手持两把锟斤拷,口中直呼烫烫烫
在文章伊始,先来复习一下计算机中关于编码的一些基础知识,着重理清以下几个基本概念。
计算机只能以二进制的形式存储文字,故而计算机中每一个字母,文字,符号,emoji都对应着一个二进制数,而这个二进制数就是码点。
光有码点还不够,我们还得知道有哪些码点,这些码点又能表示哪些字符,于是便又到了喜闻乐见的制定标准环节。标准所支持的所有字符及其对应码点的集合被称为字符集。例如学过C语言的同学都知道的ASCII字符集,它共包含了128个字符,包括数字,26个字母的大小写及一些符号,对应的码点就是0-127。再有就是后面要提到的Unicode字符集。
以ASCII字符集为例,它的码点为0-127,最大不超过7bit,而计算机中一般是以8bit的字节(byte)为单位。出于种种考量,实际存储在计算机中的码点的二进制都会在头部添0,以8bit存储。例如A对应码点65,二进制为100 0001,实际在计算机中存储为0100 0001。这种在计算机中实际存储的内容到字符的映射就是编码。
我们熟悉的编码方式有ASCII,UTF-8,UTF-16,欧洲的ISO,中国大陆的GBK等等。计算机中存储的同一段二进制,用不同的编码方式,会得到完全不同的内容。
ASCII一共只包含了128个字符,显然不够用,于是便有了Unicode字符集。Unicode字符集中收录了世界上绝大多数文字,符号等,反正就是非常多。
行文至此,笔者想到自己当初学习时的一个疑惑,即字符集已经规定好了字符到码点的映射,为啥还有各种不同的编码方式。如果读者仔细理解了上文不难发现,在计算机中以何种方式存储码点是需要编码来确定。最简单的方法就是直接将码点转成二进制存储,比如对ASCII字符集的ASCII编码,对Unicode的UTF-32编码。
由于Unicode字符集数量极其旁大,单个字符最大已超过了3个字节(具体多大我也不清楚,目前用4个字节还足够表示),同时为了区分前后两个字符在哪里断开,utf-32编码简单粗暴得将每个字符以32位4字节的形式存储在计算机中。这样很好理解,但带来了严重的空间浪费,对于常用的字母得要存一堆0,简直就是0溢事件。
我们常见的utf-8便是为了解决上述问题而诞生的,他是针对于Unicode的可变长度编码方式,可以把不同字符以1,2,3,4字节大小存储到计算机中,同时utf-8兼容ascii,具体规则参考下图,也推荐大家看一下图片下方链接的视频,讲的很好:

图片来源:【你懂乱码吗?锟斤拷烫烫烫(详解ASCII、Unicode、UTF-32、UTF-8编码)】 https://www.bilibili.com/video/BV1xP4y1J7CS/?share_source=copy_web&vd_source=f5db843fce15b7c3e2990f4f7a6e8921
有了以上知识的铺垫,其实接下来的问题就很好解决了。
首先,java中采用的是基于Unicode字符集的UTF-16编码方式。utf-16可以将不同字符以2或4字节大小存储在计算机中,可能有同学已经发现规律了,utf-8是以8bit为最小单位,而utf-16是以16 bit为最小单位,而这个最小单位实际上就是所谓的代码单元(code unit)。
基本类型char类型就是一个16bit的代码单元。我们日常里常用的字符,如字母,汉字等只需要一个char,而对于一些类似于emoji这样的码点值很大的字符,需要两个char。
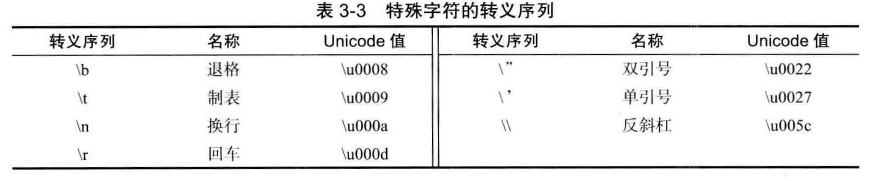
java中char类型的字面量用'A'单引号括起来,表示一个字符常量。对于一些特殊字符,如回车,换行,我们要用到转义字符来表示,如下图:
行文至此,笔者又想起之前曾经看到过的一个相关的案例。
简言之就是需要对数据库中取出的用户名做一个截断,比如某些情况下只需要呈现用户名的前三个字。而这个系统允许用户上传的用户名中包含emoji表情。
在这种情况下就要注意了,一个emoji字符由两个char组成,如果简单得用String.subString()或者String.length是有问题的,因为这些方法都是以char为单位,可能会造成把一个emoji字符只截了一个char出来,从而导致问题。在这里就需要用String的codePoint相关的方法去截取,以码点为单位,因为一个码点一定代表一个字符,而一个char则未必。
详情见该视频:【Emoji 表情导致线上故障2个小时。老板直接损失10万。到底是什么问题?| 故障复盘 | 实战经验分享】 https://www.bilibili.com/video/BV1MG41177pT/?share_source=copy_web
如果您坚持看到了这里,那么我想一定已经对于我标题提出的问题的答案了然于胸了。
char和byte的关系,现在看来这俩也没啥关系嘛,只能说我这个引申不是很合适。本文着重介绍了计算机字符编码的相关知识,同时也总结了java中有关字符编码的一些内容,希望能对你有所帮助。
鄙人只是一名在读的软件工程专业的本科生,正在复习找工作,故而将复习时遇到的一些有意思的东西总结出来,既是加深理解,也是便于日后复习。
鄙人才疏学浅,若文中有谬误之处,还望诸位不吝斧正,以免误人子弟。若有同道中人想一同讨论学习,也可以联系我=>2938189276@qq.com。未经本人同意,请勿转载!
路漫漫其修远兮,吾将上下而求索。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123