
由冯诺依曼体系结构可知,文件是储存在硬盘上的,硬盘和内存的区别:
在面试中这些是不考试的,但是在写很多代码的时候都和这个有关
文件也是被操作系统管理的,操作系统内核中有一个专门的模块,文件系统。Java 针对文件系统 / 文件进行了一系列封装。
此文主要涉及文件的元信息、路径的操作,暂时不涉及关于文件中内容的读写操作。
Java 中通过 java.io.File 类来对一个文件(包括目录)进行抽象的描述。注意,有 File 对象,并不代表真实存在该文件。
File 类中的常见属性、构造方法和方法
属性
| 修饰符及类型 | 属性(说明) |
|---|---|
| static String | pathSeparator(依赖于系统的路径分隔符,String 类型的表示) |
| static char | pathSeparator(依赖于系统的路径分隔符,char 类型的表示) |
构造方法
| 签名 | 说明 |
|---|---|
| File(File parent, Stringchild) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例 |
| File(String pathname) | 根据文件路径创建一个新的 File 实例,路径可以是绝对路径或者相对路径 |
| File(String parent, Stringchild) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例,父目录用路径表示 |
在计算机上如何访问到一个文件?有很多的目录(文件夹),很多的文件
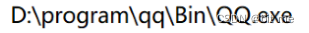
如上:目录和目录之间,使用 \ 分割,使用 / 也行,更推荐使用 /
优先使用绝对路径
方法
| 修饰符及返回值类型 | 方法签名–>说明 |
|---|---|
| String | getParent()–>返回 File 对象的父目录文件路径 |
| String | getName()–>返回 FIle 对象的纯文件名称 |
| String | getPath()–>返回 File 对象的文件路径 |
| String | getAbsolutePath()–>返回 File 对象的绝对路径 |
| String | getCanonicalPath()–>返回 File 对象的修饰过的绝对路径 |
| boolean | exists()–>判断 File 对象描述的文件是否真实存在 |
| boolean | isDirectory()–>判断 File 对象代表的文件是否是一个目录 |
| boolean | isFile()–>判断 File 对象代表的文件是否是一个普通文件 |
| boolean | createNewFile()–>根据 File 对象,自动创建一个空文件。成功创建后返回 true |
| boolean | delete()–>根据 File 对象,删除该文件。成功删除后返回 true |
| void | deleteOnExit()–>根据 File 对象,标注文件将被删除,删除动作会到 JVM 运行结束时才会进行 |
| String[] | list()–>返回 File 对象代表的目录下的所有文件名 |
| File[] | listFiles()–>返回 File 对象代表的目录下的所有文件,以 File 对象表示 |
| boolean | mkdir()–>创建 File 对象代表的目录 |
| boolean | mkdirs()–>创建 File 对象代表的目录,如果必要,会创建中间目录 |
| boolean | renameTo(Filedest)–>进行文件改名,也可以视为我们平时的剪切、粘贴操作 |
| boolean | canRead()–>判断用户是否对文件有可读权限 |
| boolean | canWrite()–>判断用户是否对文件有可写权限 |
方法演示1:
public static void main(String[] args) throws IOException {
//File file = new File("d:/test.txt");
File file = new File("./test.txt");
System.out.println(file.getParent());
System.out.println(file.getName());
System.out.println(file.getPath());
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalPath());
}
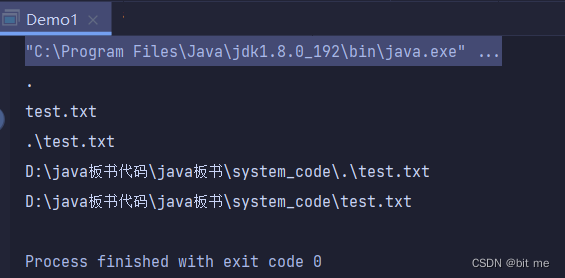
方法演示2:
public static void main(String[] args) throws IOException {
// 前面没写 ./ 也相当于是 ./ ./ 可以省略
File file = new File("helloworld.txt");
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println(file.isFile());
System.out.println("=============================");
//创建文件
file.createNewFile();
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println(file.isFile());
}
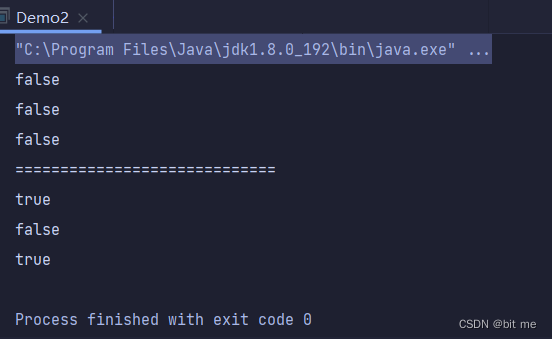
方法演示3:
public static void main(String[] args) throws InterruptedException, IOException {
//文件删除
File file = new File("helloworld.txt");
//file.delete();//立即删除
file.createNewFile();
//程序退出时才删除
file.deleteOnExit();
Thread.sleep(5000);
System.out.println(file.exists());
}
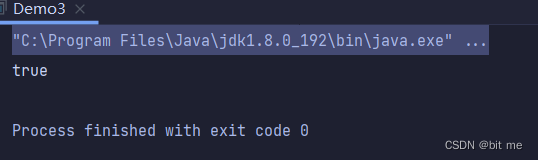
此处执行效果是需要看左边目录的,当 helloworld.txt 文件被创建好了之后,过五秒就会被删除。
这个方法主要是用来创建一些临时文件。
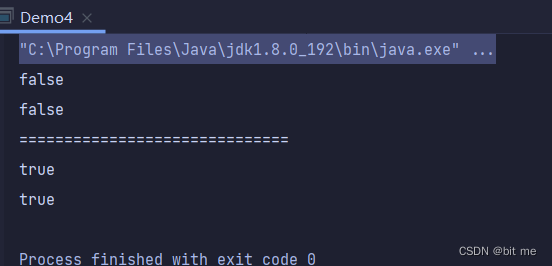
方法演示4:
//创建目录
public static void main(String[] args) {
File file = new File("test");
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println("==============================");
file.mkdir();
System.out.println(file.exists());
System.out.println(file.isDirectory());
}
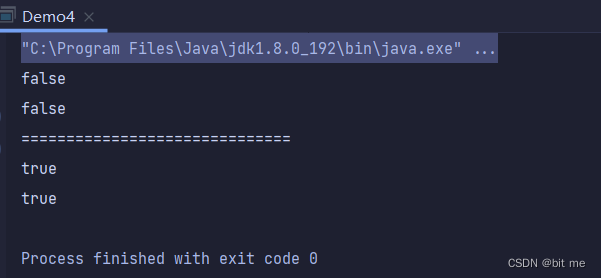
方法演示5:
//创建多级目录
public static void main(String[] args) {
File file = new File("test/aa/1");
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println("==============================");
file.mkdirs();
System.out.println(file.exists());
System.out.println(file.isDirectory());
}
方法演示6:
//文件重命名
public static void main(String[] args) {
File file1 = new File("./test1.txt");
File file2 = new File("./test2.txt");
file1.renameTo(file2);
}

转变为:

文件内容的操作:
3,4 是两个关键操作,在读写之前,务必要先打开;使用完毕之后,务必要及时关闭。
关于文件读写,在 Java 中提供了一些类
第一组:InputStream OutputStream,字节流(以字节为单位的流,用来操作二进制文件)
第二组:Reader Writer,字符流(以字符为单位的流,用来操作文本文件)
方法:
| 修饰符及返回值类型 | 方法签名 --> 说明 |
|---|---|
| int | read() --> 读取一个字节的数据,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) --> 最多读取 b.length 字节的数据到 b 中,返回实际读到的数量;-1 代表以及读完了 |
| int | read(byte[] b,int off, int len) --> 最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了 |
| void | close() --> 关闭字节流 |
InputStream 只是一个抽象类,要使用还需要具体的实现类。关于 InputStream 的实现类有很多,基本可以认为不同的输入设备都可以对应一个 InputStream 类,我们现在只关心从文件中读取,所以使用 FileInputStream
InputStream 不能直接实例化,需要使用到子类 FileInputStream 来读取文件的,构造方法,传入一个路径,用来打开文件。read 方法,可以读文件;close 方法,关闭文件。
InputStream inputStream = new FileInputStream("./test2.txt");
打开成功后,就得到了 inputStream 对象,后续对文件的操作,都是通过对 inputStream 进行操作的。

由于硬盘不方便直接操作,在内存里构造一个和他关联的对象,操作这个对象就相当于操作硬盘数据。类似于 “遥控器”,像 inputStream 这样的对象在计算机中又称为 “句柄”
关闭文件是为了释放资源?释放什么资源?内存?
不全是。一个进程里,会使用 PCB 来描述(只考虑单线程的进程),PCB 里就包含了很多属性,其中有个属性,就是文件描述符表,这个表是个数组(顺序表),每个元素,都对应着当前进程打开的文件,这个数组的下标,就称为 “文件描述符表”。
每次打开文件,都会在文件描述符表中占据一个位置;每次关闭文件,都会释放一个位置。
文件描述符表,是存在上限的。如果一个进程,一直在打开文件,没有释放,此时就会导致我们的进程在后续打开的时候,就打开文件失败。(虽然文件对象打开的时候会占用内存,但是内存占用的不多,相比于内存来说,文件描述符表是更稀缺的资源)
具体三个读取参照上面的表格
①:无参数读取
while (true){
int b = inputStream.read();
if(b == -1){
//文件读完了
break;
}
System.out.println(b);
}
此时我们在 test2.txt 文件中添加一个 hello 信息
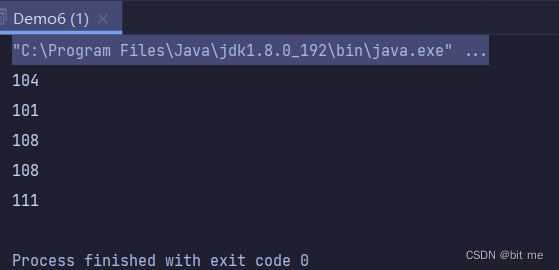
打印结果就是 hello 在 ASCII 码表中的值
②:一个参数读取
byte[] b = new byte[1024];
int len = inputStream.read(b);
System.out.println(len);
for (int i = 0; i < len; i++) {
System.out.println(b[i]);
}
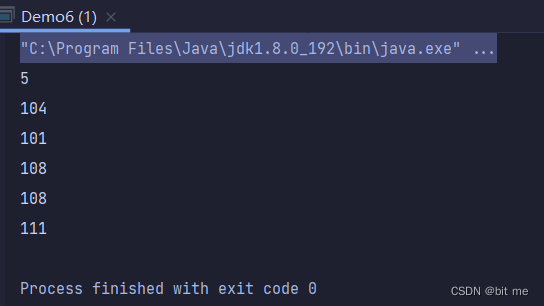
先打印的长度,再打印的 hello 在 ASCII 码表中的值。
当我们把英文 hello 换成 你好 的时候,运行结果如下,就是 UTF-8 字符集呈现的结果
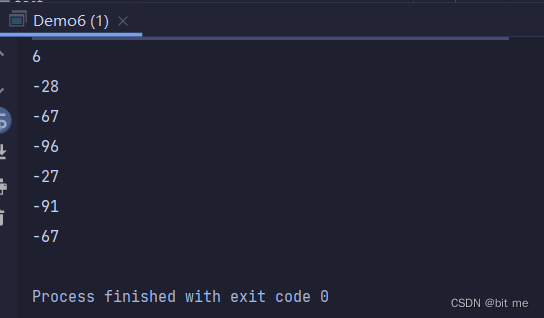
③:多个参数读取
我们也可以能把完整的中文读取出来,通过字节流,读取文本数据的时候,虽然能读取,但是想要正确还原成原始的文本,比较麻烦,需要手动处理。
byte[] b = new byte[1024];
int len = inputStream.read(b);
String s = new String(b,0,len,"utf8");
System.out.println(s);
因此就可通过字符流来解决上述问题:
方案一:
public static void main(String[] args) throws IOException {
Reader reader = new FileReader("test2.txt");
char[] buffer = new char[1024];
int len = reader.read(buffer);
for (int i = 0; i < len; i++) {
System.out.println(buffer[i]);
}
reader.close();
}
方案二 Scanner:(极力推荐)
public static void main(String[] args) throws IOException {
InputStream inputStream = new FileInputStream("test2.txt");
Scanner scanner = new Scanner(inputStream);
String s = scanner.next();
System.out.println(s);
inputStream.close();
}
通过上述对比我们可以看到方案二更加简便,
当我们读取文本文件的时候,使用方案二是再合适不过了;二进制文件就只能用 InputStream 一个字节一个字节的处理’
综上我们的代码就完成了:
public static void main(String[] args){
//使用一下 InputStream
InputStream inputStream = null;
try{
//1.打开文件
inputStream = new FileInputStream("./test2.txt");
//2.读取文件
//while (true){
// int b = inputStream.read();
// if(b == -1){
// //文件读完了
// break;
// }
// System.out.println(b);
//}
//
//byte[] b = new byte[1024];
//int len = inputStream.read(b);
//System.out.println(len);
//for (int i = 0; i < len; i++) {
// System.out.println(b[i]);
//}
byte[] b = new byte[1024];
int len = inputStream.read(b);
String s = new String(b,0,len,"utf8");
System.out.println(s);
}catch (IOException e){
e.printStackTrace();
}finally {
//3.关闭文件
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
但是这样的代码属实比较麻烦,可读性不好,于是又有了一种另外的写法:(极力推荐)
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("test2.txt")){
//读文件
byte[] b = new byte[1024];
int len = inputStream.read(b);
String s = new String(b,0,len,"utf8");
System.out.println(s);
}catch(IOException e){
e.printStackTrace();
}
}
这种方式会在 try 执行结束之后,自动调用 inputStream 的 close,但是要要求这个类实现 Closeable 接口,才能这样做。
方法
| 修饰符及返回值类型 | 方法签名(说明) |
|---|---|
| void | write(int b) (写入要给字节的数据) |
| void | write(byte[]b)(将 b 这个字符数组中的数据全部写入 os 中) |
| int | write(byte[] b, int off,int len) (将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个) |
| void | close() (关闭字节流) |
| void | flush() (重要:我们知道 I/O 的速度是很慢的,所以,大多的 OutputStream 为了减少设备操作的次数,在写数据的时候都会将数据先暂时写入内存的一个指定区域里,直到该区域满了或者其他指定条件时才真正将数据写入设备中,这个区域一般称为缓冲区。但造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中。) |
说明:
OutputStream 同样只是一个抽象类,要使用还需要具体的实现类。我们现在还是只关心写入文件中,所以使用 FileOutputStream
上面写文件的三种形式和上面的读差不多
关于写文件,在 Java 中提供了一些类
字节流:OutputStream / FileOutputStream
字符流:Writer / FileWriter
和 Scanner 相对的还可以使用 PrintWriter 来简化字符流的写入操作
三种 write 方式中,预期写的长度,和实际写的长度,是不一样的。byte[] b 中,b 的长度是 1024 ,预期要写 1024 个字节,但是实际不一定能写这么多,如硬盘空间不够,就写不了这么多,返回值就是实际写入的字节数。
写一个 hello ,此时就会把 test2 中的内容写成 hello
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("test2.txt")){
outputStream.write('h');
outputStream.write('e');
outputStream.write('l');
outputStream.write('l');
outputStream.write('o');
}catch (IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("test2.txt")){
String s = "hello Java";
outputStream.write(s.getBytes());
}catch (IOException e){
e.printStackTrace();
}
}
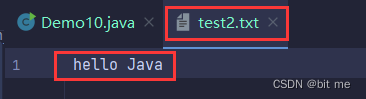
每次重新写的时候,都会把旧的文件内容清空掉,重新去写
还有另外一种写法
public static void main(String[] args) {
try(Writer writer = new FileWriter("test2.txt")){
writer.write("hello world");
}catch (IOException e){
e.printStackTrace();
}
}
使用 PrintWriter 来简化字符流的写入操作:
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("test2.txt")){
//此处 PrintWriter 就和 System.out 是一样的了
PrintWriter printWriter = new PrintWriter(outputStream);
printWriter.println("hello");
}catch (IOException e){
e.printStackTrace();
}
}
PrintWriter 在这里会把 hello 写到缓冲区中,并不会直接写到 test2 中。那啥时候缓冲区的数据会被刷新到硬盘中呢?
- 1. 缓冲区满了
- 2. 显示调用 flush(冲水操作)
文件查找如何遍历目录?“递归” 的把这里所有的文件(子目录中的文件)都能够访问到
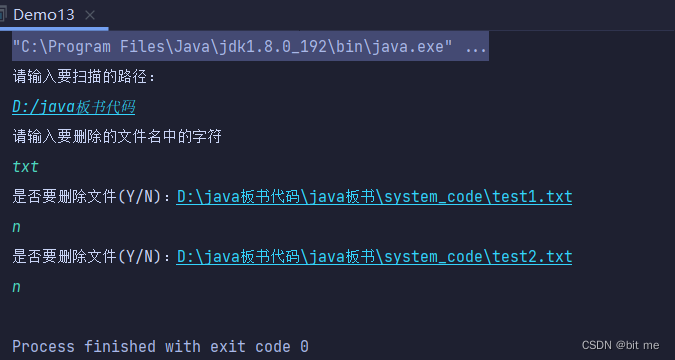
public class Demo13 {
//实现一个递归遍历文件,并询问删除
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要扫描的路径:");
String rootPath = scanner.next();
File root = new File(rootPath);
if(!root.exists()){
System.out.println("您输入的路径不存在,无法进行扫描!");
return;
}
System.out.println("请输入要删除的文件名中的字符");
String toDelete = scanner.next();
//准备进行递归,通过递归的方式,找到所有的文件
//找到所有的文件之后,再尝试进行删除
scanDir(root,toDelete);
}
public static void scanDir(File rootDir,String toDelete) throws IOException {
//加上个日志,看一下这里当前递归的过程
System.out.println(rootDir.getCanonicalPath());
File[] files = rootDir.listFiles();
if(files == null){
//空目录,直接返回
return;
}
for (File f : files){
if(f.isDirectory()){
//是目录,就进行递归
scanDir(f,toDelete);
}else {
//普通文件
tryDelete(f,toDelete);
}
}
}
public static void tryDelete(File f,String toDelete) throws IOException {
//看看当前文件名是否包含了 todelete,如果包含,就删除,否则就啥也不干
if(f.getName().contains(toDelete)){
System.out.println("是否要删除文件(Y/N):" + f.getCanonicalPath());
Scanner scanner = new Scanner(System.in);
String choice = scanner.next();
if (choice.equals("Y")){
f.delete();
}
}
}
}
(由于我个人目录下文件太多哈哈哈,这里就把打印日志省去了,以免可读性很差)
操作系统中的文件类型有很多种,最常见的,普通文件和目录文件
public class Demo15 {
//实现复制文件的功能
public static void main(String[] args) {
//准备工作
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要复制的文件路径:");
String srcPath = scanner.next();
File srcFile = new File(srcPath);
if(!srcFile.exists()){
System.out.println("要复制的文件不存在!");
return;
}
if(!srcFile.isFile()){
System.out.println("要复制的文件不存在!");
return;
}
System.out.println("请输入要复制到的目标路径:");
String destPath = scanner.next();
File destFile = new File(destPath);
if(destFile.exists()){
System.out.println("要复制到的目标已经存在!");
return;
}
//拷贝工作
try(InputStream inputStream = new FileInputStream(srcFile)){
try(OutputStream outputStream = new FileOutputStream(destFile)){
byte[] buf = new byte[1024];
while (true){
int len = inputStream.read(buf);
if(len == -1){
//拷贝完成
break;
}
outputStream.write(buf,0,len);
}
}
}catch (IOException e){
e.printStackTrace();
}
}
}
在 buf 进行 write 的时候,为什么不直接读而是从 0 到 len ?原因就是如果直接读 buf,读的就是整个字节的内容,就不一定是读出的内容。
注意:现在的方案性能较差,所以尽量不要在太复杂的目录下或者大文件下实验
public class Demo16 {
//遍历目录,看某个输入的词是否在文件名或者文件内容中存在
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的目录:");
String rootPath = scanner.next();
File rootFile = new File(rootPath);
if(!rootFile.exists()){
System.out.println("要扫描的目录不存在!");
return;
}
if(!rootFile.isDirectory()){
System.out.println("要扫描的路径不是目录!");
return;
}
System.out.println("请输入要搜索的词:");
String toFind = scanner.next();
//递归遍历目录
scanDir(rootFile,toFind);
}
public static void scanDir(File rootFile,String toFind) throws IOException {
File[] files = rootFile.listFiles();
if(files == null){
return;
}
for (File f : files){
if(f.isDirectory()){
scanDir(f,toFind);
}else {
tryFindInFile(f,toFind);
}
}
}
//判断 toFind 是否是文件名 或者 是文件内容的一部分
private static void tryFindInFile(File f,String toFind) throws IOException {
//是文件名的一部分
if(f.getName().contains(toFind)){
System.out.println("找到了文件名匹配的文件:" + f.getCanonicalPath());
return;
}
//是不是文件内容的一部分
try(InputStream inputStream = new FileInputStream(f)){
//把文件内容整个都读出来
StringBuilder stringBuilder = new StringBuilder();
Scanner scanner = new Scanner(inputStream);
while (scanner.hasNextLine()){
stringBuilder.append(scanner.nextInt());
}
//读取完毕了
if(stringBuilder.indexOf(toFind) >= 0){
System.out.println("找到文件内容匹配的文件:" + f.getCanonicalPath());
return;
}
}
}
}
由于读取文件的时候,会把文件整个内容都读取出来,所以只适合文件较小的时候读取,文件大了就不行了,代码会非常低效。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只