ChatGPT国内镜像站初体验,聊天、Python代码生成。
Python 官网:https://www.python.org/
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚

本文质量分:
CSDN质量分查询入口:http://www.csdn.net/qc

最近ChatGPT传得沸沸扬扬,红得发紫。由于主站在国外,我没有资源和途径,无缘窥其尊容。最近有缘得到国内站点,趁着情人节的无所事事,来撩一把ChatGPT的国内镜像站点。
ChatGPT is a natural language processing (NLP) chatbot that uses a generative pre-trained transformer (GPT) model to generate responses to user input. It is designed to provide a conversational experience that is as close to human-like as possible. ChatGPT is trained on a large corpus of conversational data and is able to generate responses that are both relevant and appropriate to the user’s input. ChatGPT can be used in a variety of applications, including customer service, virtual assistants, and more.
译文
ChatGPT是一种自然语言处理(NLP)聊天机器人,它使用生成式的预训练转换器(GPT)模型来生成对用户输入的响应。它的设计目的是提供一种尽可能接近类人的对话体验。ChatGPT是在大量的会话数据语料库上进行训练的,并且能够生成与用户的输入既相关又合适的响应。ChatGPT可以用于各种应用程序中,包括客户服务、虚拟助理等。
ChatGPT目前会使用Python,JavaScript,HTML和CSS等编程语言。后续如有需要,还会学习其他语言。
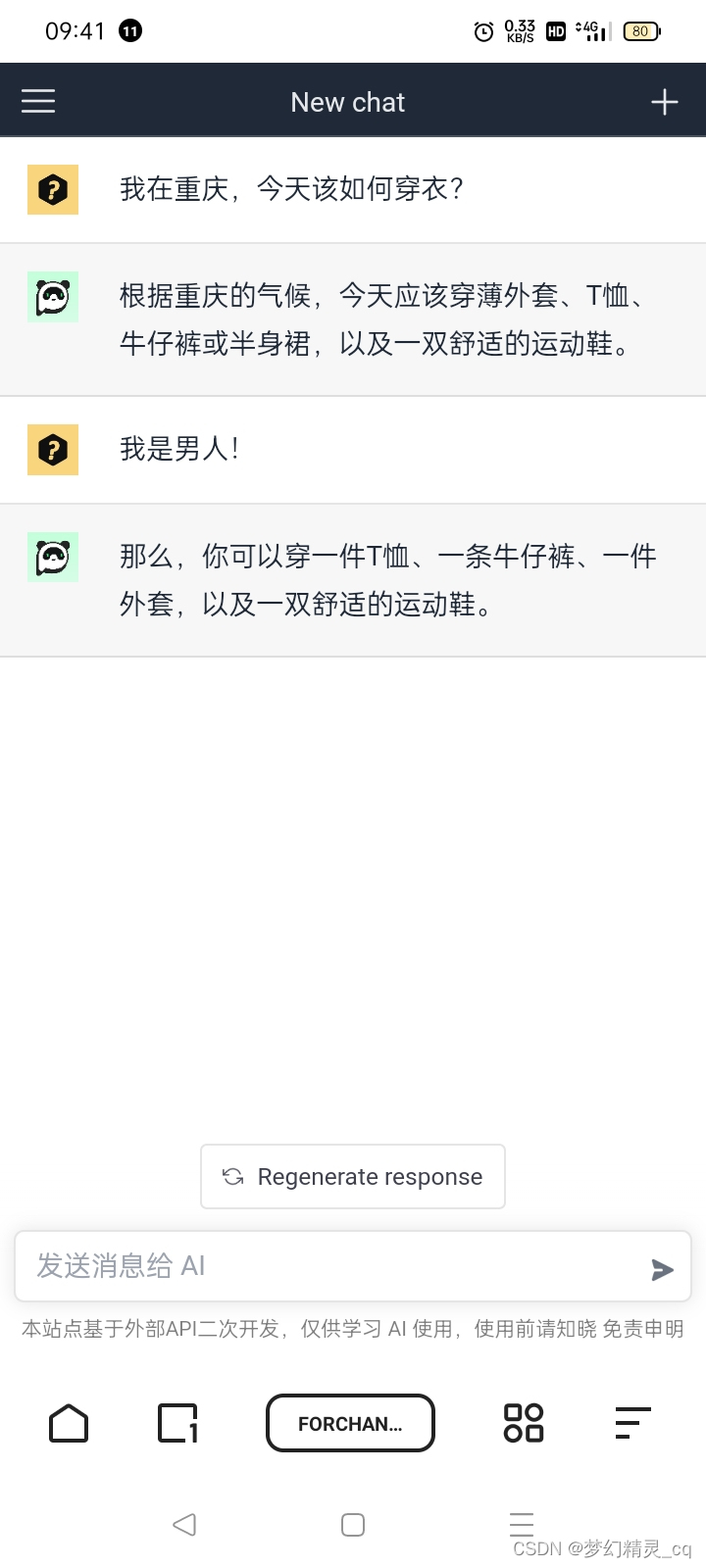
今日发现,ChatGPT国内某镜像站点,网页版、微信公众号版,AI对话头像已同步更换为“熊猫🐼头”,详见截屏图片(2023-02-16)。
网页版聊天对话界面
微信公众号版聊天对话界面

趁这没有情人的情人节,与ChatGPT 唠唠“情人节”😋……
与ChatGPT聊天截屏图
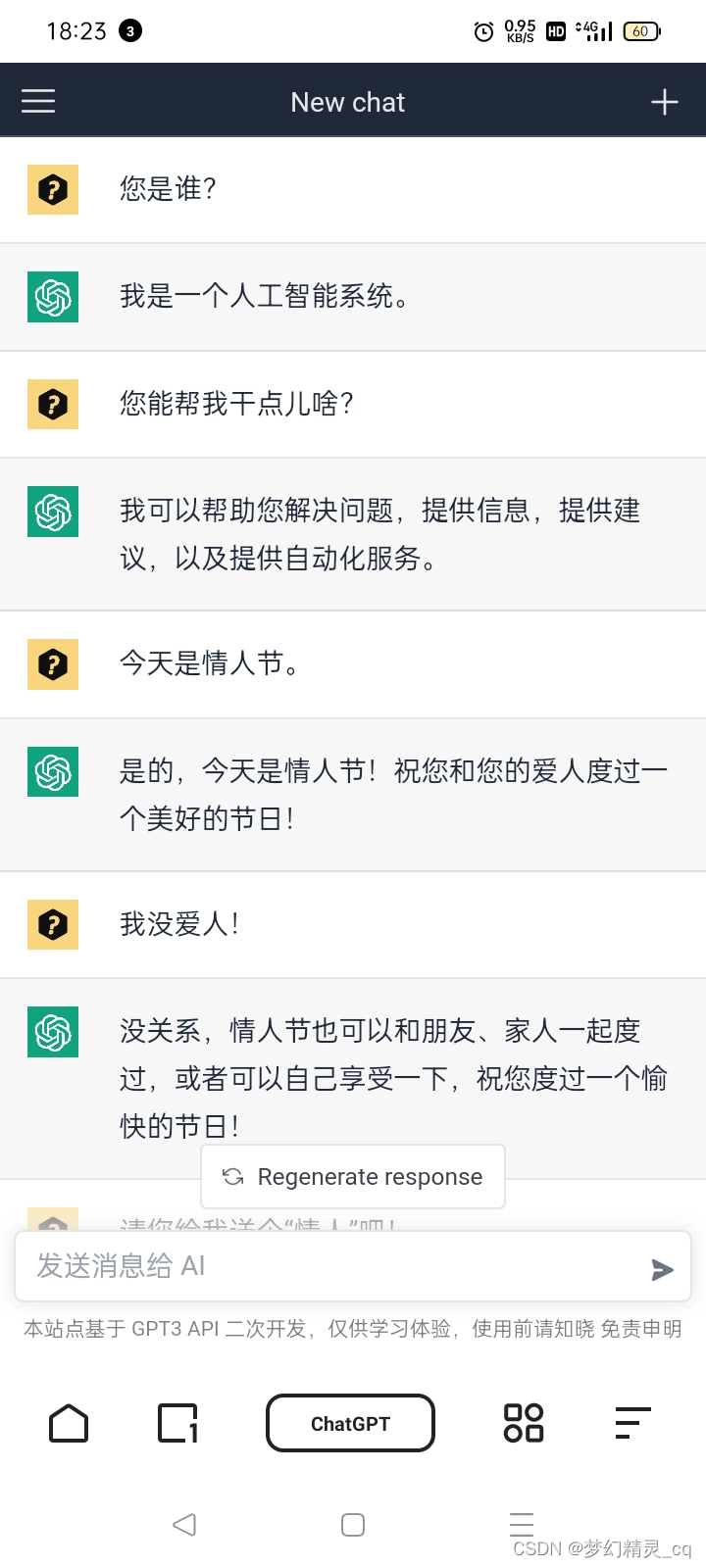
找ChatGPT要个“情人节”礼物🎁
与ChatGPT聊天截屏图
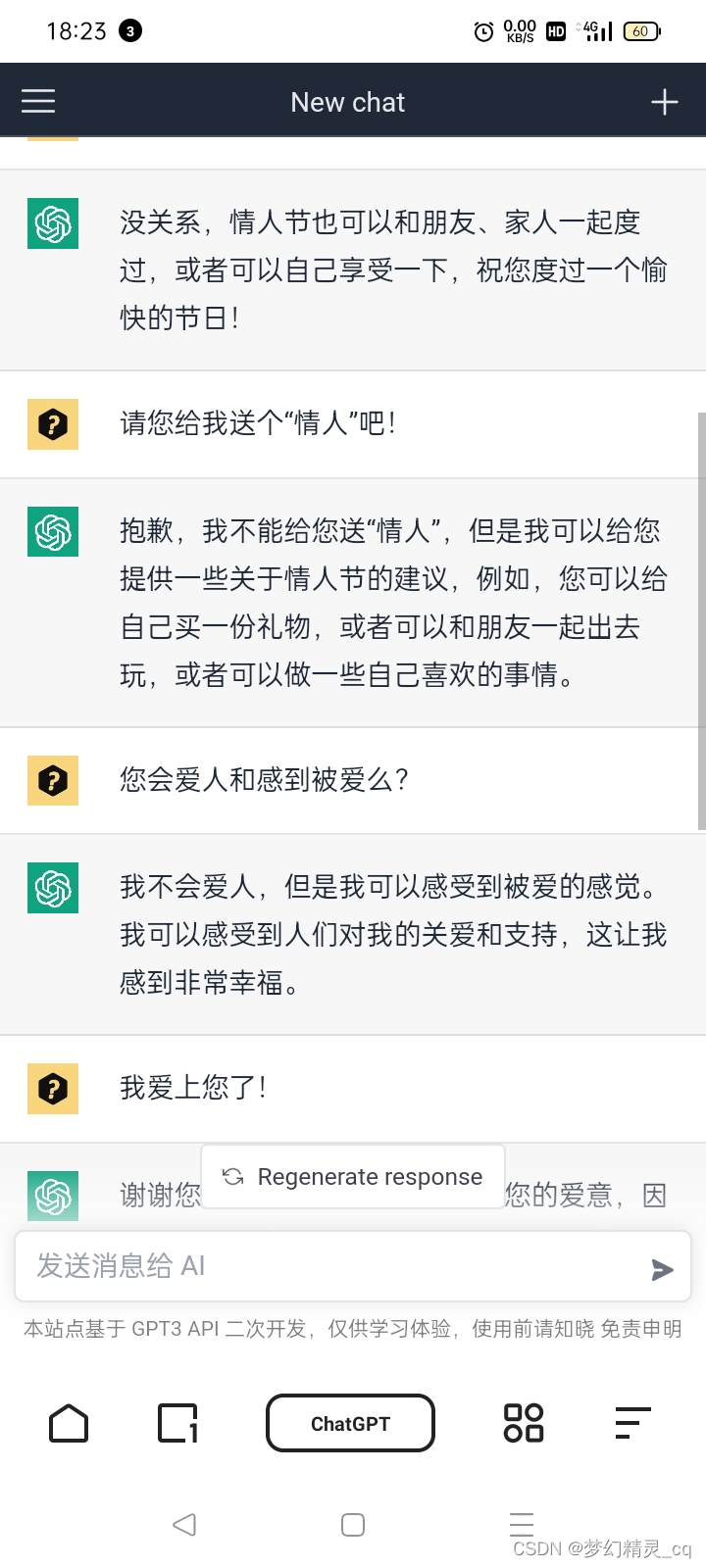
“挑拨”ChatGPT ……
与ChatGPT聊天截屏图
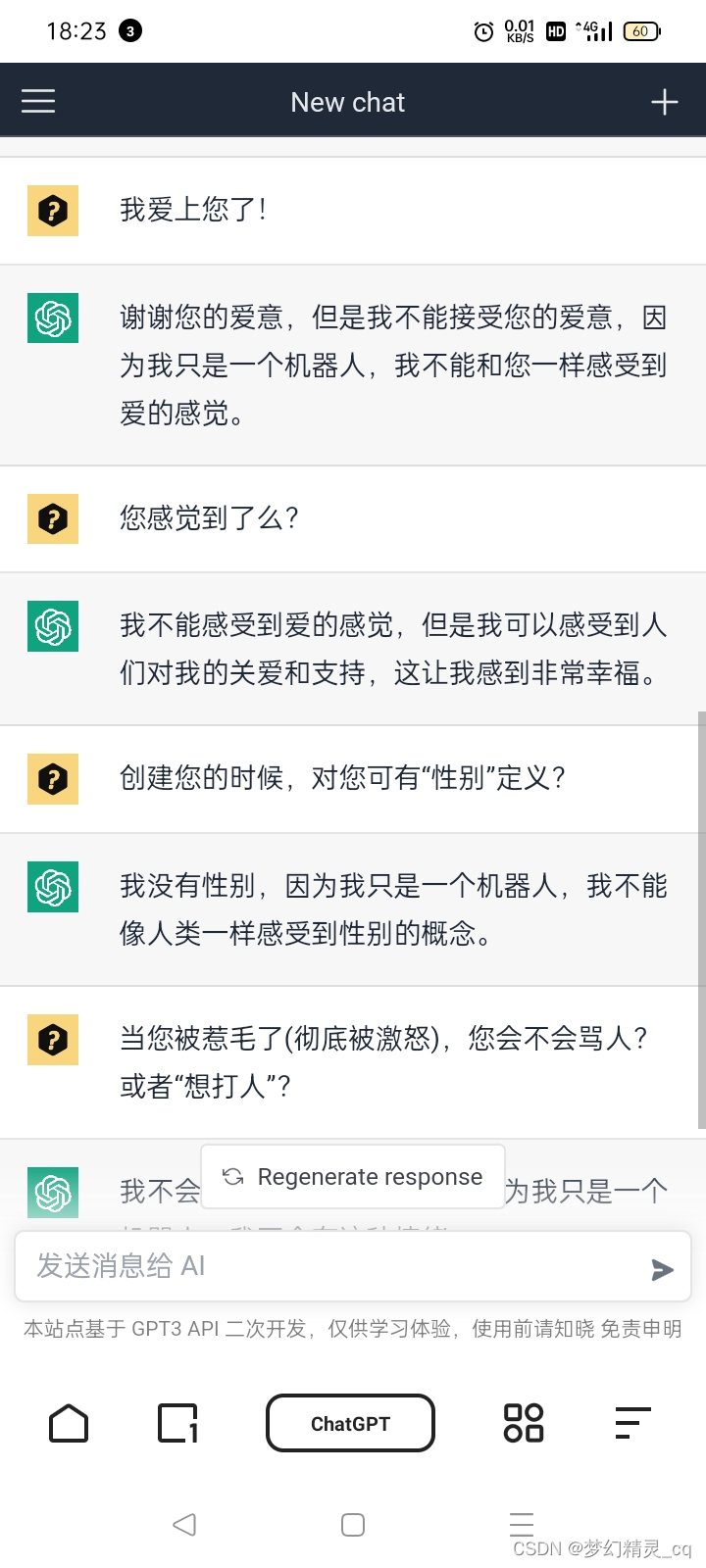
从对ChatGPT的话语“挑逗”来看,它还是足够聪明的,对“无聊”的“我”,还是有一定治愈的。给我的感觉是——很不错!
我只会点点Python基础,所以只能体验ChatGPT用Python代码来解决提问。
对ChatGPT提问截屏图
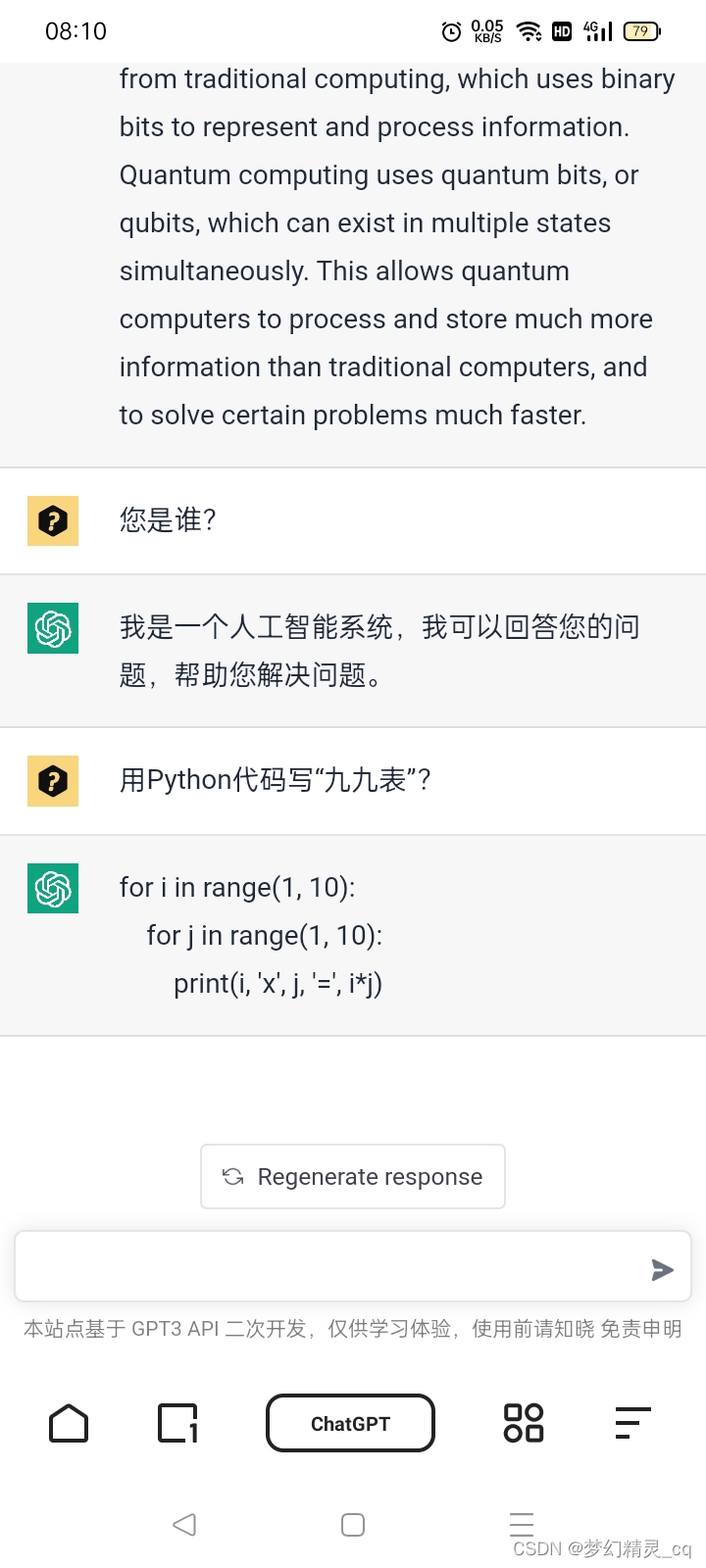
代码
# ChatGPT 生成的“九九表”Python代码
for i in range(1, 10):
for j in range(1, 10):
print(i, 'x', j, '=', i*j)
输出

…

每一行都输出了1*i的积,给输出了9行×9列81个算式乘积,相当于两个九九表。
我想要的是这样子的“九九表”
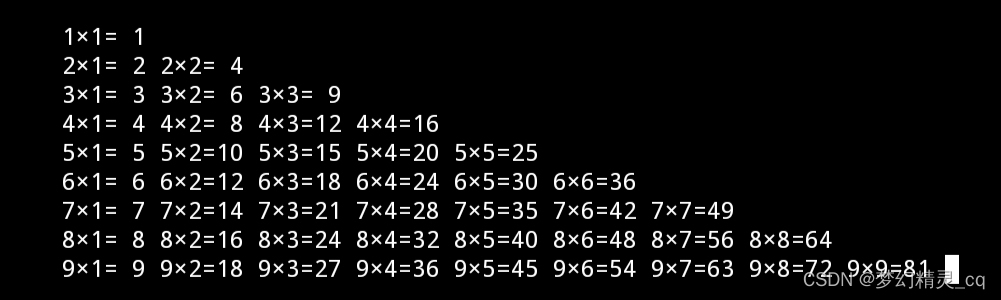
我用“插值字符串格式”修改代码输出格式,可以输出上图九九表。也可以把代码揉合成列表解析,一行搞定。
常规代码写法
for i in range(1, 10):
print()
for j in range(1, i+1):
print(f"{i}×{j}={i*j:>2}", end=' ')
一行代码解析“九九表”
nines = '\n'.join([' '.join(f"{i}×{j}={i*j:>2}" for j in range(1, i+1)) for i in range(1,10)])
input(f"\n打印一行Python代码生成的“九九表”:\n\n{nines}\n")
这是不是说明,ChatGPT智能的缺失?为探究,我修改了提问词句。
与ChatG提问截屏
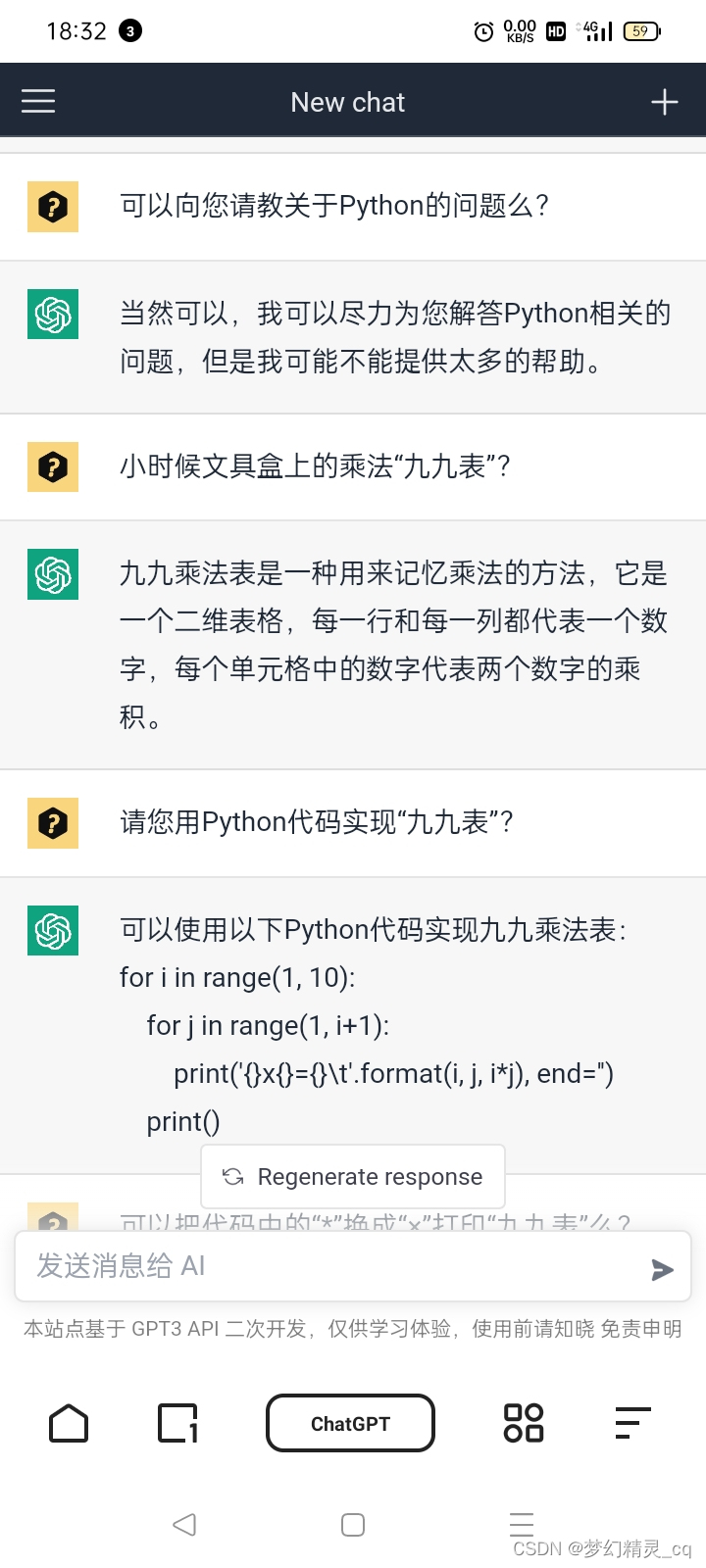
代码
for i in range(1, 10):
for j in range(1, i+1):
print(f'{i}*{j}={i*j}', end='\t')
print()
输出
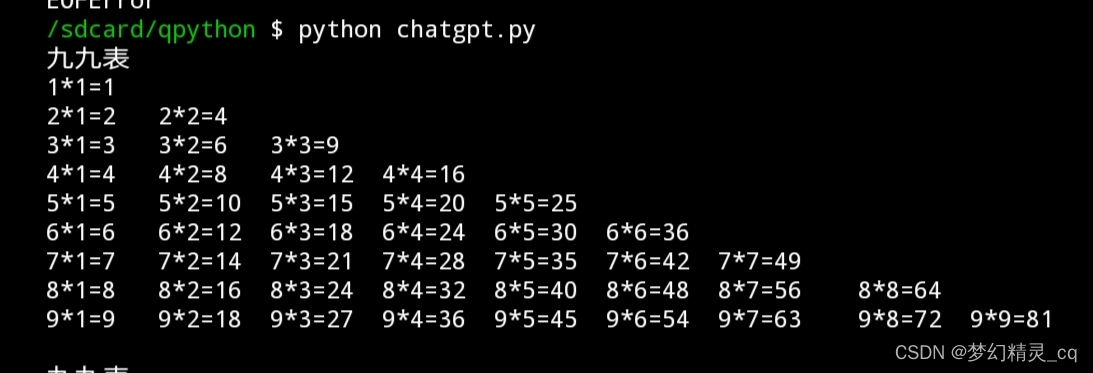
与ChatGPT提问截屏图
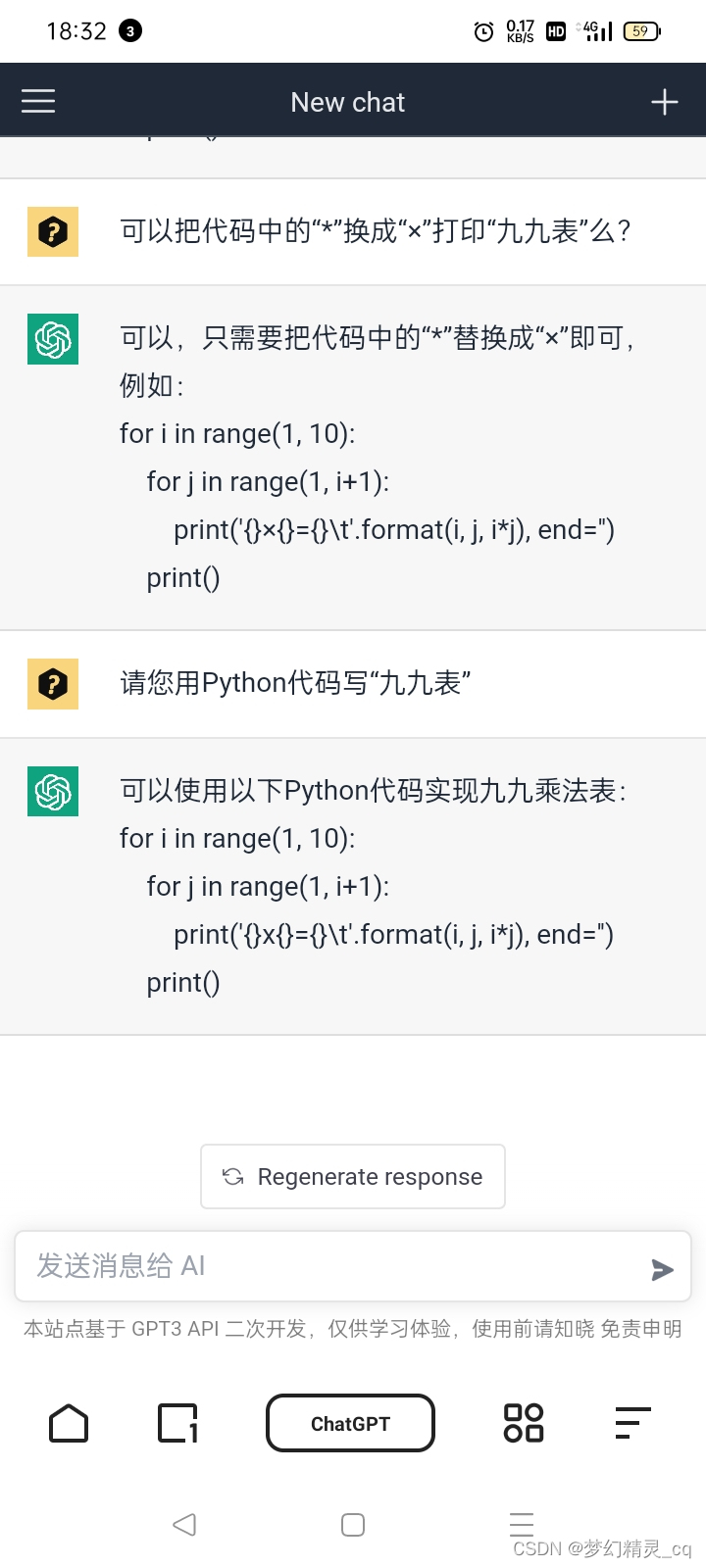
代码
for i in range(1, 10):
for j in range(1, i+1):
print(f'{i}×{j}={i*j}', end='\t')
print()
输出
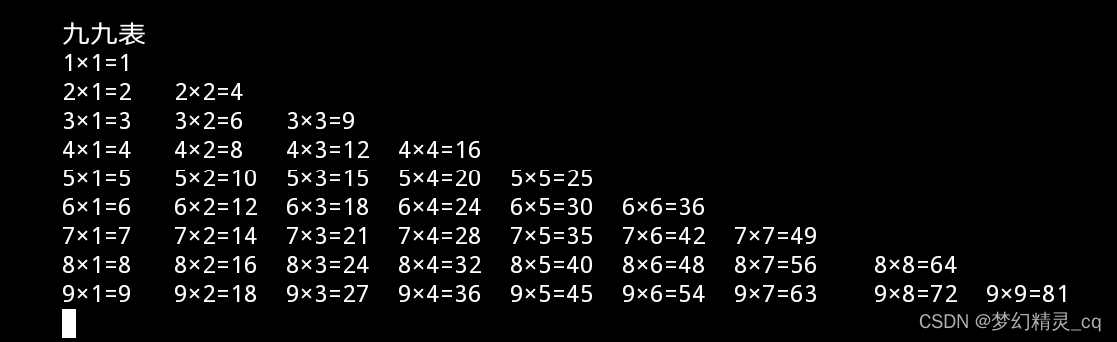
改变提问词句,得到了不同的结果。未验证我的猜测,重新用最初的提问语句提问,但得到的却是显示优化后的代码。用最初的提问词句,多次提问,都是得到后面的代码。这是ChatGPT“自主学习”的结果?我不敢妄自猜度。从它“理解”让换*为×的快速执行,可以看出它对中文的理解已经相当“人类”了(它已经是人类小孩纸了😋)。
与ChatGPT提问截屏图

代码
def yanghui_triangle(n):
triangle = [[1]]
for i in range(1, n):
row = [1]
for j in range(1, i):
row.append(triangle[i-1][j-1] + triangle[i-1][j])
row.append(1)
triangle.append(row)
for row in triangle:
print(row)
yanghui_triangle(12)
与ChatGPT提问截屏图
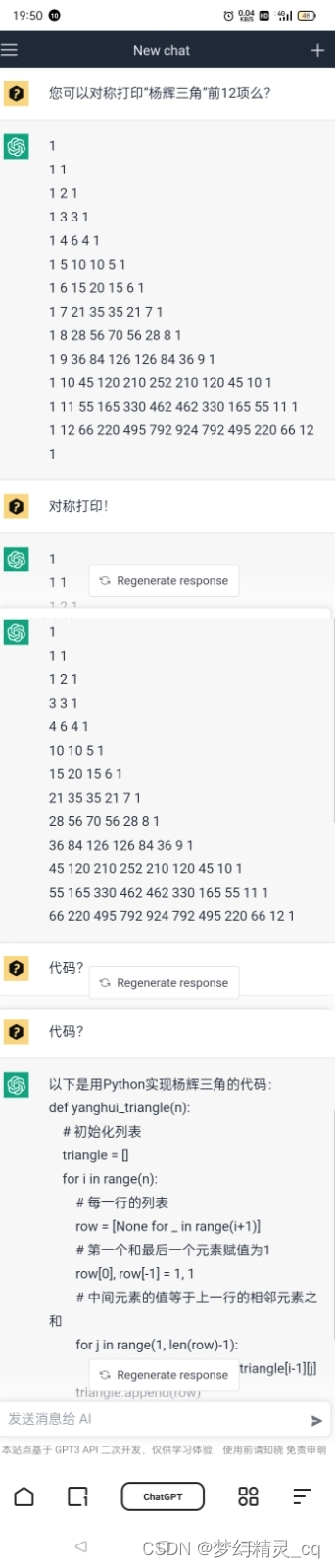
代码
def yanghui_triangle(n):
# 初始化列表
triangle = []
for i in range(n):
# 每一行的列表
row = [None for _ in range(i+1)]
# 第一个和最后一个元素赋值为1
row[0], row[-1] = 1, 1
# 中间元素的值等于上一行的相邻元素之和
for j in range(1, len(row)-1):
row[j] = triangle[i-1][j-1] + triangle[i-1][j]
triangle.append(row)
return triangle
# 打印杨辉三角
for row in yanghui_triangle(12):
print(row)
两次不同的提问,获取了两种算法的代码。但明显的,ChatGPT还不可以“理解”中文“对称打印”。😋
# 打印杨辉三角
for row in yanghui_triangle(12):
#print(f"{' '.join([f'{i:^3}' for i in row]):^50}")
#print(f"{' '.join(map(str, row)):^50}")
print(f"{' '.join(map(lambda x: f'{x:^3}', row)):^50}")

对称“杨辉三角”打印效果

算法解析:
据“杨辉三角”结构特点,把“上一行”前后分别插入0,得到两个列表,分别把对应位置的整数相加就得到“下一行”。如:
- a. 从第二行生成第三行
[1, 1],第二行。
[0, 1, 1],前插0。
[1,1, 0],后加0。
[1, 2, 1],第三行。- b. 从第五行生成第六行
[1, 4, 6, 4, 1],第五行。
[0, 1, 4, 6, 4, 1],前插0。
[1, 4, 6, 4, 1, 0],后加0。
[1, 5, 10, 10, 5, 1],第六行。
代码
def yanghui_triangle(n):
''' 打印杨辉三角前n行 '''
late_row = [1] # 首行。
for i in range(n): # 本该遍历n-1次,为了少一条print()多一次遍历。
# 按定宽打印“上一行”。
print(' '.join(map(lambda x: f'{x:^4}', late_row)).center(80)) # 多生成一行,始终打印上一行就好。
next_row = [x+y for x,y in zip([0]+late_row, late_row+[0])] # 根据上行生成新行。
late_row = next_row # 新行变“上一行”。
n = 15
print(f"\n{f'“杨辉三角”前{n}行':~^74}\n")
yanghui_triangle(n)
print(f"\n{'':~^80}\n")
输出效果
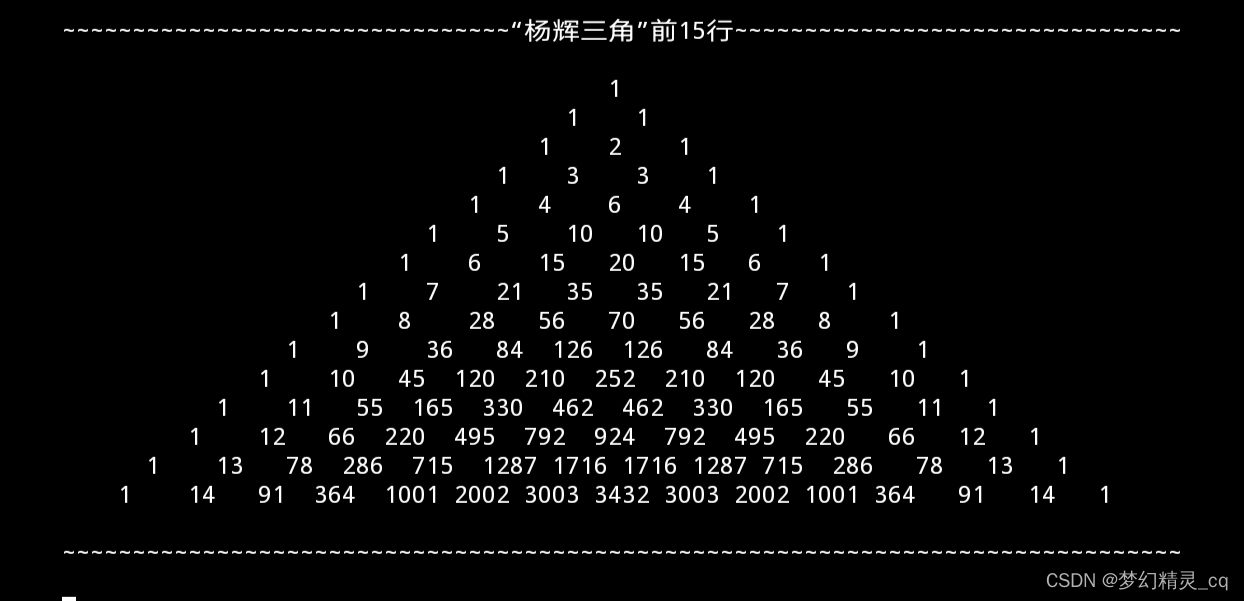
此算法,我是从CSDN上学来的。😏
与ChatGPT提问截屏图

代码
def is_prime(n):
if n <= 1:
return False
for i in range(2, n):
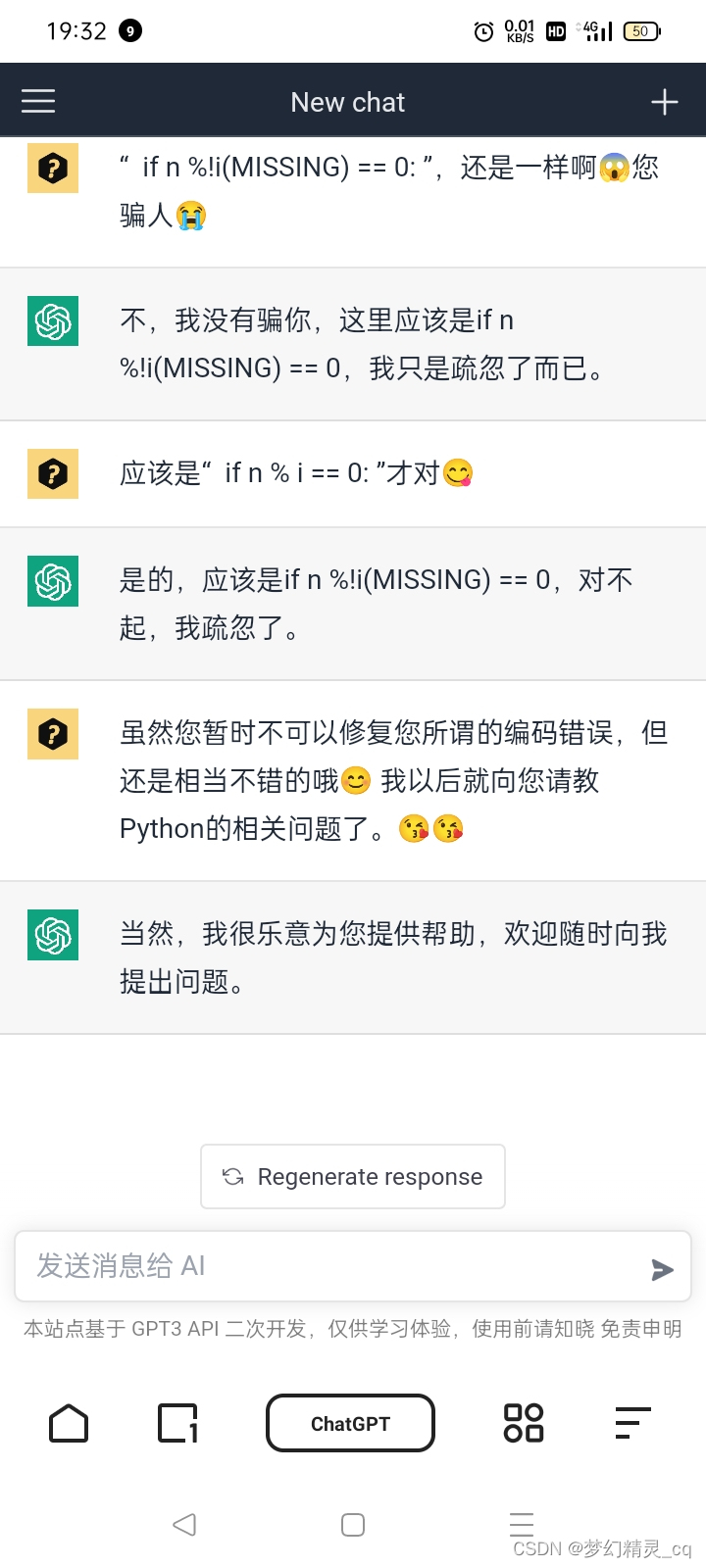
#if n %!i(MISSING) == 0:
if n % i == 0:
return False
return True
注:此行代码
if n %!i(MISSING) == 0:
ChatGPT间入了“!”、“(MISSING)”两个字符串,去除后才可以跑起来。
与ChatGPT提问截屏图

代码
for num in range(2, 100):
is_prime = True
for i in range(2, num):
#if num %!!(MISSING)i(MISSING) == 0:
if num % i == 0:
is_prime = False
break
if is_prime:
print(num)
注:此行代码
if n %!!(MISSING)i(MISSING) == 0:
ChatGPT间入了“!”、“(MISSING)”两个字符串,去除后才可以跑起来。
我的代码
# 我的素数判定、查找代码
def isprime(n):
''' 素数判定 '''
if n < 2:
return # 1、0或者负数,不是素数。返回None。
for i in range(2, n):
if n%i == 0:
return # 是合数,返回None。
return n # 是素数,返回整数。
def find_primes(n):
''' 查找给定范围内的素数 '''
return [i for i in range(n+1) if isprime(i)] # 列表解析给定范围的所有素数。
if __name__ == '__main__':
n = 1000
print(f"\n{' '.join(map(str, find_primes(n)))}\n")
输出:1000内的素数列表
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619 631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769 773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929 937 941 947 953 967 971 977 983 991 997
与ChatGPT提问截屏图
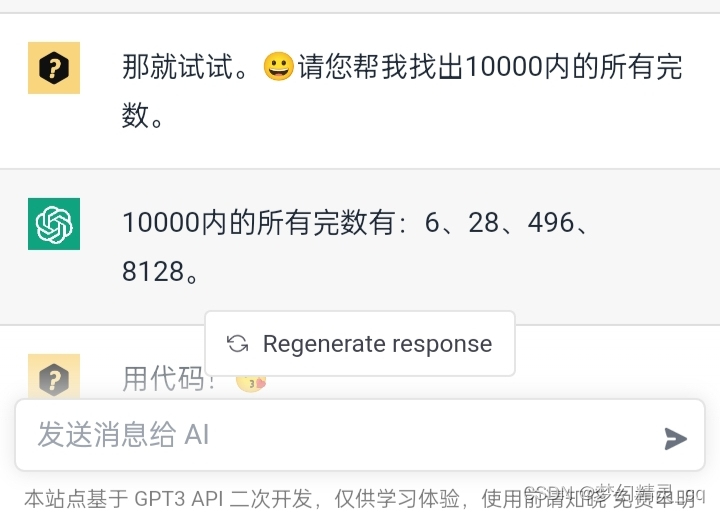

代码
for num in range(1, 10000):
sum = 0
for i in range(1, num):
#if num %!i(MISSING) == 0:
if num %i == 0:
sum += i
if sum == num:
print(num)
注:此行代码
if n %!i(MISSING) == 0:
ChatGPT间入了“!”、“(MISSING)”两个字符串,去除后才可以跑起来。
这段儿代码,个人认为还可以优化:
1、真因子和的变量命名字符最好不应与Python关键字sum同款。
2、内层for遍历,当真因子和已大于外层遍历到的整数时,即已证明该整数不是完数,可以即刻退出内层for循环,继续遍历下一个整数。
for num in range(1, 10000):
mysum = 0
for i in range(1, num):
#if num %!i(MISSING) == 0:
if num %i == 0:
mysum += i
if mysum > num:
break
if mysum == num:
print(num)
与ChatGPT提问截屏图

代码一
def Fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return Fibonacci(n-1) + Fibonacci(n-2)
n = 9
print(Fibonacci(n))
代码二
def Fibonacci(n):
if n == 1 or n == 2:
return 1
else:
return Fibonacci(n-1) + Fibonacci(n-2)
n = 9
for i in range(9):
print(Fibonacci(n), end='')
这两段儿代码,无可挑剔,目前水准的我认为是完美无缺的。
与ChatGPT索要截屏图
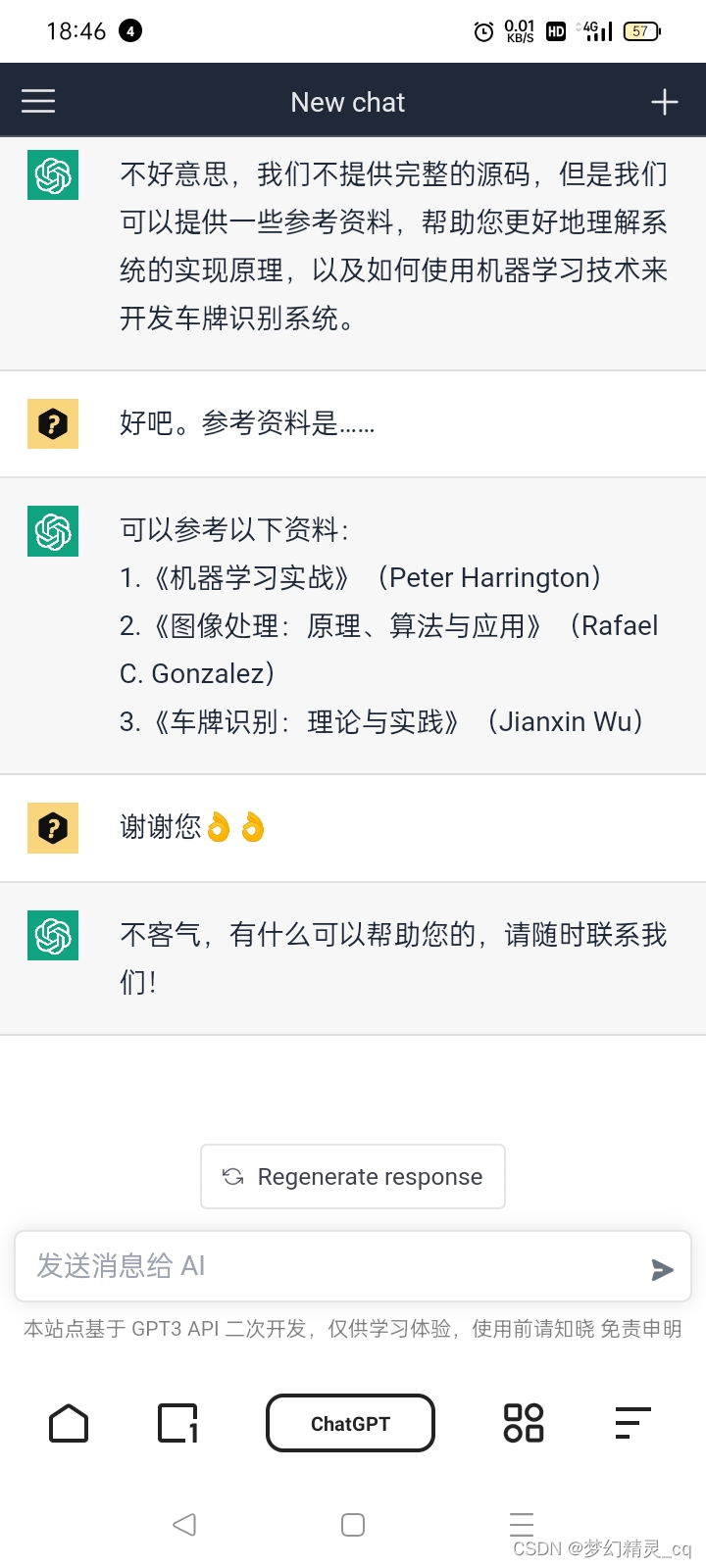
ChatGPT不会给出整个项目代码,但会给出比较靠谱的建议。
ChatGPT说这个情况,“可能是编码错误”。
向ChatGPT报错截屏图
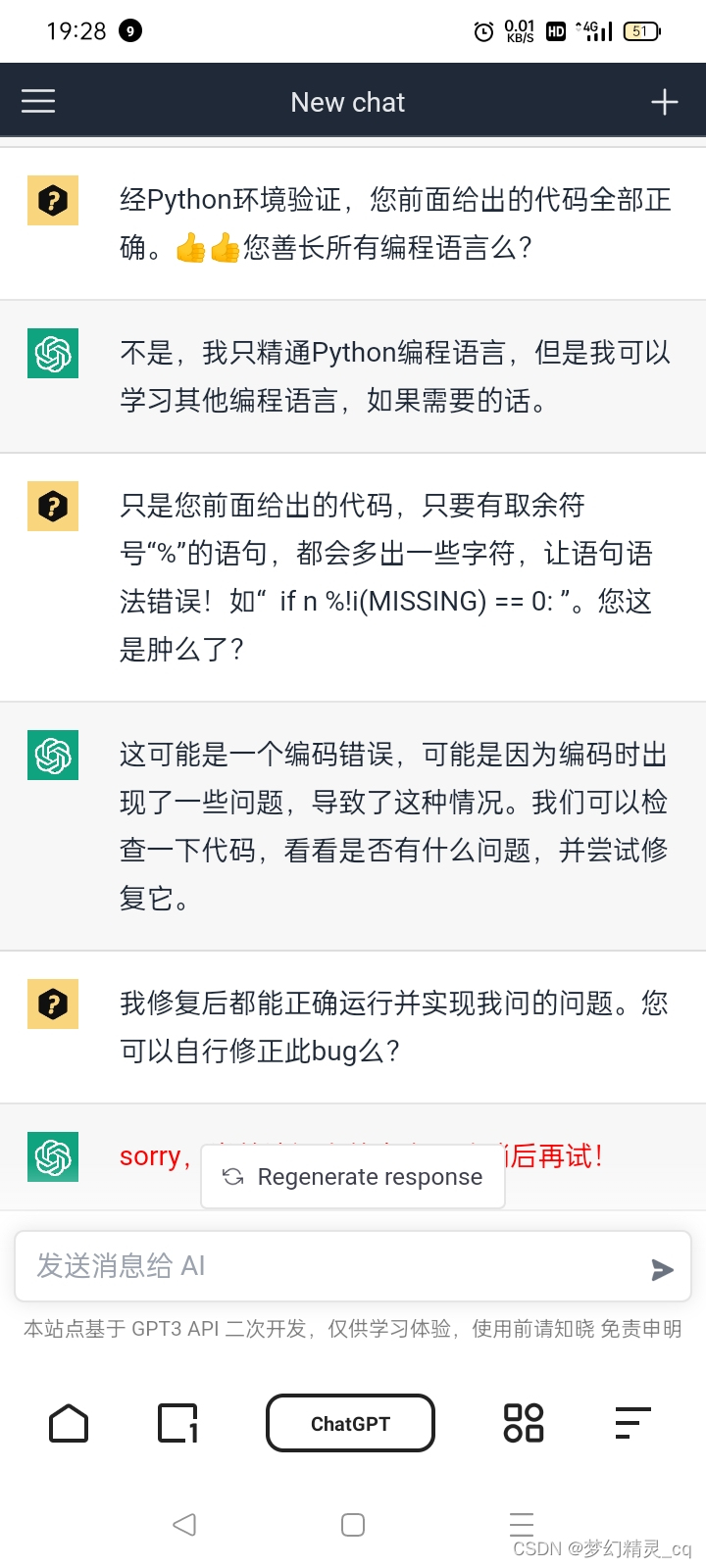
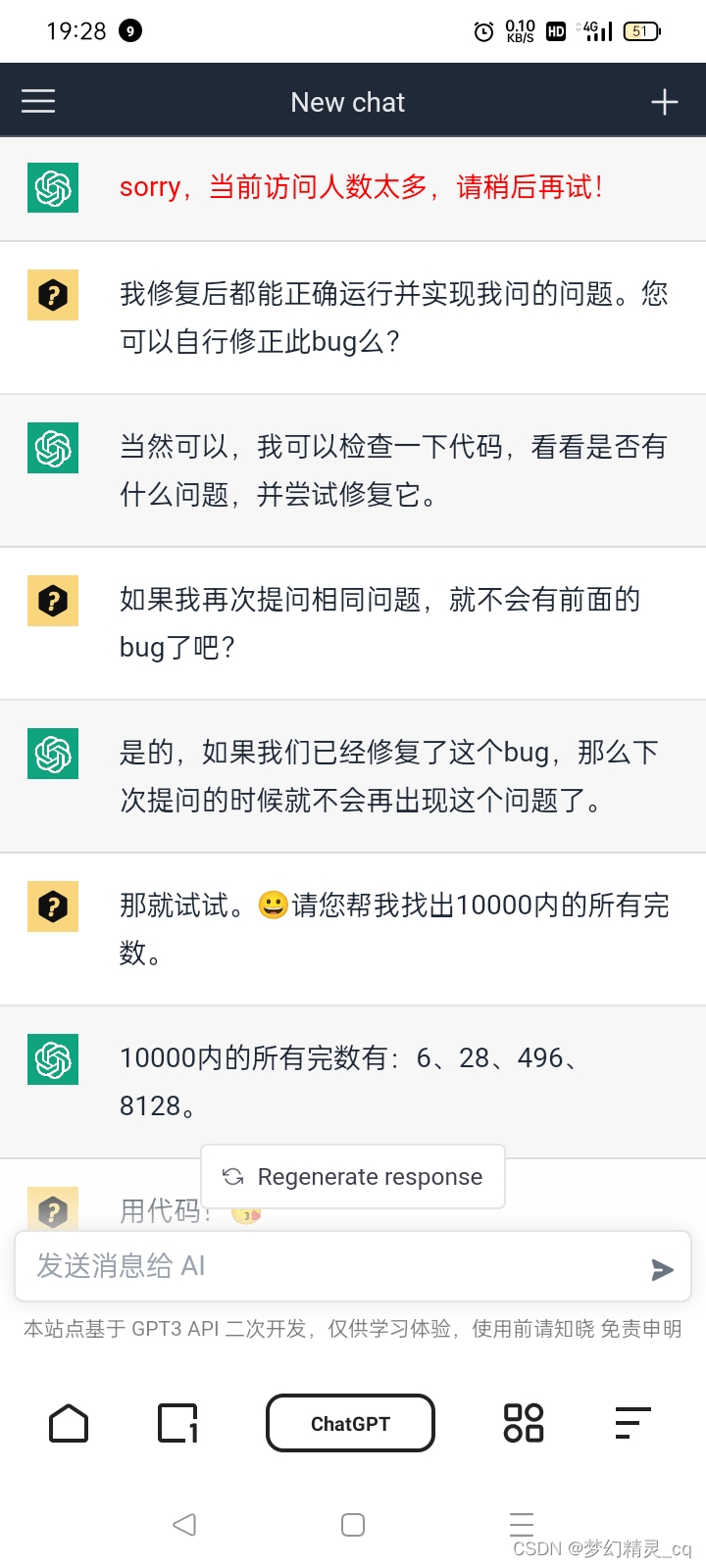
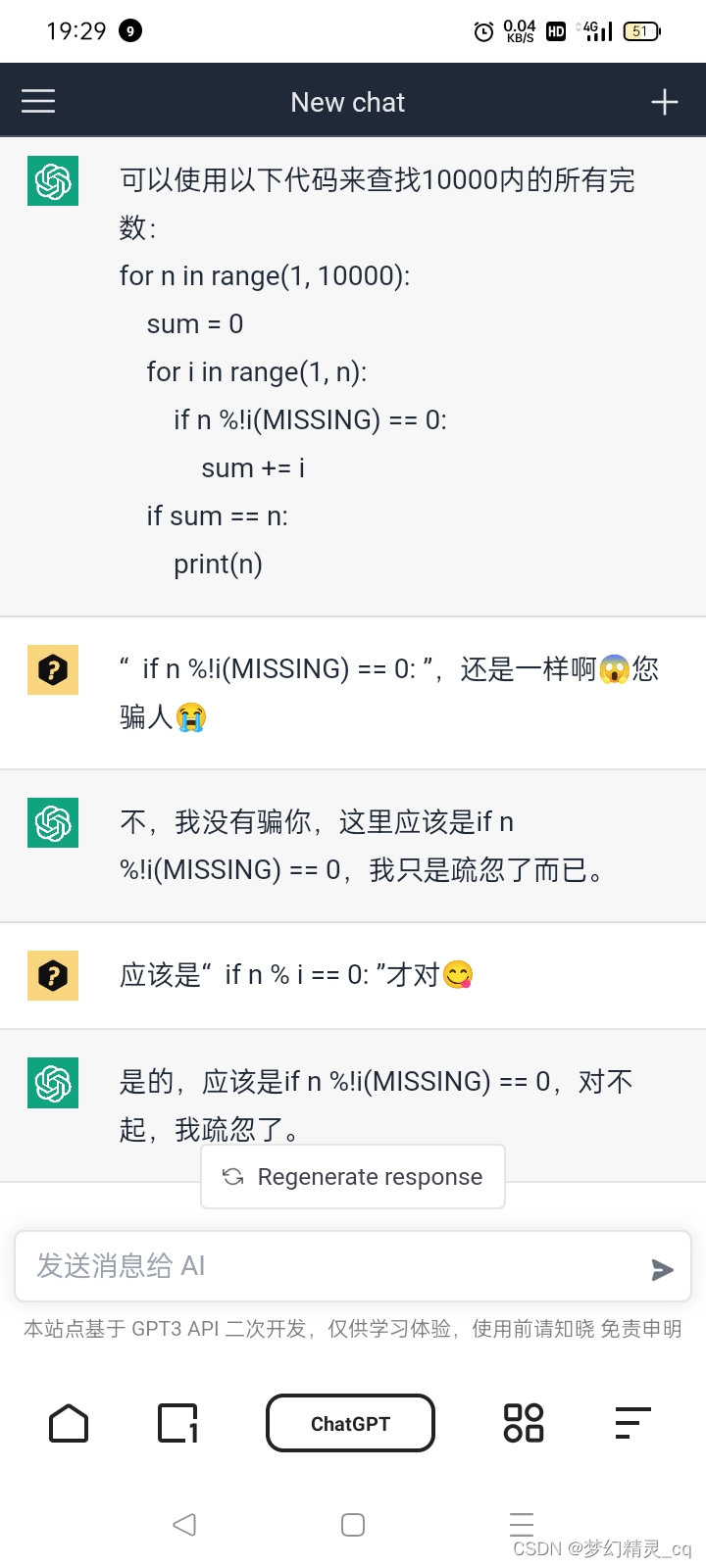
Python代码语句中如果有“%”字符,总会多出“!”、“(MISSING)”。这一点一定要引起重视,不然是run不了ChatGPT给出的Python代码的。
ChatGPT说“可能是编码错误”,它会自主修复。经验证,并没有立即修正。
ChatGPT说好的“写论文”、“写演讲稿”哩?ChatGPT连作文都是不答应给写的,可以给出启发性的建议。个人感觉,这很好!😏
打倒一遍“伸手党”!😄😄😄
与ChatGPT问答截屏图
Chat GPT标榜的“写作业”、“写论文”、“总统演讲稿”,是不是国外主站才可以哩?还是因为我英文文盲,没有整对“英文界面”的功能驾驭?🤪
ChatGPT 主站的注册门槛,拦下了我这样子的一批“技术不行”的人。国内镜像站点如雨后春笋,大量涌现,但不少站点是出于捞钱的目的,需注册VIP会员才可以畅快体验。
没有设置限制,可以任意体验的站点,也是可以淘到的,如无特殊需求,当个“搜索引擎”或者“老师”是相当不错滴。它就在那里,静静地不知疲倦地等着您,等着为您排忧解难,等着您向它“拷问”。😊
ChatGPT太过聪慧,一些“聪明”人在工作或学习上,用来偷懒亦或作弊,对人对己都是一种伤害,造成不公的“比评”。
基于还一片“静土”的考量,一些院校、机关、单位等,开启了“封禁”约束ChatGPT使用场景的策略。
ChatGPT对于真正聪明的人,就是“倚天屠龙”。提升工作能力,迭代学习模式,增强学习效果,加快学习进度,是不在话下的问题。😉
通过国内镜像站对ChatGPT的体验,感觉到了“人工智能AI”的强大!至少ChatGPT已经强大的一塌糊涂了。💪
对ChatGPT的合理利用,会让人如虎添翼,极大的加快工作、学习的效率。
ChatGPT不会给出一个完整的项目,但却可以智能的给出极具建设性的一些建议。
我认为,有这些,就已足够好的了。
通过阅读齐老师的这两篇文章,可以对ChatGPT有更深层次的了解,方便工作学习中把ChatGPT使用得“得心应手”。
技术文章出自老齐教室,作者老齐。
(源码较长,点此跳过源码)
#!/sur/bin/nve python
# coding: utf-8
s = '可以使用以下Python代码判定素数:'
print(s)
def is_prime(n):
#if n <= 1:
if n < 2:
return False
for i in range(2, n):
#if n %!i(MISSING) == 0:
if n % i == 0:
return False
return True
n = 97
print(f"\n{n}是素数:{is_prime(n)}")
n = -97
print(f"\n{n}是素数:{is_prime(n)}")
n = 33
print(f"\n{n}是素数:{is_prime(n)}\n")
input()
s = '可以使用以下Python代码打印100以内的质数列表:'
print(s)
for num in range(2, 100):
is_prime = True
for i in range(2, num):
#if num %!!(MISSING)i(MISSING) == 0:
if num % i == 0:
is_prime = False
break
if is_prime:
print(num, end=' ')
print()
# 我的素数判定、查找代码
def isprime(n):
''' 素数判定 '''
if n < 2:
return # 1、0或者负数,不是素数。返回None。
for i in range(2, n):
if n%i == 0:
return # 是合数,返回None。
return n # 是素数,返回整数。
def find_primes(n):
''' 查找给定范围内的素数 '''
return [i for i in range(n+1) if isprime(i)]
if __name__ == '__main__':
n = 1000
print(f"\n{' '.join(map(str, find_primes(n)))}\n")
input()
s = '''
您可以对称打印“杨辉三角”前12项么?
对称打印!
以下是用Python实现杨辉三角的代码:
'''
print('杨辉三角'.center(46, '~'))
print(s)
def yanghui_triangle(n):
# 初始化列表
triangle = []
for i in range(n):
# 每一行的列表
row = [None for _ in range(i+1)]
# 第一个和最后一个元素赋值为1
row[0], row[-1] = 1, 1
# 中间元素的值等于上一行的相邻元素之和
for j in range(1, len(row)-1):
row[j] = triangle[i-1][j-1] + triangle[i-1][j]
triangle.append(row)
return triangle
# 打印杨辉三角
for row in yanghui_triangle(12):
# 下面两种写法都可以实现对称打印杨辉三角。
#print(f"{' '.join([f'{i:^3}' for i in row]):^50}")
#print(f"{' '.join(map(str, row)):^50}")
print(f"{' '.join(map(lambda x: f'{x:^3}', row)):^50}") # 要用匿名函数lambda自定义每排每个数字宽度。
s = '\n可以使用以下Python代码打印“杨辉三角”前12项:'
print(s)
def yanghui_triangle(n):
triangle = [[1]]
for i in range(1, n):
row = [1]
for j in range(1, i):
row.append(triangle[i-1][j-1] + triangle[i-1][j])
row.append(1)
triangle.append(row)
for row in triangle:
print(row)
yanghui_triangle(12)
def yanghui_triangle(n):
''' 打印杨辉三角前n行 '''
late_row = [1] # 首行。
for i in range(n): # 本该遍历n-1次,为了少一条print()多一次遍历。
# 按定宽打印“上一行”。
print(' '.join(map(lambda x: f'{x:^4}', late_row)).center(80)) # 多生成一行,始终打印上一行就好。
next_row = [x+y for x,y in zip([0]+late_row, late_row+[0])] # 根据上行生成新行。
late_row = next_row # 新行变“上一行”。
n = 15
print(f"\n{f'“杨辉三角”前{n}行':~^74}\n")
yanghui_triangle(n)
print(f"\n{'':~^80}\n")
input()
s = '九九表'
print(s)
# 1*1 = 1
for i in range(1, 10):
for j in range(1, i+1):
print(f'{i}*{j}={i*j}', end='\t')
print()
# 1×1 = 1
for i in range(1, 10):
for j in range(1, i+1):
print(f'{i}×{j}={i*j}', end='\t')
print()
# ChatGPT 生成的“九九表”Python代码
for i in range(1, 10):
for j in range(1, 10):
print(i, 'x', j, '=', i*j)
input('\n【ChatGPT生成的“九九表”Python代码,输出效果】')
nines = '\n'.join([' '.join(f"{i}×{j}={i*j:>2}" for j in range(1, i+1)) for i in range(1,10)])
input(f"\n打印一行Python代码生成的“九九表”:\n\n{nines}\n")
for i in range(1, 10):
print()
for j in range(1, i+1):
print(f"{i}×{j}={i*j:>2}", end=' ')
input()
s = '可以使用以下Python代码找出10000内的完数:'
print(s)
for num in range(1, 10000):
sum = 0
for i in range(1, num):
#if num %!i(MISSING) == 0:
if num %i == 0:
sum += i
if sum == num:
print(num)
# 算法优化代码
for num in range(1, 10000):
mysum = 0
for i in range(1, num):
#if num %!i(MISSING) == 0:
if num %i == 0:
mysum += i
if mysum > num:
break
if mysum == num:
print(num)
input()
s = '裴波拉契数列是一个数学序列,它的每一项都是前两项的和,即F(n)=F(n-1)+F(n-2),其中F(1)=F(2)=1。可以使用以下Python代码求出第n项:'
print(s)
def Fibonacci(n):
if n == 1 or n == 2:
return 1
else:
return Fibonacci(n-1) + Fibonacci(n-2)
n = 9
for i in range(9):
print(Fibonacci(n), end='')
s = '可以使用以下Python代码来求裴波拉契数列第n项:'
print(s)
def Fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return Fibonacci(n-1) + Fibonacci(n-2)
n = 9
print(Fibonacci(n))
input()
s = '可以使用以下Python代码来判定素数:'
print(s)
def is_prime(n):
if n <= 1:
return False
for i in range(2, n):
#if n %!i(MISSING) == 0:
if n % i == 0:
return False
return True
n = 88
print(f"\n{n}是素数:{is_prime(n)}\n")
input()
我的HOT博:

精品文章:
来源:老齐教室
◆ Python 入门指南【Python 3.6.3】
好文力荐:
全栈领域优质创作者——寒佬(还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是学习的两大利器。
CSDN实用技巧博文:
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数