开发小伙伴都知道线上服务挂掉,基本都是因为cpu或者内存不足,出现GC频繁OOM之类的情况。本篇文章区别以上的情况给小伙伴们
带来不一样的服务挂掉。
还记得哔哩哔哩713事故中那场诡计多端的0吗?

对就是这个0,和本次事故没关系,但三省同学深受学习。
相关阅读:
2021.07.13 我们是这样崩的
线上服务假死解决
IDEA插件JProfiler安装使用
Tomcat10下载安装及各个线程作用详解
老规矩在集群环境中同一个服务几个节点无响应。如不及时解决会可能形成雪崩效应。
优先查看服务日志是否有报错,礼貌习惯性查看服务cpu及内存情况。先复习下,若服务无报错。cpu或内存出现异常,按如下步骤排查。
top -H -p pid
或
ps -mp pid -o THREAD,tid,time
printf “%x\n” nid
jstack pid | grep number
查看占用最大内存对象前一百
jmap -histo pid|head -100
导出到文件
jstack -l PID >> a.log
或dump信息使用工具Mat或JProfiler查看
jmap -dump:live,format=b,file=/dump.bin pid
经过上面一通手法操作,足以解决此类常规报错了,通常大多是原因各种循环递归、或数据库慢查询等。
在MAT中,会有两种大小表示:
Shallow Size:表示对象自身占用的内存大小,不包括它引用的对象。
Retained size:当前对象内存大小+当前对象直接或间接引用的对象大小,全部的总和,简单理解,就是当前对象被GC后,总共能释放的内存大小。
Histogram视图
以Class Name为维度,分别展示各个类的对象数量。它默认是以byte为单位的,
要显示让单位展示出来,点击Window->Preferences选择最后一项,点击Apply and Close
再重新打开Histogram视图,就会生效了。
Leak Suspects
报表很直观地展现了一个饼图,图中颜色深的部分表示可能存在内存泄漏的嫌疑。
通过这个指标可以快速定位内存泄漏地方出现在哪个类方法里的哪行代码。
因服务健康监测无响应,cpu及内存情况正常,直接查看堆栈信息,看看线程都在干什么
jstack -l PID >> a.log
Jstack的输出中,Java线程状态主要是以下几种:
RUNNABLE 线程运行中或I/O等待
BLOCKED 线程在等待monitor锁(synchronized关键字)
TIMED_WAITING 线程在等待唤醒,但设置了时限
WAITING 线程在无限等待唤醒
发现都是WAITING线程。
"http-nio-8888-exec-6666" #8833 daemon prio=5 os_prio=0 tid=0x00001f2f0016e100 nid=0x667d waiting on condition [0x00002f1de3c5200]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007156a29c8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at com.alibaba.druid.pool.DruidDataSource.takeLast(DruidDataSource.java:1897)
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1458)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1253)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4619)
at com.alibaba.druid.filter.stat.StatFilter.dataSource_getConnection(StatFilter.java:680)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4615)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1231)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1223)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:90)
at com.baomidou.dynamic.datasource.ds.ItemDataSource.getConnection(ItemDataSource.java:56)
at com.baomidou.dynamic.datasource.ds.AbstractRoutingDataSource.getConnection(AbstractRoutingDataSource.java:48)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:111)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:77)
at org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:82)
at org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:68)
at org.apache.ibatis.executor.BaseExecutor.getConnection(BaseExecutor.java:336)
at org.apache.ibatis.executor.SimpleExecutor.prepareStatement(SimpleExecutor.java:84)
at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:62)
at org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:324)
at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:156)
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:109)
at com.github.pagehelper.PageInterceptor.intercept(PageInterceptor.java:143)
at org.apache.ibatis.plugin.Plugin.invoke(Plugin.java:61)
at com.sun.proxy.$Proxy571.query(Unknown Source)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at com.alibaba.druid.pool.DruidDataSource.takeLast(DruidDataSource.java:1897)
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
while (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
if (failFast && isFailContinuous()) {
throw new DataSourceNotAvailableException(createError);
}
notEmptyWaitThreadCount++;
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
}
try {
// 数据库的连接都没有释放且被占用,连接池中无可用连接,导致请求被阻塞
notEmpty.await(); // signal by recycle or creator
} finally {
notEmptyWaitThreadCount--;
}
notEmptyWaitCount++;
if (!enable) {
connectErrorCountUpdater.incrementAndGet(this);
throw new DataSourceDisableException();
}
}
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
notEmptySignalCount++;
throw ie;
}
decrementPoolingCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
return last;
}
结合日志报错定位到问题代码。因报错可用连接没有正常释放,导致一直await卡死。
问题代码如下:
try {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
mapper.insetList(list);
sqlSession.flushStatements();
} catch (Exception e) {
e.printStackTrace();
}
按照以上信息在多活环境复现。因线程被打满且都在等待导致监控检查无响应。
tomcat线程被打满:
tomcat默认参数:
最大工作线程数,默认200。
server.tomcat.max-threads=200
最大连接数默认是10000
server.tomcat.max-connections=10000
等待队列长度,默认100。
server.tomcat.accept-count=100最小工作空闲线程数,默认10。
server.tomcat.min-spare-threads=100
Druid连接池的默认参数如下:
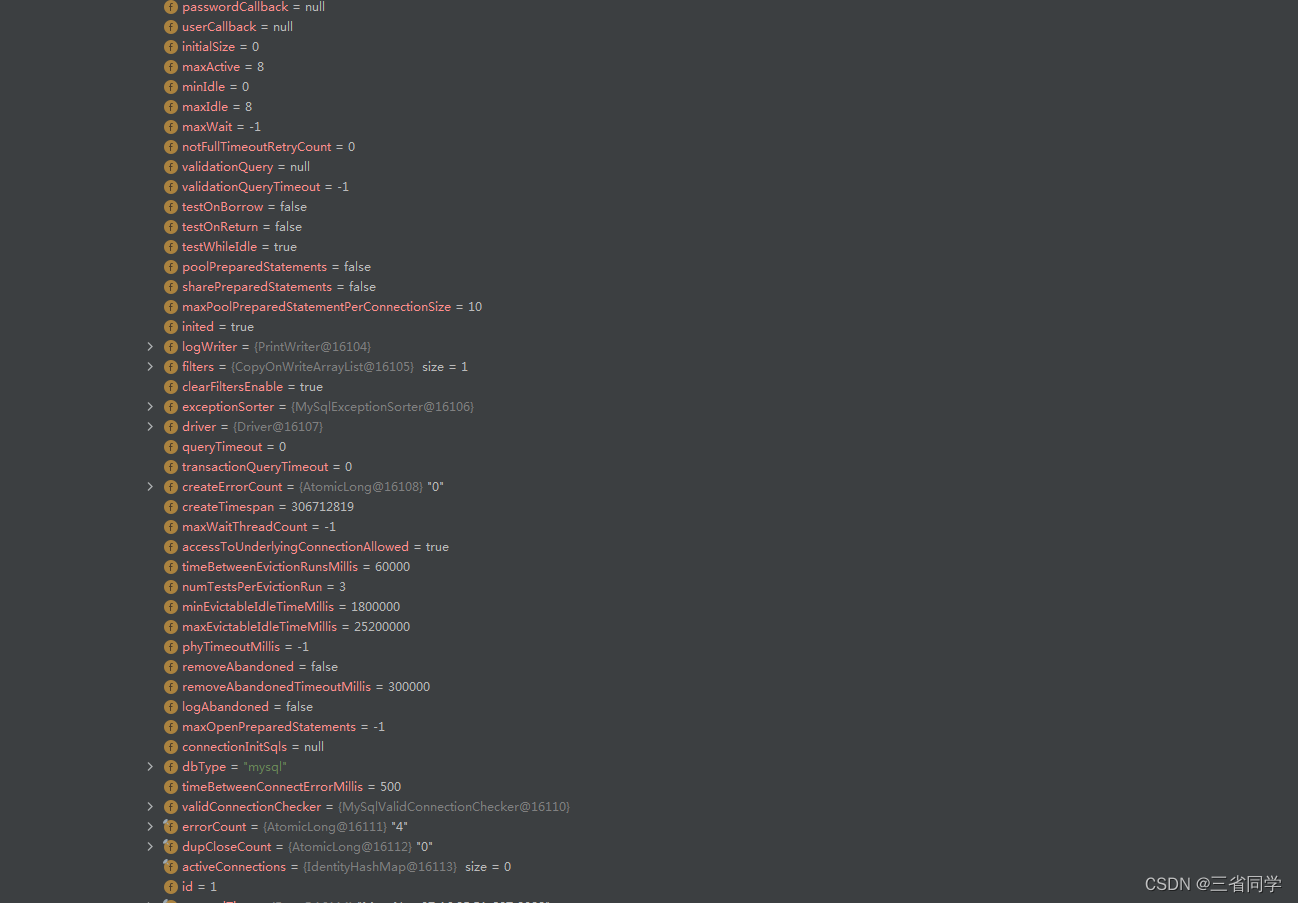
Druid连接池的配置参数如下:
| 属性 | 说明 | 建议值 |
|---|---|---|
| username | 登录数据库的用户名 | |
| password | 登录数据库的用户密码 | |
| initialSize | 默认0,启动程序时,在连接池中初始化多少个连接 | 10-50足够 |
| maxActive | 默认8,连接池中最多支持多少个活动会话 | |
| maxWait | 默认-1,程序向连接池中请求连接时,超过maxWait的值后,认为本次请求失败,即连接池, 没有可用连接,单位毫秒,设置-1时表示无限等待 | 100 |
| minEvictableIdleTimeMillis | 池中某个连接的空闲时长达到 N 毫秒后, 连接池在下次检查空闲连接时,将回收该连接,要小于防火墙超时设置 net.netfilter.nf_conntrack_tcp_timeout_established | 见说明部分 |
| timeBetweenEvictionRunsMillis | 检查空闲连接的频率,单位毫秒, 非正整数时表示不进行检查 | |
| keepAlive | 程序没有close连接且空闲时长超过 minEvictableIdleTimeMillis,则会执 行validationQuery指定的SQL,以保证该程序连接不会池kill掉,其范围不超过minIdle指定的连接个数 | true |
| minIdle | 默认8,回收空闲连接时,将保证至少有minIdle个连接. | 与initialSize相同 |
| removeAbandoned | 要求程序从池中get到连接后, N 秒后必须close,否则druid 会强制回收该连接,不管该连接中是活动还是空闲, 以防止进程不会进行close而霸占连接。 | false,当发现程序有未正常close连接时设置为true |
| removeAbandonedTimeout | 设置druid 强制回收连接的时限,当程序从池中get到连接开始算起,超过此 值后,druid将强制回收该连接,单位秒。 | 应大于业务运行最长时间 |
| logAbandoned | 当druid强制回收连接后,是否将stack trace 记录到日志中 | true |
| testWhileIdle | 当程序请求连接,池在分配连接时,是否先检查该连接是否有效。(高效) | true |
| validationQuery | 检查池中的连接是否仍可用的 SQL 语句,drui会连接到数据库执行该SQL, 如果 正常返回,则表示连接可用,否则表示连接不可用 | |
| testOnBorrow | 程序申请连接时,进行连接有效性检查(低效,影响性能) | false |
| testOnReturn | 程序返还连接时,进行连接有效性检查(低效,影响性能) | false |
| poolPreparedStatements | 缓存通过以下两个方法发起的SQL: public PreparedStatement prepareStatement(String sql) public PreparedStatement prepareStatement(String sql,int resultSetType, int resultSetConcurrency) | true |
| maxPoolPrepareStatementPerConnectionSize | 每个连接最多缓存多少个SQL | 20 |
| filters | 这里配置的是插件,常用的插件有:监控统计: filter:stat 日志监控: filter:log4j 或者 slf4j 防御SQL注入: filter:wall | stat,wall,slf4j |
| connectProperties | 连接属性。比如设置一些连接池统计方面的配置。 druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 比如设置一些数据库连接属性 |
spring:
redis:
host: localhost
port: 6379
password:
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
dynamic:
druid:
initial-size: 5
min-idle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,slf4j,wall
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
sqlSession.close();
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除