目录
Torch是一个用于深度学习的=数学计算库,而Pytorch则是一个基于Torch的Python机器学习库,可看作其提供了Torch应用于Python的接口。而搭建Pytorch虚拟环境,通俗地讲,就是搭建一个包含了Pytorch的相关包的Python解释器的环境,即是专门用于处理基于Python的深度学习的问题的环境。
CUDA(Compute Unified Device Architecture)中文名为统一计算设备架构,,是显卡厂商NVDIV推出的运算平台,可以帮助GPU处理图形相关的计算问题。
我们可以通过在命令行输入以下命令来查看我们电脑的CUDA版本配置,下面可以看到我的CUDA版本为11.7(若电脑没有独立显卡,则该命令输入无效,独立显卡问题在第四部分说明,可先看第该部分说明)。
nvidia-smi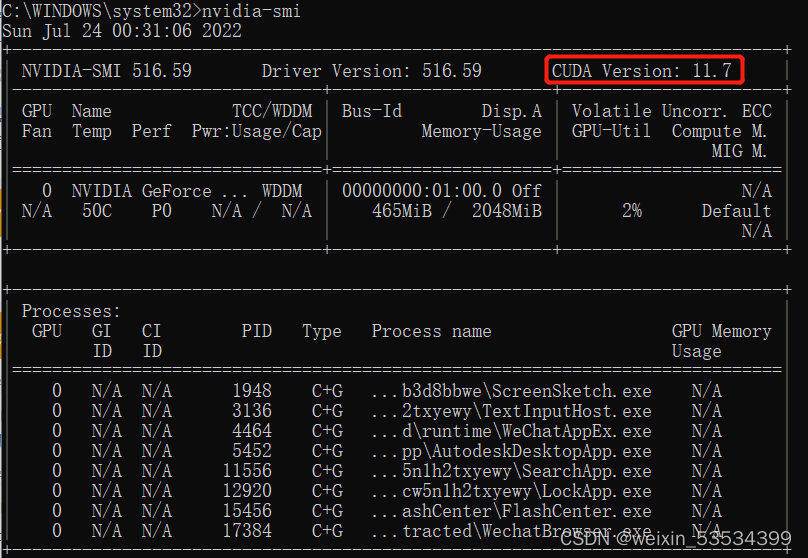
(这里说明一下,因后面的命令行操作有些操作需要以管理员身份运行,所以建议大家从一开始就以管理员身份运行命令行窗口)具体操作方法有以下两种:
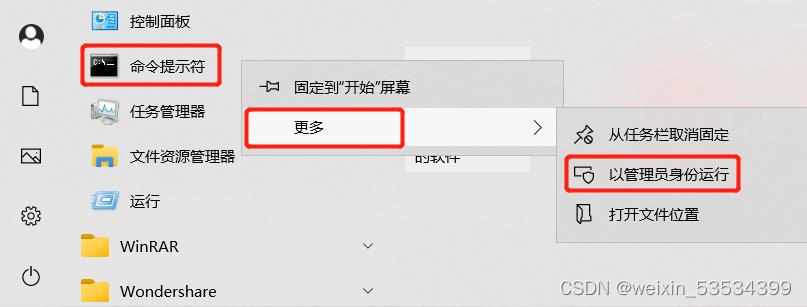
1. Windows开始窗口->Windows系统->命令提示符(注意先不要直接左键打开)->右键->更多->以管理员身份运行。
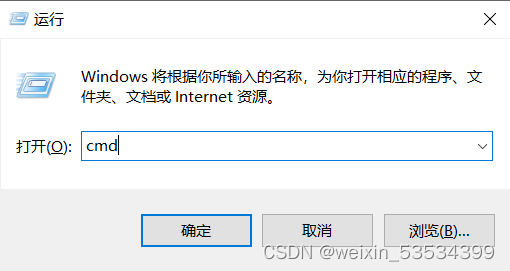
2. 快捷键win+R打开运行窗口,再输入cmd(注意不要直接运行),再快捷键ctrl+shift+enter以管理员身份运行。
同样以管理员身份进入命令提示符窗口,在命令行中输入一下命令,我这里以python3.10解释器为例,安装的环境命名为pytorch,这个环境名可以自定义。
conda create -name pytorch python=3.10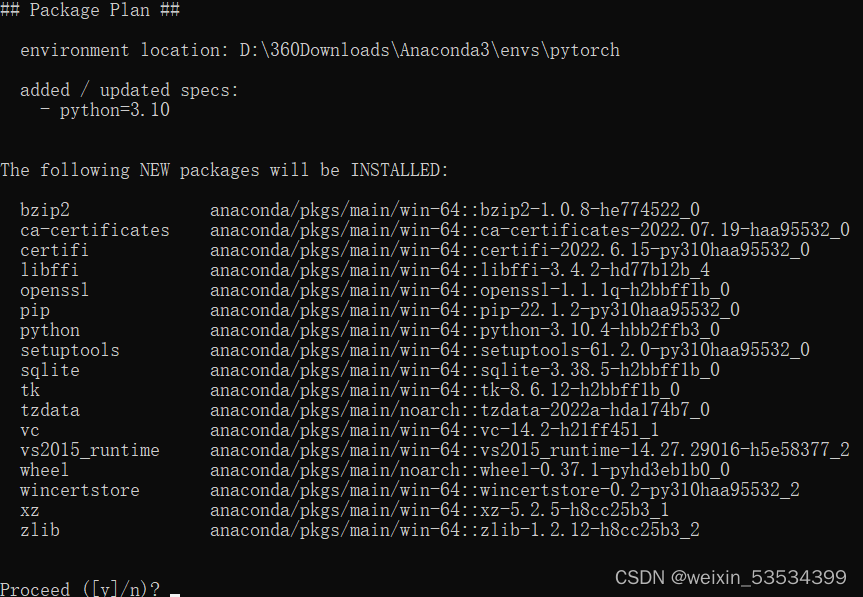
输入y,再回车。
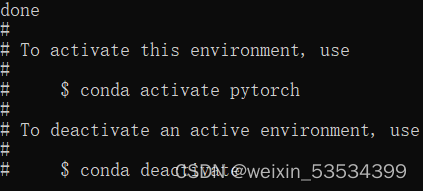
即完成了Pytorch的环境安装。我们可以利用以下命令激活pytorch环境。当前面出现(pytorch)前缀时,代表已经进入pytorch环境。
activate pytorch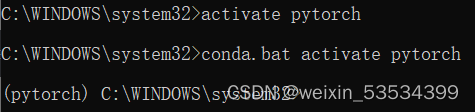
可能有些人会发现,自己创建的环境在自己自定义的安装的Anaconda路径的envs目录下没有找到,那么这个环境就是被安装到了C盘用户名目录下的.conda文件夹中的envs目录下了。
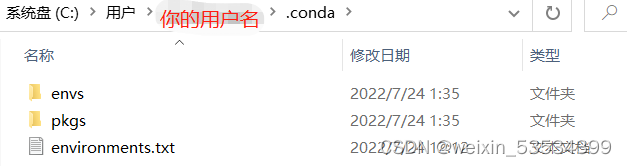
因为往往在环境中添加了包以后,环境文件夹会有好几个G,所以最好不要放在它默认的路径下。如果你不觉得麻烦,那么可以用一个比较笨的方法,就是每次新建完一个环境后,就把上图中的envs目录直接复制到你自己的Anaconda的安装目录中。另外还有一个(看似)高级一点的方法,就是找到上图中的.conda目录的同级目录下的一个叫做.condarc的文件,用记事本打开它。

在里面加上以下内容。
envs_dirs:
- D:\360Downloads\Anaconda3\envs
pkgs_dirs:
- D:\360Downloads\Anaconda3\pkgs这里是我的Anaconda的安装路径设置到了D:\360Downloads\Anaconda3下,大家可以将前面的部分改为自己的Anaconda的安装路径。这样子之后再创建的虚拟环境都会自动安装到这里自己定义的目录下。
另外我们可以通过以下命令来查看已建的环境
conda env list
其中base为Anaconda的默认环境,python310是我自己之前搭建的环境,pytorch就是现在搭建出来的pytorch环境。
我们可以在激活的pytorch环境下用以下命令查看一下新创建的环境中包含哪些包。
conda list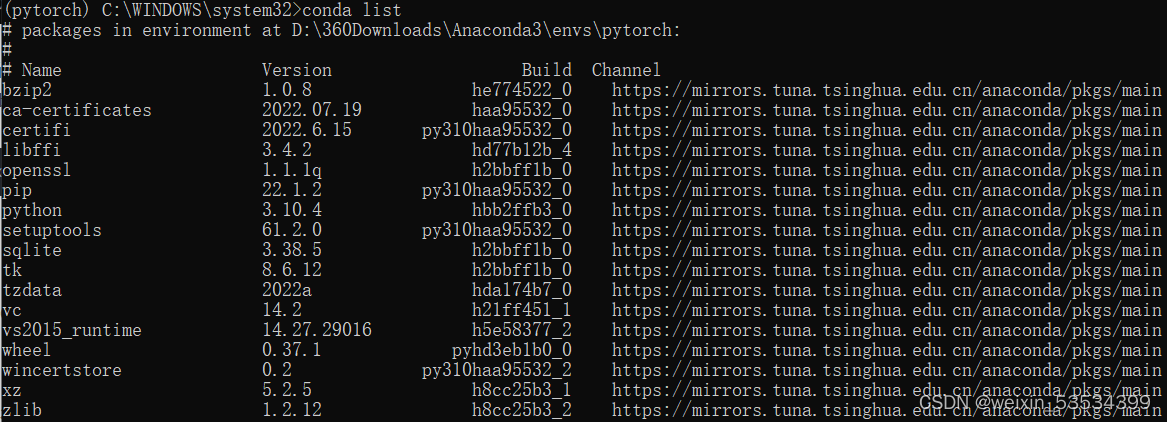
可以看到新建的环境中的包并不包含pytorch的相关包,需要我们手动安装。
这里主要说明安装GPU版的pytorch包。因为pytorch包需要与CUDA版本相匹配,所以需要根据自己机器的CUDA版本选择对应版本的pytorch包进行安装。根据上面利用nvidia-smi命令查找的本机CUDA版本,可以对应在PyTorch这里查找安装对应型号的pytorch包的命令。我上面查找的我的CUDA版本为11.7,那么我可以安装CUDA11.7以下的版本的pytorch包,这里我就选择11.6。
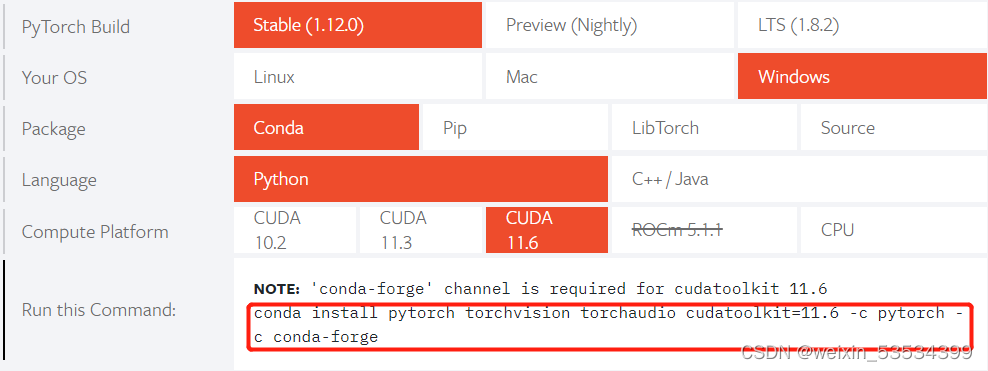
要在激活的pytorch环境下,复制以上方框中的命令开始下载安装包(注意必须要在pytorch环境中输入!!!否则会装到Anaconda的默认base环境中!!!)。其中-c pytorch中的c表示channel,即下载渠道,是国外的渠道,所以很有可能会出现安装非常缓慢的情况。那么我们就可以选择国内的镜像源来下载,我这里选用清华镜像源。具体操作有2种方式:
1. 在命令行输入
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
config --set show_channel_urls yes其中最后一句是在安装时可以显示安装的包的来源。
2. 同上述找到.condarc文件的位置,同样用记事本打开,在最上面加上以下内容加上以下内容
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- conda-forge这样就将清华镜像源加入到了路径中,之后安装包时,搜索渠道会先从该镜像源查找,速度会快很多。可以通过以下命令查看下载渠道和环境安装路径等信息。
conda info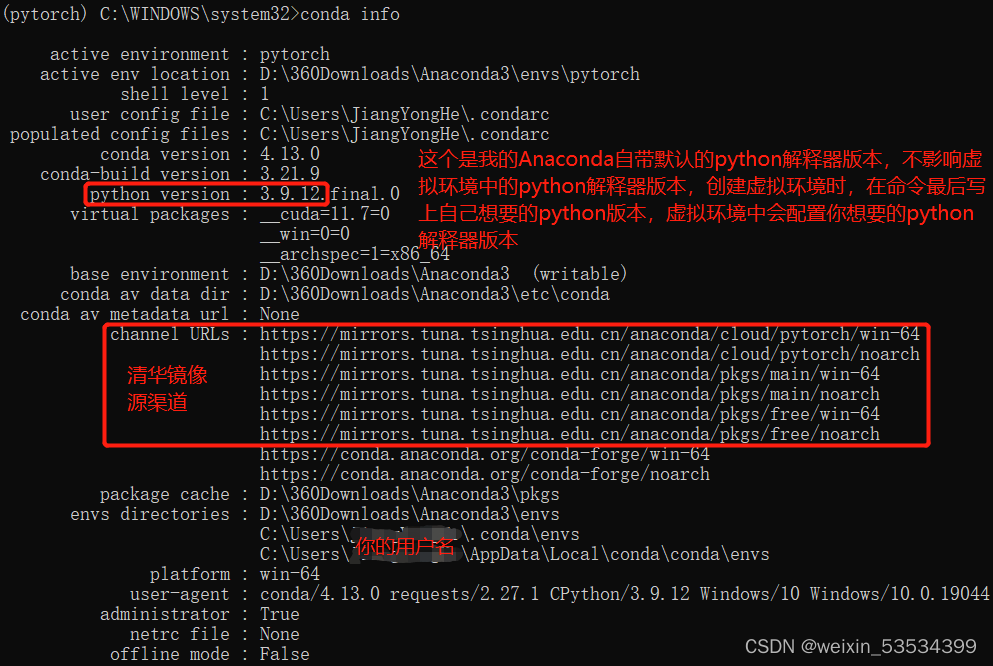
加入好这些渠道后,就可以用上述命令安装pytorch包了。首先同上述方法在激活的pytorch环境下输入前面的下载命令,但这时候就可以把-c pytorch即其之后的参数部分都删除掉了,即
conda install pytorch torchvision torchaudio cudatoolkit=11.6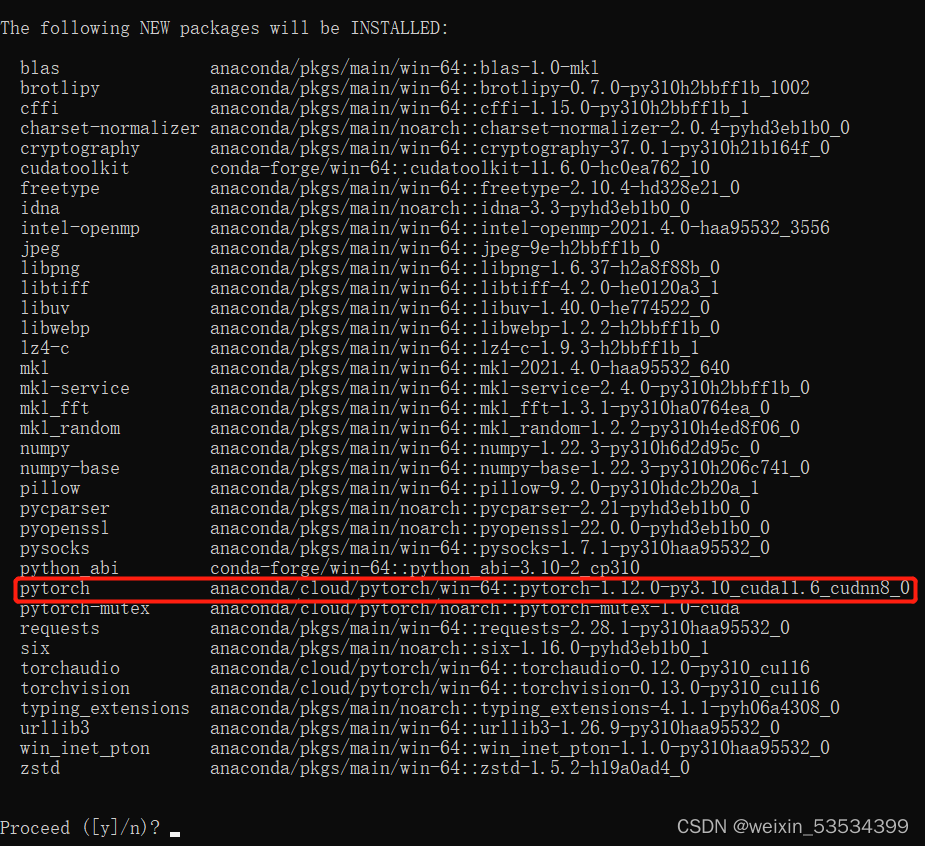
输入上面的命令回车后,会出现上面这个需要安装的包的列表,其中我们需要的pytorch包也在这里框出来了,右边对于这个包的版本说明的最后面的cuda11.6_cudnn8_0就表示下载的为GPU版本的pytorch包(CPU版本的在最后面会带有cpu的字样)。那么我们就可以输入y,然后回车等待下载了。如果中途安装的进度条卡主不动了,那可能是因为网络不太稳定,可以逐次按下快捷键Ctrl+C退出安装,然后输入上述命令重新安装
下载完成后,可以在pytorch环境下,同上述输入conda list命令查看安装好包后的所有包的列表。
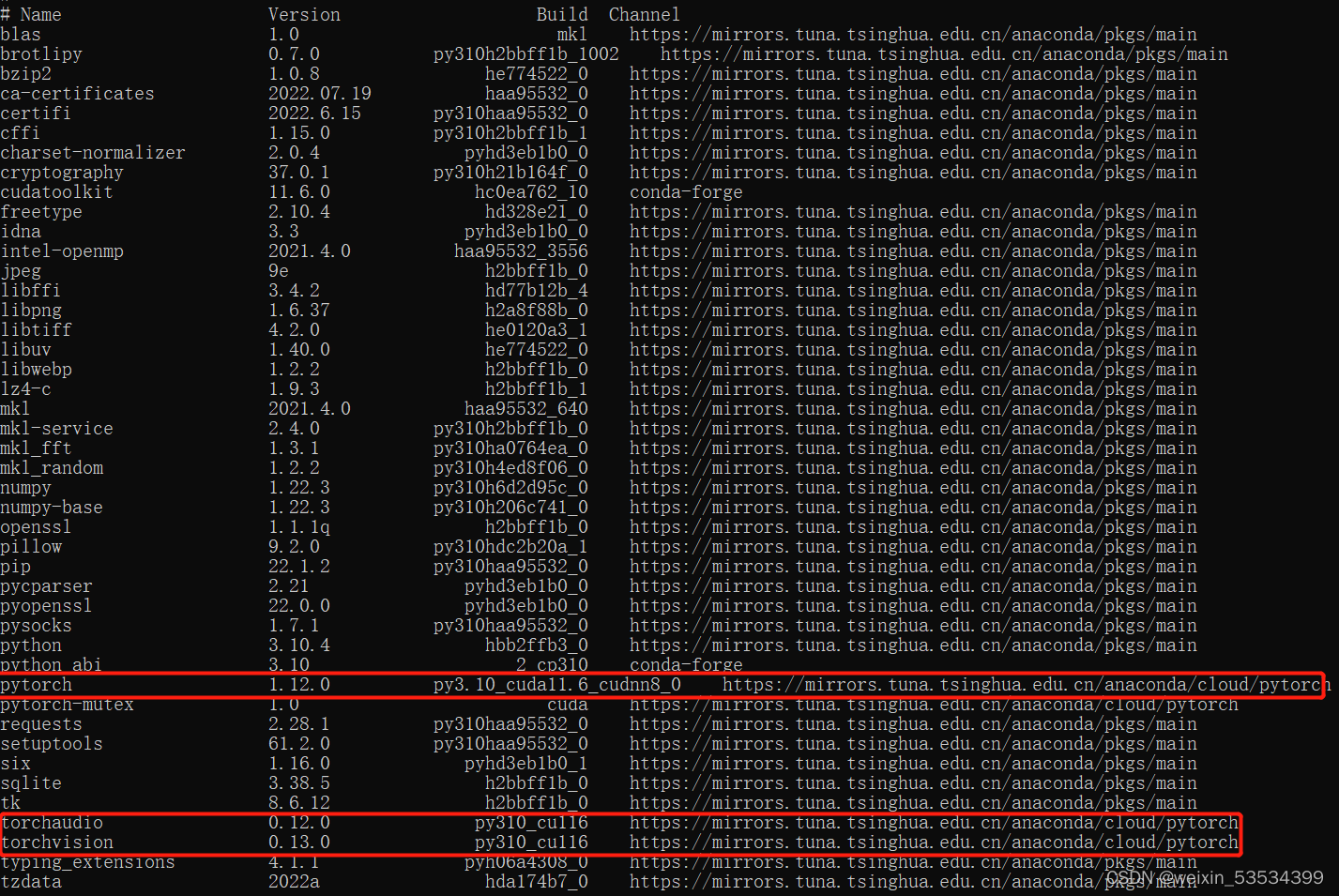
可以看到GPU版的pytorch和相关的包已经安装成功了 。
安装完pytorch包后,在pytorch环境下输入以下命令进入该环境下的python界面。
python
这里显示了python解释器版本为3.10.4,后面括号中的时间表示该版本的发行时间。(另外这里说明一下,当退出pytorch环境后,再次输入python命令结果如下)
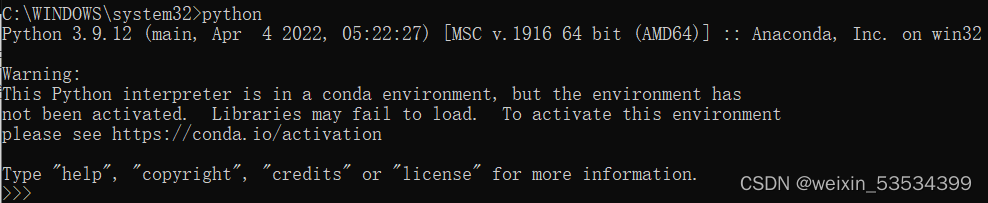
这里显示版本为3.9.12,这个为我安装的Anaconda的默认的base环境下的python解释器版本,但如果我们想要使用python其他版本的解释器,只需要像上面创建pytorch环境时指定python解释器版本即可,比如我这里就指定了器创建包含3.10版本的解释器的pytorch环境,同时在Pycharm中选择这个环境下的解释器,即可使用3.10版本的解释器,并且包含我们在这个环境下安装的包。另外上面的Waring警告只是表示说这个python命令没有在指定环境中执行,那么系统选择了默认的base环境的python解释器,如果想要去掉这个警告,那么只需要先输入activate命令先进入base环境,就不会再出现这个警告了,如下:

话题回到检验测试pytorch环境下的pytorch包的安装情况,可以先进入pytorch环境,并在环境下输入python命令进入python界面,再依次输入如下指令:
import torch
import torchvision
print(torch.cuda.is_available())
若均不报错,并且最后一个输出为True,则表示GPU版的pytorch包安装成功,pytorch环境搭建完成。则可以输入quit()退出python,输入deactivate指令退出环境。
NVIDIA图形驱动程序主要用来驱动NVIDIA显卡,让系统改正确识别NVIDIA的图形显示卡,可进行2D/3D渲染,发挥显卡应有的效能。
首先可以先看一下电脑是否具有独立显卡:进入设备管理器,找到
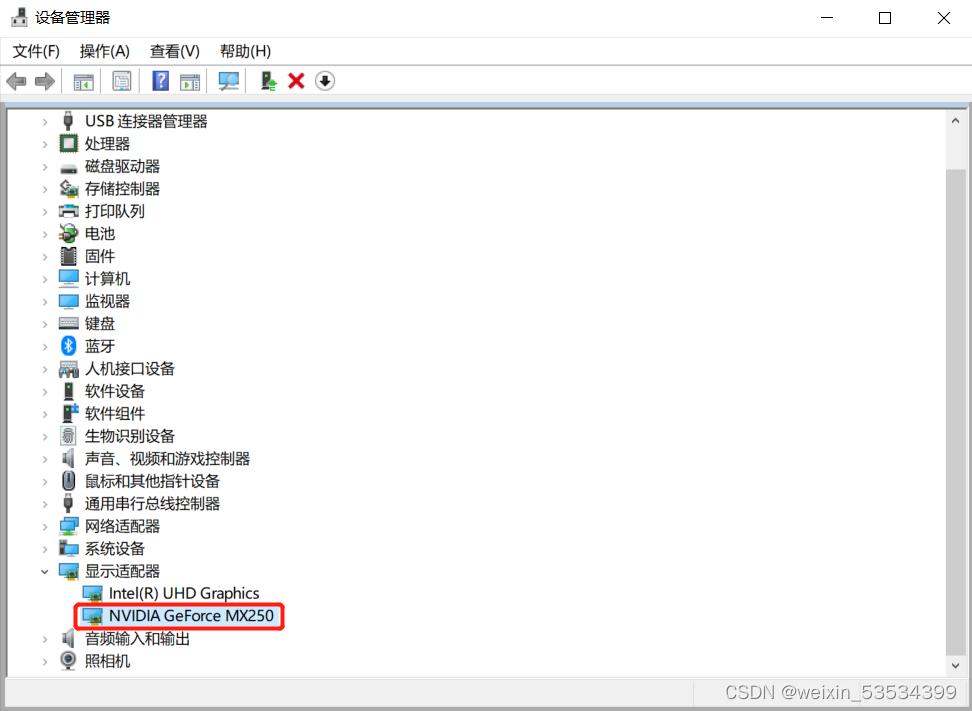
方框中的标识具有独立显卡。若没有,则需要到NVIDIA官网下载合适的NVIDIA驱动程序。 
然后点击搜索,然后之后两个页面全部点下载,即可开始下载。

然后找到安装文件
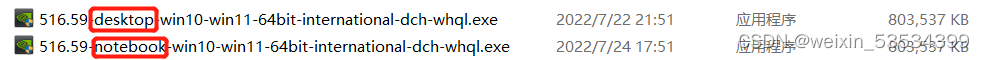
我下载了两种文件作对比,我上面操作下载的文件是下面的notebook版(笔记本版)的,而desktop版的是台式机版本的。
以笔记本版为例,以管理员身份运行下面那个exe文件,这是临时解压文件的路径,后续安装完成后悔删除,所以就直接按照默认路径即可,按ok。
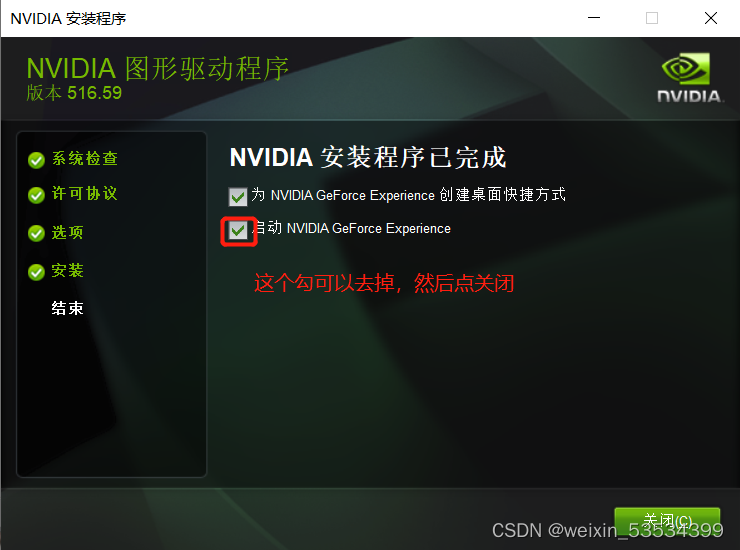
下载临时文件完成后,进入安装界面,然后一路按照默认选项按继续或下一步即可
然后,在桌面空白处右键,选择NVIDIA控制面板。

然后选择管理3D设置,再选择高性能NVIDIA处理器,点击应用即可。
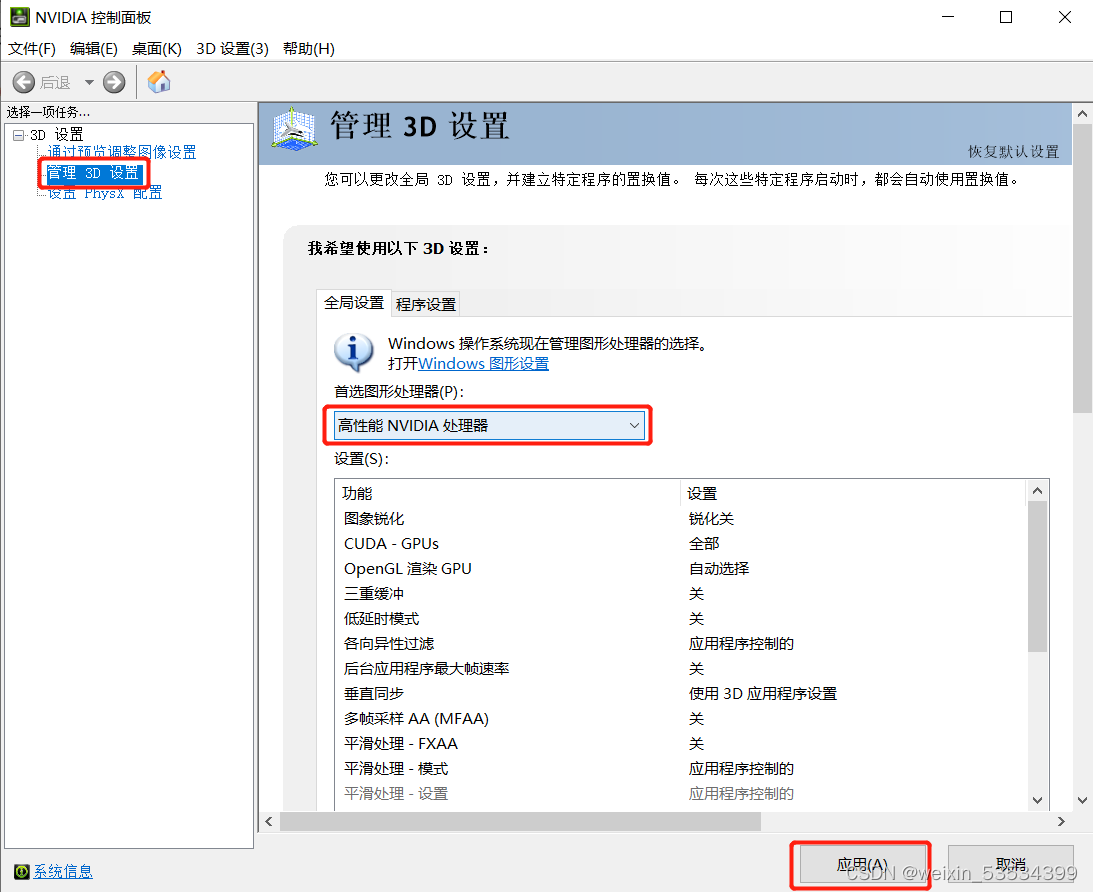
NVIDIV驱动程序安装完成,可以通过nvidia-smi命令查看本机CUDA版本。
以环境名为pytorch,对应python解释器版本3.10为例,以下在命令行中的conda指令归纳如下:
创建环境:
conda create -n pytorch python=3.10
conda create --name pytorch python=3.10
删除环境:
conda remove -n pytorch --all
激活环境:(对于base环境,可直接简写为activate)
activate pytorch
退出环境:
deactivate
下载 / 卸载包:
conda install package_name
conda remove package_name
查询环境中的所有包:
conda list
查询已搭建的环境:
conda env list
查询环境中的相关路径和下载渠道等信息:
conda info
打开python解释器:
python
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m