文章目录
将12个CSV文件中的数据,共200多G,导入到ES中,要求性能好一些,速度越快越好。
此处我们不讨论需求的合理性,只对处理办法进行讨论。
- 单索引操作,数据量很大
- 数据含有位置数据,可能会涉及经纬度问题
- 需要注意导入性能与速度问题
为满足业务需求,该问题可以拆分为两个部分,一个是读取,如何快速读取csv格式文件数据,内存消耗要小,读取速度要快,更要稳定。另一个是写入,写入ES如何做到写入性能最大。
硬件条件:1台8C64G服务器,硬盘足够大(不过是机械的)
读写速度可达5000条每秒 其中读 10万条每秒 写 大约5000条每秒
横向对比
自己写:多线程非IO阻塞式文件流读取,速度达标,但实现麻烦
POI工具包: 性能不高,速度慢
easyexcel:最终方案,10万条一批,速度性能非常好
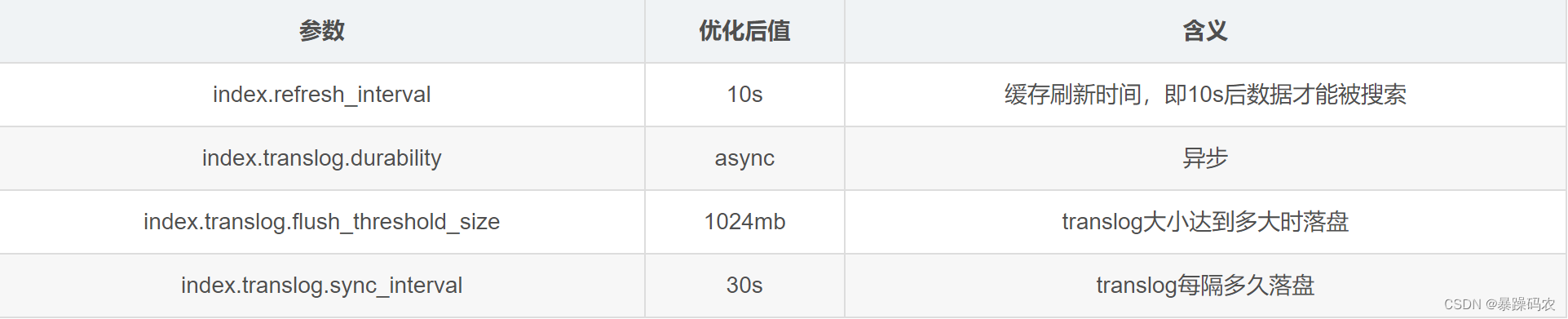
由于服务器操作受限,只能单机ES,针对ES写入性能优化,修改了如下参数
PS:es5以上就不能通过修改es的yml文件来配置了。
kibana示例:
PUT 索引名称/_settings
{
“index” : {
“refresh_interval” : “1m”,
“translog.durability” : “async”,
“translog.flush_threshold_size” : “1024mb”,
“translog.sync_interval” : “30s”
}
}
curl 命令curl -u elastic -XPUT -H "Content-Type: application/json" -d '{"index":{"refresh_interval" : "5m","translog.durability" : "async","translog.flush_threshold_size" : "1024mb","translog.sync_interval" : "30s"}}' localhost:9200/索引名/_settings优化前后差别不是很大,应该还是要上集群,需要注意的是,导入完成后记得将更新时间调整回去
在这个过程中,还遇到了以下问题
- CSV文件内容格式不正确导致抛映射错误异常,csv文件中的数据行不能出现双引号""
- 多表头导致类型不匹配异常
- 文件编码不是utf-8导致的中文乱码问题
近20G的CSV编辑工具选择就非常重要了,我用的EverEdit,虽然收费,但有一个月的免费使用,使用非常流畅,另存为可以修改文件编码格式,批量操作等功能也非常好用,推荐~!
可能这个方案还达不到你的业务需求标准,后面可以考虑ES集群写入效率会更高,如果可以,希望在评论区留下你的解决办法,可以让我学习一下。没有附源码的原因主要和编码没有什么太大的关系,主要是思路和工具的选用,选对了工具就可以了,代码都demo级的东西。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD