概率 Pm=0.1时,实验结果如下图所示:
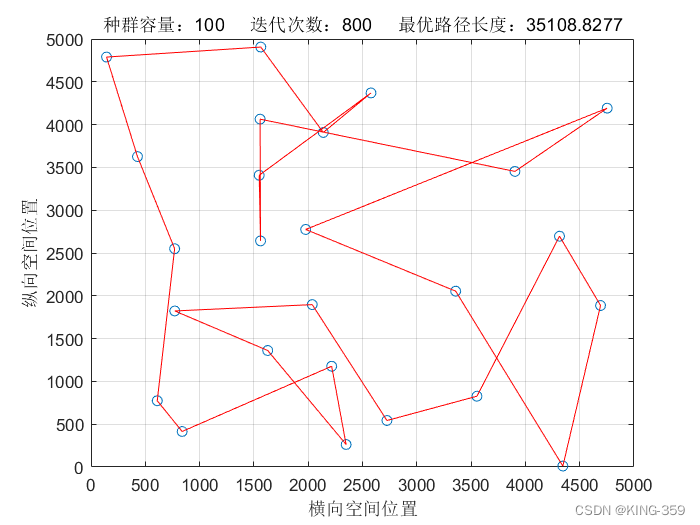
图1.9
种群数量 P=100,染色体基因数 N=25,迭代次数 maxIter=1000,变异概率 Pm=0.1时,实验结果如下图所示:
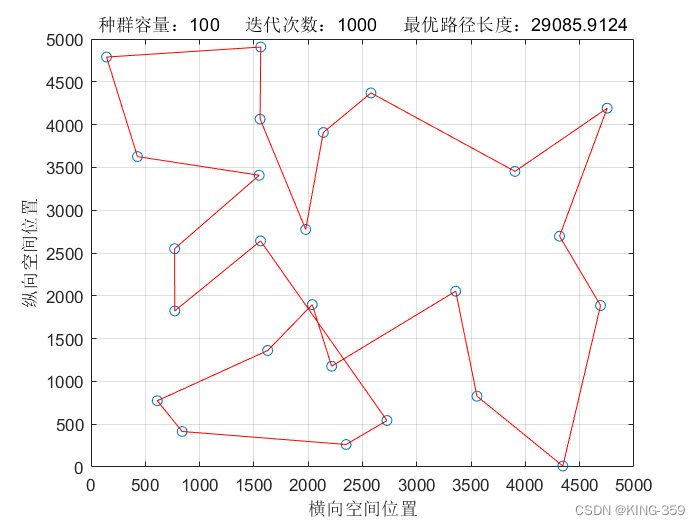
图1.10
| 种群数量P | 染色体基因数N | 迭代次数maxIter | 变异概率Pm | 最终结果 |
| 20 | 25 | 1000 | 0.1 | 45916.92 |
| 40 | 25 | 1000 | 0.1 | 39688.31 |
| 60 | 25 | 1000 | 0.1 | 35205.26 |
| 80 | 25 | 1000 | 0.1 | 35489.92 |
| 100 | 25 | 1000 | 0.1 | 29138.65 |
| 100 | 25 | 200 | 0.1 | 42388.17 |
| 100 | 25 | 400 | 0.1 | 41718.27 |
| 100 | 25 | 600 | 0.1 | 39116.43 |
| 100 | 25 | 800 | 0.1 | 35108.83 |
| 100 | 25 | 1000 | 0.1 | 29085.91 |
表1
从表1中不同参数下得到的结果可以看出:针对25个城市的TSP问题,遗传算法求解得出的最短路径值为29085.91,最优路径为24→15→25→20→19→6→8→17→3→13→7→5→11→1→2→14→4→9→12→21→10→16→22→18→23→24(数字为城市序号)。
同时,观察不同参数下得到的结果可以发现,随着种群数量的增长,遗传算法寻优的结果也越来越好;随着迭代次数的越来越多,遗传算法寻优的结果越来越好。当然,由于遗传算法本身具有一定的随机性,能否快速收敛得看具体参数设定。有时候随着种群数量和迭代次数增加,遗传算法寻优的结果可能还不如之前得到结果。
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手