目录
这里特别说一下,我们的域名和服务器均来自腾讯云。腾讯云的某些秒杀活动需要谨慎参加,因为后期的续费可能变得难以负担,同志们谨慎消费!
服务器购买了腾讯云的2核4G服务器,峰值带宽:30Mbps。
服务器简单配置了Linux宝塔面板:
wget -O install.sh http://download.bt.cn/install/install-ubuntu_6.0.sh && sudo bash install.sh安装好后一定要记住当下的用户名和密码,以及端口。我们要在服务器防火墙的安全组中添加规则。
根据宝塔面板提供的帮助,我们可以装好:PHP,phpmyadmin,Nginx,mysql,FTPServer
因为这是一个以Python为基础的项目,因此Python安装很重要(Python3.6版本)
命令如下:
wget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgz
tar -xf Python-3.6.3.tgz
cd Python-3.6.3
./configure --prefix=/usr/local/python3
make
make install
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
vim ~/.bash_profile
写入如下内容:
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin:/usr/local/python3/bin
export PATH
source ~/.bash_profile
sudo echo alias python=python3 >> ~/.bashrc
source ~/.bashrc
python3 -V
pip3 -V这里已经设置了Python的默认版本并且安装了pip3,但是为了避免不必要的麻烦,可以直接用python3 xxx.py 进行操作,这样最稳妥,不会出现任何异常。

装好Python3.6后安装对应的第三方依赖包,,我们也用pip3进行第三方包安装:
pip3 install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com之后安装nodejs(14版本)和npm
sudo apt update
sudo apt install nodejs npm
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash - 14版本是最新最稳定的!
sudo apt install nodejs
node --version
npm --version
sudo apt install build-essential# encoding: utf-8
import os
import schedule
dirname = r"/www/wwwroot/hesuan/testimg2"
def run():
if(len(os.listdir(dirname))!=0): # 检查项目源文件是否为空,非空则开始运行
os.system("python3 view.py")
schedule.every(1).minutes.do(run) # 为了减少运行压力,每分钟执行一次
while True:
schedule.run_pending()# encoding: utf-8
import schedule
import os
import zipfile
import shutil
import pymysql
dirname = r"/www/wwwroot/hesuan/testimg1" # 压缩文件目录
def zip():
file = dirname
zipfile_name = os.path.basename(file) + '.zip' # 将目标文件压缩为zip文件
with zipfile.ZipFile(zipfile_name, 'w') as zfile:
for foldername, subfolders, files in os.walk(file):
zfile.write(foldername)
for i in files:
zfile.write(os.path.join(foldername, i))
zfile.close()
schedule.every().monday.at("00:00").do(zip) # 每周一 00:00执行一次压缩
while True:
schedule.run_pending()# encoding: utf-8
import schedule
import os
import zipfile
import shutil
import pymysql
filepath = r"/www/wwwroot/hesuan/testimg1" # 定期清空的目标文件
host = "127.0.0.1"
username = "hesuan_result"
passwd = "???"
dbname = "hesuan_result"
port = 3306
charset = "utf8"
table_name = "xinan"
def clear():
db = pymysql.connect(host=host, user=username, passwd=passwd, port=port, db=dbname)
cursor = db.cursor()
sql_delete = "Update %s set time_result = '' , test_result = '' " % table_name
cursor.execute(sql_delete) # 清空数据表
db.commit()
shutil.rmtree(filepath) # 删除目标文件
os.mkdir(filepath) # 再新建一个一样的文件
print("Okkkkkkkkkkkkkkk")
# clear()
schedule.every().tuesday.at("00:00").do(clear)
while True:
schedule.run_pending()sudo npm install -g pm2pm2 list
pm2 start (all)
pm2 delete (all)
pm2 stop (all)
pm2 restart
pm2 start run.py -x --interpreter python3 # 挂载Python项目每次启动成功后,要 pm2 save , pm2 list 保存并查看是不是挂载成功。

但是考虑到,我们的服务器只有2核4G,并不能同时挂载很多像上面的run.py,所以我们需要进行一个串行安排,但如果班级太多又可能有班级一直得不到响应。所以我做了一个用随机数控制的,串行并行结合的进程控制方式。
首先,如果你的服务器有4个核,希望你用python最正经的进程安排
t1 = threading.Thread(target=进程1)
t2 = threading.Thread(target=进程2)
t1.start()
t2.start()但可惜,我的服务器虽然有两个核,但安排两个进程的话,单核CPU无法解决问题
# encoding: utf-8
def run1():
print("working")
if(len(os.listdir(dir20xinan))!=0):
print("20信安")
os.system("python3 /www/wwwroot/hesuan/view.py")
if(len(os.listdir(dir20ruangong))!=0):
print("20软工")
os.system("python3 /www/wwwroot/hesuan20ruangong/view.py")
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
def run2():
print("working")
if(len(os.listdir(dir19yingcai))!=0):
print("19英才")
os.system("python3 /www/wwwroot/hesuan19yingcai/view.py")
if(len(os.listdir(dir19jike))!=0):
print("19计科")
os.system("python3 /www/wwwroot/hesuan19jike/view.py")
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
def run():
print("start")
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
if(len(os.listdir(dir20xinan))==0 and len(os.listdir(dir20ruangong))==0 and len(os.listdir(dir19yingcai))==0 and len(os.listdir(dir19jike)) == 0):
print("resting")
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
time.sleep(10)
else:
rand = random.randint(0, 1)
if rand == 0:
run1()
if rand == 1:
run2()
print("finished ALL")
print(time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()))
schedule.every(1).minute.do(run)
while True:
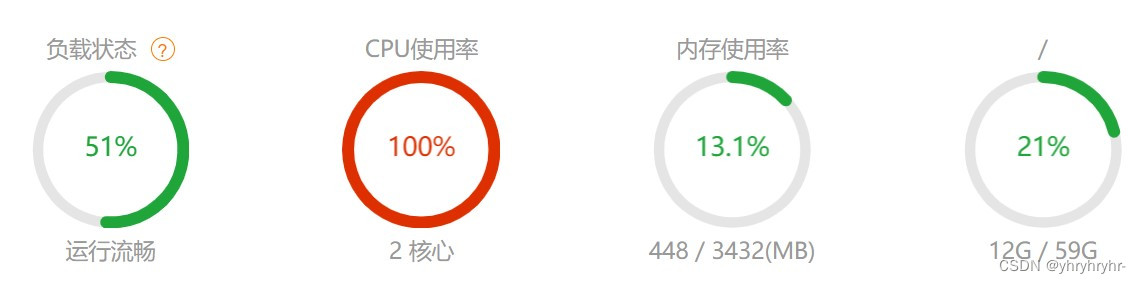
schedule.run_pending()本项目对CPU要求较高,我们重点关注负载,而不是CPU使用(因为代码工作量确实大)
可以用下面这段代码,添加到Nginx.conf配置文件的server{}中,解决端口和域名的对应问题,但首先我们要把域名解析到服务器,@和www都要解析,这样我们输入不输入www就都可以访问到我们的网站了
server {
listen 80;
server_name www.hengmengkeji.cn;
proxy_ignore_client_abort on;
location / {
proxy_pass http://127.0.0.1:3000/;
proxy_read_timeout 3200;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}listen 80 是因为我们每次访问域名都是默认的80端口
server_name 是我们解析到服务器的域名
proxy_pass 后填写我们要代理的IP:端口
如果是绑定根目录,其实宝塔的服务配置就很🆗,我们同样是把域名解析到对应同公司下的服务器,在添加项目绑定站点:

同样是有没有www的两个域名都要绑定,这样可以保证访问的稳定。
绑定后,我们在根目录就可以看到网站的内容了,如果你现在访问域名得到绑定成功的界面,那就可以往里添加自己的项目了!
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在