
mtail是谷歌开源的一款从应用日志提取 metrics 的工具,它会实时读取应用程序的日志,然后通过自己编写的脚本分析日志,最终生成时间序列的指标,项目地址是:https://github.com/google/mtail。
夜莺的Categraf对日志指标的收集也是采用的 mtail,不过做了一些优化,具体优化了什么我们慢慢道来。
现在,我们先从谷歌的mtail开始聊起,再慢慢聊到夜莺的 mtail 插件。
前面已经对mtail做了简短的介绍,其实那就是全部。
所以,我们直接从安装开始。
从https://github.com/google/mtail/releases下载需要的版本,操作如下:
# 下载
$ wget https://github.com/google/mtail/releases/download/v3.0.0-rc51/mtail_3.0.0-rc51_Linux_x86_64.tar.gz
$ tar xf mtail_3.0.0-rc51_Linux_x86_64.tar.gz
$ cp mtail /usr/local/bin
# 查看mtail版本
$ mtail --version
mtail version 3.0.0-rc51 git revision 6fdbf8ec96a63c674c53148eeb9ec96043a2ec9c go version go1.19.4 go arch amd64 go os linux
# mtail后台启动
$ nohup mtail -port 3903 -logtostderr -progs test.mtail -logs test.log &
# 默认端口是3903
$ nohup ./mtail -progs test.mtail -logs test.log &
# 查看是否启动成功
$ ps -ef | grep mtail
# 查看mtail的帮助文档
$ mtail -h安装完mtail之后,如果对mtail的参数一无所知的话,也就不知道如何下手了,本小节就带大家来了解一下 mtail 有哪些参数。
我们可以通过mtail -h来查看mtail支持的参数列表,下面我对这些参数加一些中文注释,应该能够帮助你了解它们的意思了。
$ mtail -h
mtail version 3.0.0-rc51 git revision 6fdbf8ec96a63c674c53148eeb9ec96043a2ec9c go version go1.19.4 go arch amd64 go os linux
Usage:
-address string # 绑定HTTP监听器的主机或者IP地址
-alsologtostderr # 记录标准错误和文件
-block_profile_rate int # 报告goroutine阻塞事件之前的阻塞时间的纳秒数。0表示关闭。
-collectd_prefix string # 发送给collectd的指标前缀
-collectd_socketpath string # collectd socket路径,用于向其写入metrics
-compile_only # 仅禅师编译mtail脚本程序,不执行
-disable_fsnotify # 是否禁用文件动态发现机制。为true时,不会监听动态加载发现的新文件,只会监听程序启动时的文件。
-dump_ast # 解析后dump程序的AST(默认到/tmp/mtail.INFO)
-dump_ast_types # 在类型检查之后dump带有类型注释的程序的AST(默认到/tmp/mtail.INFO)
-dump_bytecode # dump程序字节码
-emit_metric_timestamp # 发出metric的记录时间戳。如果禁用(默认设置),则不会向收集器发送显式时间戳。
-emit_prog_label # 在导出的变量里面展示prog对应的标签。默认为true
-expired_metrics_gc_interval duration # metric的垃圾收集器运行间隔(默认为1h0m0s)
-graphite_host_port string # graphite carbon服务器地址,格式Host:port。用于向graphite carbon服务器写入metrics
-graphite_prefix string # 发送给graphite指标的metrics前缀
-http_debugging_endpoint # 是否开启调式接口(/debug/*),默认开启
-http_info_endpoint # 是否开始info接口(/progz,/varz),默认开启
-ignore_filename_regex_pattern string # 需要忽略的日志文件名字,支持正则表达式。使用场景:当-logs参数指定的为一个目录时,可以使用ignore_filename_regex_pattern 参数来忽略一部分文件
-jaeger_endpoint string # 如果设为true,可以将跟踪导出到Jaeger跟踪收集器。使用–jaeger_endpoint标志指定Jaeger端点URL
-log_backtrace_at value # 当日志记录命中设置的行N时,发出堆栈跟踪
-log_dir string # mtail程序的日志文件的目录,与logtostderr作用类似,如果同时配置了logtostderr参数,则log_dir参数无效
-logs value # 监控的日志文件列表,可以使用,分隔多个文件,也可以多次使用-logs参数,也可以指定一个文件目录,支持通配符*,指定文件目录时需要对目录使用单引号。
-logtostderr # 直接输出标准错误信息,编译问题也直接输出
-max_recursion_depth int # 以解析的标记来衡量mtail语句的最大长度。过长的mtail表达式可能会导致编译和运行时的性能问题。(默认为100)
-max_regexp_length int # 一个mtail regexp表达式的最大长度。过长的模式可能会导致编译和运行时的性能问题。(默认为1024)
-metric_push_interval duration # metric推送时间间隔,单位:秒,默认60秒
-metric_push_interval_seconds int # 弃用,用--metric_push_interval代替
-metric_push_write_deadline duration # 在出现错误退出之前等待推送成功的时间。(默认10s)
-mtailDebug int # 设置解析器debug级别
-mutex_profile_fraction int # 报告的互斥争夺事件的比例。 0将关闭
-one_shot # 此参数将编译并运行mtail程序,然后从指定的文件开头开始读取日志(从头开始读取日志,不是实时tail),然后将收集的所有metrics打印到日志中。此参数用于验证mtail程序是否有预期输出,不用于生产环境。
-one_shot_format string # 与-one_shot一起使用的格式。这只是一个调试标志,不适合生产使用。支持的格式: json, prometheus. (默认为 "json")
-override_timezone string # 设置时区,如果使用此参数,将在时间戳转换中使用指定的时区来替代UTC
-poll_interval duration # 设置轮询所有日志文件以获取数据的间隔;必须为正,如果为零将禁用轮询。使用轮询模式,将仅轮询在mtail启动时找到的文件
-poll_log_interval duration # 设置找到所有匹配的日志文件进行轮询的时间间隔;必须是正数,或者是0来禁用轮询。 在轮询模式下,只有在mtail启动时发现的文件会被轮询。(默认250ms)
-port string # 监听的http端口,默认3903
-progs string # mtail脚本程序所在路径
-stale_log_gc_interval duration # stale的垃圾收集器运行间隔(默认为1h0m0s)
-statsd_hostport string # statsd地址,格式Host:port。用于向statsd写入metrics
-statsd_prefix string # 发送给statsd指标的metrics前缀
-stderrthreshold value # 严重性级别达到阈值以上的日志信息除了写入日志文件以外,还要输出到stderr。各严重性级别对应的数值:INFO—0,WARNING—1,ERROR—2,FATAL—3,默认值为2.
-syslog_use_current_year # 如果时间戳没有年份,则用当前年替代。(默认为true)
-trace_sample_period int # 用于设置跟踪的采样频率和发送到收集器的频率。将其设置为100,则100条收集一条追踪。
-unix_socket string # socket监控地址
-v value # v日志的日志级别,该设置可能被 vmodule标志给覆盖.默认为0.
-version # 打印mtail版本
-vm_logs_runtime_errors # 启用运行时错误的记录到标准日志。 如果设置为false,则只将错误打印到HTTP控制台。(默认为true)
-vmodule value # 按文件或模块来设置日志级别,如:-vmodule=mapreduce=2,file=1,gfs*=3配置参数非常多,一般情况下我们使用的也就那几个,如下:
nohup ./mtail -progs test.mtail -logs test.log &指定 mtail 脚本以及日志目录即可。
在https://github.com/google/mtail/blob/main/docs/Programming-Guide.md处对脚本语法有相应的介绍,这里做一个简单的介绍。
脚本标准的格式如下:
COND {
ACTION
}其中COND是一个条件表达式,可以是正则表达式,也可以是 boolean 类型的条件语句,如下:
/foo/ {
ACTION1
}
variable > 0{
ACTION2
}
/foo/ && variable > 0{
ACTION3
}COND表达式可用的运算符如下:
另外,ACTION是具体的操作,如下表示从日志中匹配到 foo 字段,就给相应的指标 foo_total 的值就加 1:
counter foo_total
/foo/ {
foo_total++
}对于指标,可以用= , += , ++ , –等运算符进行操作。
mtail的目的是从日志中提取信息并将其传递到监控系统。因此,必须导出指标变量并命名,命名可以使用counter、histogram、gauge指标类型,并且命名的变量必须在COND脚本之前。
我们知道,拿 Prometheus 来说,除了上面的三种指标类型之外还有一个Summary的指标类型,为什么 mtail 没有呢?
因为在 Prometheus 中,summary 指标类型用于记录数据的分布情况,并计算出更多的统计信息,例如平均值、中位数、标准差等。但是,由于 mtail 是从日志文件中提取指标,而不是直接从应用程序中提取指标,因此没有必要使用 summary 指标类型。
对于在一个脚本中需要重复使用的表达式,可以将其定义为一个变量,后续可以直接使用变量。
counter duplicate_lease
const IP /\d+(\.\d+){3}/
const MATCH_IP /(?P<ip>/ + IP + /)/
/uid lease / + MATCH_IP + / for client .* is duplicate on / {
duplicate_lease++
}这是开发中常用的手段。
mtail 会为每一个日志事件都赋予一个时间戳,如果日志里没有时间戳,mtail 会为本次日志事件赋予一个当前的日志时间。
除此之外,如果日志里的时间戳不是标准时间或者其他情况,可以使用 strptime 对其进行解析,如下:
/^/ +
/(?P<date>\d{4}\/\d{2}\/\d{2} \d{2}:\d{2}:\d{2}) / +
/.*/ +
/$/ {
strptime($date, "2006/01/02 15:04:05")
}/pattern/ { action }是 mtail 程序中正常的条件控制流结构。
如果模式匹配,那么该块中的动作就会被执行。如果模式不匹配,则跳过该块。
else关键字允许程序在模式不匹配的情况下执行动作。
/pattern/ {
action
} else {
alternative
}除此之外,还可以使用 otherwise 来处理没有匹配到的规则,如下:
{
/pattern1/ { _action1_ }
/pattern2/ { _action2_ }
otherwise { _action3_ }
}这种语法类似于switch case default语法。
上面的/pattern/ { _action_ }形式隐含地匹配了当前的输入日志行。
如果想与另一个字符串变量匹配,可以使用=~操作符,或者用!~来否定匹配,像这样:
$1 =~ /GET/ {
...
}有时候遇到的日志里输出的数字是字符串,而非数字,mtail 可以对其进行解析,如下:
counter total
/^[a-z]+ ((?P<response_size>\d+)|-)$/ {
$1 != "-" {
total = $response_size
}
}一些日志包含除了包含数字,还包含分隔符,我们可以用 subst 函数删除它们:
/sent (?P<sent>[\d,]+) bytes received (?P<received>[\d,]+) bytes/ {
# Sum total bytes across all sessions for this process
bytes_total["sent"] += int(subst(",", "", $sent))
bytes_total["received"] += int(subst(",", "", $received))
}如果你想过滤一些不必要的日志被mtail采集,你可以使用stop,如下:
getfilename() !~ /apache.access.?log/ {
stop
}一些日志,如网络服务器日志,描述了一些常见的元素,其中有独特的标识符,如果不加处理,会导致大量的度量衡键,而没有有用的计数。要重写这些捕获组,可以使用 subst(),将模式作为第一个参数:
hidden text route
counter http_requests_total by method, route
/(?P<method\S+) (?P<url>\S+)/ {
route = subst(/\/d+/, "/:num", $url)
http_requests_total[method][route]++
}这里我们把$url中/后面的任何数字部分替换为字面字符串/:num,所以我们最终只计算 URL 路由的静态部分。
说一千,道一万,不如真正来一遍。
当然,我这里也不会把上面说的都来一次。
为了方便阐述,我把本次操作的脚本都放到~/Desktop/mtail目录中。
# 创建prog1,里面用于保存日志处理的规则脚本
$ mkdir prog1
# 在prog1里创建prog1.mtail文件并写入以下内容
$ cat prog1.mtail
counter foo_count
/foo/{
foo_count++
}
# 创建log1目录
$ mkdir log1
# 在log1中创建a.log文件
¥ touch a.log
# 启动mtail
$ mtail -progs ~/Desktop/mtail/prog1 -logs ~/Desktop/mtail/log1/a.log
# 向a.log中写入foo
$ echo "foo" > ~/Desktop/mtail/log1/a.log
# 查看指标明细
$ curl 127.0.0.1:3903/metrics
# HELP foo_count defined at prog1.mtail:1:9-17
# TYPE foo_count counter
foo_count{prog="prog1.mtail"} 1 # 可以看到foo_count指标数为1了如果多日志在同一个文件夹里,这时候采集的指标就可能混淆。
# 在log1目录中创建b.log
$ touch b.log
# 然后为b.log重新创建一个指标脚本
$ cat prog1/prog2.mtail
counter bar_count
/bar/{
bar_count++
}
# 启动mtail
$ mtail -progs ~/Desktop/mtail/prog1 -logs ~/Desktop/mtail/log1/a.log -logs ~/Desktop/mtail/log1/b.log
# 向b.log写入日志
$ echo "bar" >> ~/Desktop/mtail/log1/b.log
# 查看指标
$ curl 127.0.0.1:3903/metrics
# HELP bar_count defined at prog2.mtail:1:9-17
# TYPE bar_count counter
bar_count{prog="prog2.mtail"} 2
# HELP foo_count defined at prog1.mtail:1:9-17
# TYPE foo_count counter
foo_count{prog="prog1.mtail"} 0可以看到能正常收集指标,但是如果我们向 a.log 也写入 bar 日志,指标会增加吗?
# 向a.log写入日志
$ echo "bar" >> ~/Desktop/mtail/log1/a.log
# 查看指标
$ curl 127.0.0.1:3903/metrics
# HELP bar_count defined at prog2.mtail:1:9-17
# TYPE bar_count counter
bar_count{prog="prog2.mtail"} 3
# HELP foo_count defined at prog1.mtail:1:9-17
# TYPE foo_count counter
foo_count{prog="prog1.mtail"} 0可以看到指标依然会增加。其实我们的期望是prog1.mtail只收集a.log的日志指标,prog2.mtail只收集b.log的指标,不要相互影响。
如果要解决这个问题,就需要启动不同的mtail才行。换句话说有多少日志文件,如果想分开收集,则要启动多少个mtail,可以想想这是一个非常恐怖的事情。
鉴于此,Categraf 对 mtail 插件做了一些优化,优化后的 mtail 插件可以做到一个 Categraf 进程同时解析多个服务的日志,改造后的示例图如下:
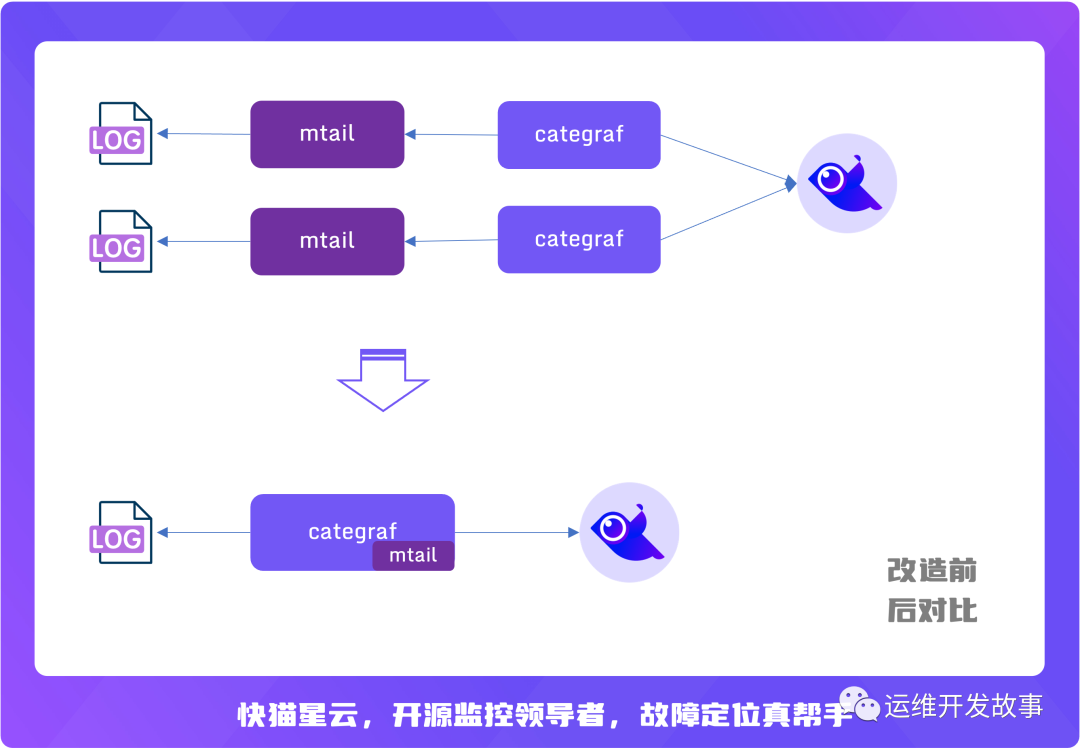
在前面的夜莺监控系列中,对 Categraf 基本都有一个印象。默认情况下它的配置都在 conf 目录下,其中插件都在以 input 开头的文件夹里。
我们进入input.mtail文件夹,编辑mtail.toml并增加如下配置:
[[instances]]
progs = "/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/prog1"
logs = ["/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/log1/a.log"]
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" #string type
[[instances]]
progs = "/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/prog2"
logs = ["/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/log1/b.log"]
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" # string type然后添加需要的目录以及脚本:
# 创建文件夹
$ mkdir {prog1,prog2,log1}
# 增加规则文件
$ cat prog1/a.mtail
counter foo_count
/foo/ {
foo_count++
}
$ cat prog2/b.mtail
counter bar_count
/bar/ {
bar_count++
}
# 增加日志文件
$ touch {log1/a.log,log1/b.log}启动 categraf:
# 使用测试模式启动
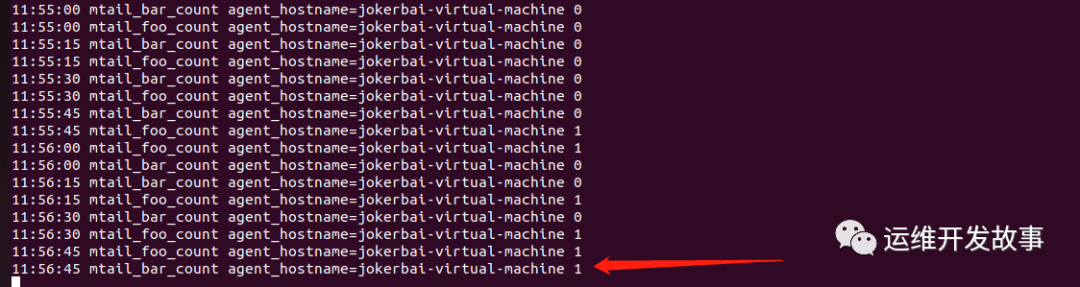
$ ./categraf -test -inputs mtail然后往a.log写入foo日志。
echo "foo" >> log1/a.log然后看到指标增加了:

再往b.log写入bar日志。
echo "bar" >> log1/b.logbar_count的指标也相应增加了。
那如果我们向a.log增加bar的日志,bar_count会增加么?我们来测试一下:
echo "bar" >> log1/a.log通过观察bar_count指标不会增加。
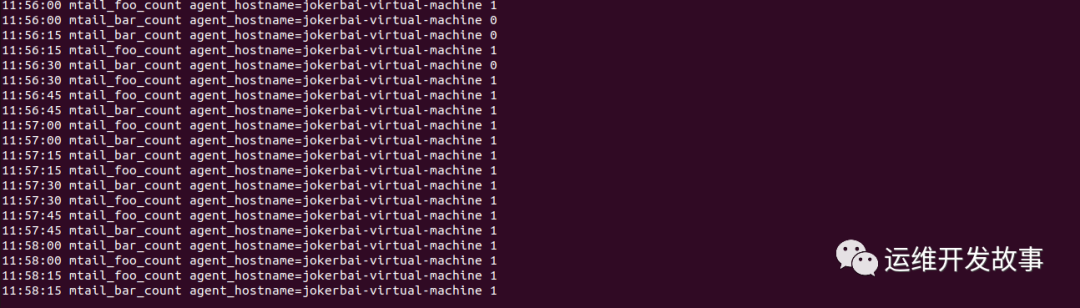
Categraf 就完美解决了不同日志指标错乱的问题。
除了正常的处理指标,如果想给不同的instance指定label,也是可以的,如下:
[[instances]]
progs = "/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/prog1"
logs = ["/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/log1/a.log"]
labels = {"app"= "foo"}
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" #string type
[[instances]]
progs = "/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/prog2"
logs = ["/home/jokerbai/Desktop/categraf-v0.2.38-linux-amd64/conf/input.mtail/log1/b.log"]
labels = {"app"= "bar"}
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" # string type重启 Categraf 就可以看到指标多了一个 label。

其他的脚本语法和原生的 mtail 一致,这里不再追溯了。
相比于谷歌的mtail,categraf对mtail做了一些优化,可以更好的处理多日志的问题。而且 categraf 本身集成了很多插件,都可以统一使用它实现。
另外,还是相同的问题,假设插件开启比较多,categraf 的具体性能如何以及会不会影响主机的整体性能,这还有待研究。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我有一个.pfx格式的证书,我需要使用ruby提取公共(public)、私有(private)和CA证书。使用shell我可以这样做:#ExtractPublicKey(askforpassword)opensslpkcs12-infile.pfx-outfile_public.pem-clcerts-nokeys#ExtractCertificateAuthorityKey(askforpassword)opensslpkcs12-infile.pfx-outfile_ca.pem-cacerts-nokeys#ExtractPrivateKey(askforpassword)o
我正在尝试提取方括号内的内容。到目前为止,我一直在使用它,它有效,但我想知道我是否可以直接在正则表达式中使用某些东西,而不是使用这个删除功能。a="Thisissuchagreatday[coolawesome]"a[/\[.*?\]/].delete('[]')#=>"coolawesome" 最佳答案 差不多。a="Thisissuchagreatday[coolawesome]"a[/\[(.*?)\]/,1]#=>"coolawesome"a[/(?"coolawesome"第一个依赖于提取组而不是完全匹配;第二个利用前瞻和
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
如何获取外部命令的输出并从中提取值?我有这样的东西:stdin,stdout,stderr,wait_thr=Open3.popen3("#{path}/foobar",configfile)if/exit0/=~wait_thr.value.to_srunlog.puts("Foobarexitednormally.\n")puts"Testcompleted."someoutputvalue=stdout.read("TX.*\s+(\d+)\s+")puts"Outputvalue:"+someoutputvalueend我没有在标准输出上使用正确的方法,因为Ruby告诉我它不能
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.