独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所以接下来介绍的是 YARN 平台上 Flink 是如何集成部署的。
整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配TaskManager 资源。
在 Flink1.8.0 之前的版本,想要以 YARN 模式部署 Flink 任务时,需要 Flink 是有 Hadoop 支持的。从 Flink 1.8 版本开始,不再提供基于 Hadoop 编译的安装包,若需要Hadoop 的环境支持,需要自行在官网下载 Hadoop 相关版本的组件flink-shaded-hadoop-2-uber-2.7.5-10.0.jar, 并将该组件上传至 Flink 的 lib 目录下。在 Flink 1.11.0 版本之后,增加了很多重要新特性,其中就包括增加了对Hadoop3.0.0 以及更高版本Hadoop 的支持,不再提供flink-shaded-hadoop-*jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
下载flink安装包:https://flink.apache.org/downloads.html
这里我选用的版本为:flink-1.13.6-bin-scala_2.12.tgz
下载kafka相关jar,为后续连接kafka做准备
https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.0.0/kafka-clients-2.0.0.jar
将安装包上传到/root/soft下载,进行解压操作
cd /root/soft
tar -zxf flink-1.13.6-bin-scala_2.12.tgz -C /data1/
为了方便区分将安装包改名
cd /data1/
mv flink-1.13.6/ flink-1.13.6-yarn
修改机器环境变量
vim /etc/profile
增加环境变量配置如下,这里必须保证设置了环境变量HADOOP_CLASSPATH:
# hadoop
export HADOOP_HOME=/usr/hdp/3.1.5.0-152/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export HADOOP_CLASSPATH=`hadoop classpath`
# flink
export FLINK_HOME=/data1/flink-1.13.6-yarn
export PATH=$PATH:$FLINK_HOME/bin
修改完使用以下命令生效
source /etc/profile
进入 conf 目录,修改 flink-conf.yaml 文件
cd $FLINK_HOME
vim conf/flink-conf.yaml
修改以下配置
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
参数意义如下
| 参数 | 介绍 |
|---|---|
| jobmanager.memory.process.size | 对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。 |
| taskmanager.memory.process.size | 对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。 |
| taskmanager.numberOfTaskSlots | 对每个 TaskManager 能够分配的 Slot 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓Slot 就是TaskManager 中具体运行一个任务所分配的计算资源。 |
| parallelism.default | Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。 |
为了后续使用flink连接kafka时不出现问题,这里将额外下载的jar包上传到lib目录
cd /root/soft
cp flink-connector-kafka_2.12-1.13.6.jar kafka-clients-2.0.0.jar $FLINK_HOME/lib
正常基于 Yarn 提交 Flink 程序,无论是使用 yarn-session 模式还是 yarn-cluster 模 式 , 基 于 yarn 运 行 后 的 application 只 要 kill 掉 对 应 的 Flink 集 群 进 程 “YarnSessionClusterEntrypoint”后,基于 Yarn 的 Flink 任务就失败了,不会自动进行重试,所以基于 Yarn 运行 Flink 任务,也有必要搭建 HA,同样还是需要借助 zookeeper 来完成高可用管理。
Flink on Yarn的HA高可用模式,首先依赖于Yarn自身的高可用机制(ResourceManager高可用),并通过Yarn对JobManager进行管理,当JobManager失效时,Yarn将重新启动JobManager。其次Flink Job在恢复时,需要依赖Checkpoint进行恢复,而Checkpoint的快照依赖于远端的存储:HDFS,所以HDFS也必须是高可用,同时JobManager的元数据信息也依赖于HDFS的高可用(namenode的高可用,和多副本机制),再者JobManager元数据的指针信息要依赖于Zookeeper的高可用。
YARN 模式的高可用和独立模式(Standalone)的高可用原理不一样。Standalone 模式中, 同时启动多个 JobManager, 一个为leader,其他为standby,当 leader 挂了, 其他的才会有一个成为 leader。而 YARN 的高可用是只启动一个 Jobmanager,当这个 Jobmanager 挂了之后,YARN 会再次启动一个,所以其实是利用的 YARN 的重试次数来实现的高可用。
请注意,在YARN上部署时,Flink管理high-availability.cluster-id配置参数。Flink默认将其设置为YARN应用程序的ID。在YARN上部署HA集群时,你不应该覆盖这个参数。集群ID是用来区分HA后端(例如Zookeeper)的多个HA集群的。覆盖这个配置参数会导致多个YARN集群相互影响。
Flink on YARN是针对Hadoop 2.4.1编译的,所有Hadoop版本>=2.4.1都被支持,包括Hadoop 3.x。
YARN负责重启失败的JobManagers。JobManager的最大重启次数是通过两个配置参数定义的。首先Flink的yarn.application-attempts配置将默认为2。这个值由YARN的yarn.resourcemanager.am.max-attempts限制,它的默认值也是2。
修改yarn 中配置(yarn-site.xml)设置application master重启时,尝试的最大次数。
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
修改flink-conf.yaml配置文件,添加修改以下内容
# 单个flink job重启次数 必须小于等于yarn-site.xml中Application Master配置的尝试次数(yarn.resourcemanager.am.max-attempts)
yarn.application-attempts: 3
# 高可用模式
high-availability: zookeeper
# JobManager元数据保留在文件系统storageDir中,指向此状态的指针存储在ZooKeeper中
high-availability.storageDir: hdfs://mycluster/flink/yarn/ha
# Zookeeper集群,修改为自己的集群
high-availability.zookeeper.quorum: n11hdp01:2181,n12hdp02:2181,n13hdp03:2181
# 在zookeeper下的根目录
high-availability.zookeeper.path.root: /flink-yarn
注意:对于未启动高可用之前启动job 需要在配置完高可用后重启job
测试 flink on yarn 下per job
flink run -d -t yarn-per-job $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
查看hdfs目录,可以看到flink on yarn的 ha checkpoint目录已创建

查看flink webui日志,可以看到已选取leader
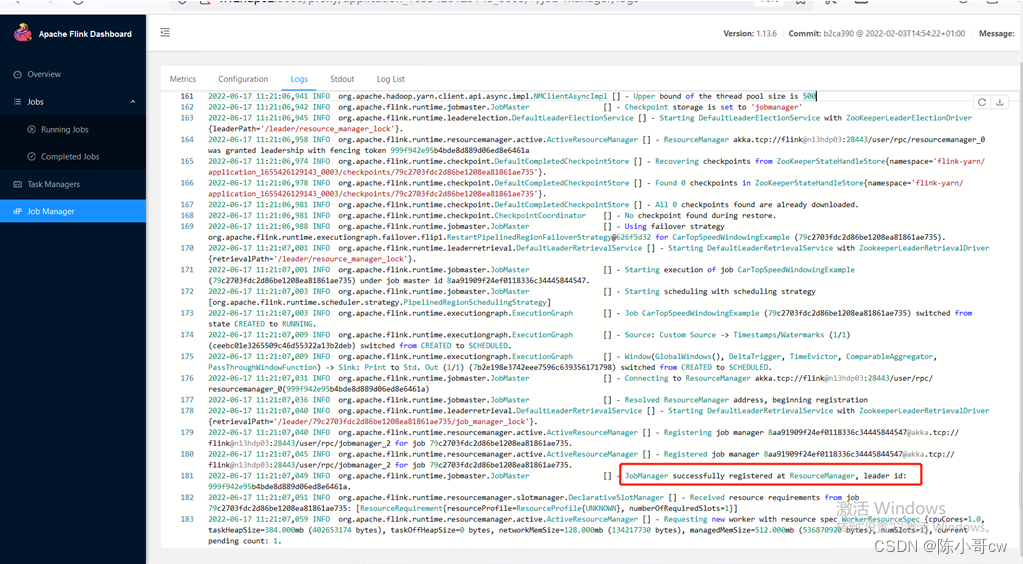
Jps获取YarnJobClusterEntrypoint 的进程,然后杀掉此进程

这时再访问job的web ui界面可以看到以下信息,这个代表正常选举leader,jobmanager正在重启

等待一会可以发现web ui界面正常显示,日志显示启动了一个新的leader
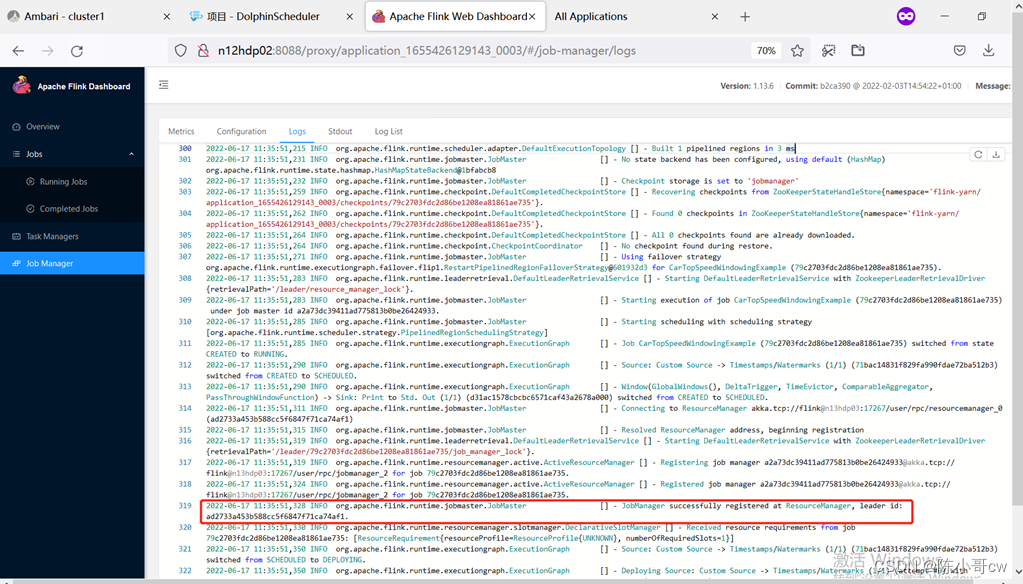
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session) 来启动 Flink 集群。
执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
yarn-session.sh -nm test
可用参数解读:
-d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session 也可以后台运行。-jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。-nm(--name):配置在 YARN UI 界面上显示的任务名。-qu(--queue):指定 YARN 队列名。-tm(--taskManager):配置每个 TaskManager 所使用内存。注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量, YARN 会按照需求动态分配TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个web UI 地址以及一个 YARN application ID,如下所示,用户可以通过web UI 或者命令行两种方式提交作业。
2022-06-14 17:21:43,152 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2022-06-14 17:21:43,153 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface n13hdp03:19264 of application 'application_1653635374037_0023'.
JobManager Web Interface: http://n13hdp03:19264
可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的Application ID。
执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
flink run $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
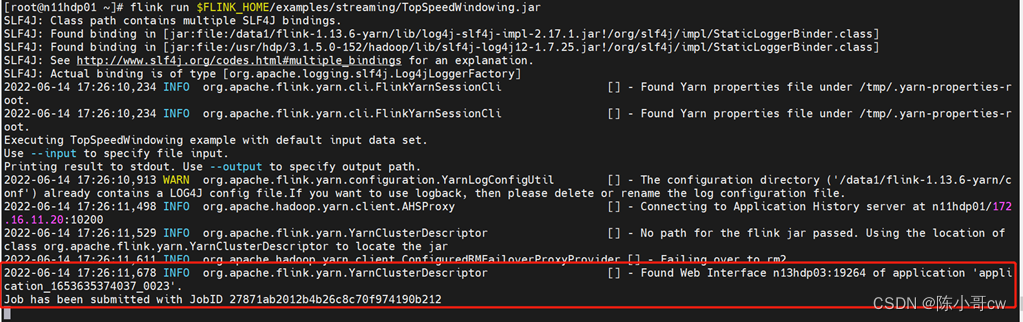
客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
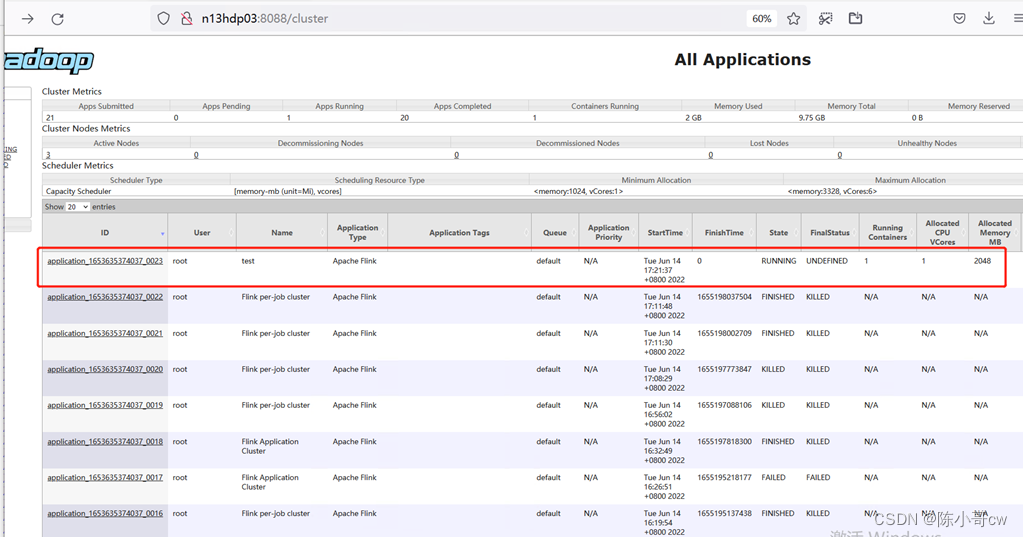
任务提交成功后,可在 YARN 的Web UI 界面查看运行情况。
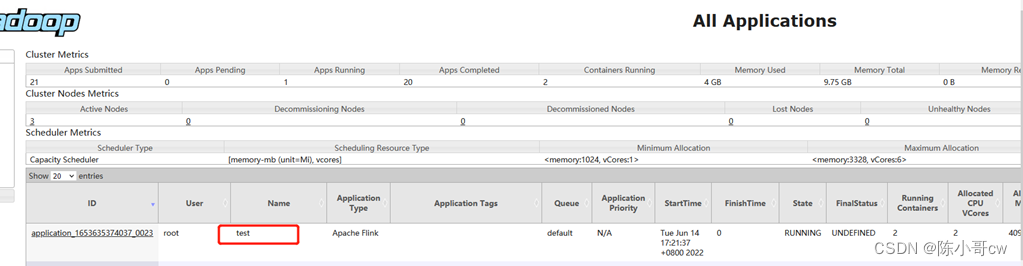
从图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的Application ID。
也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况
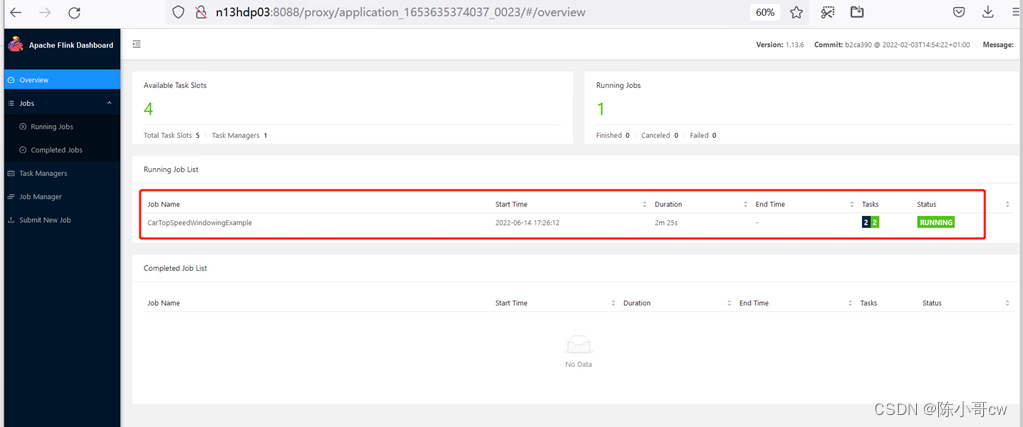
此时再次提交一个任务
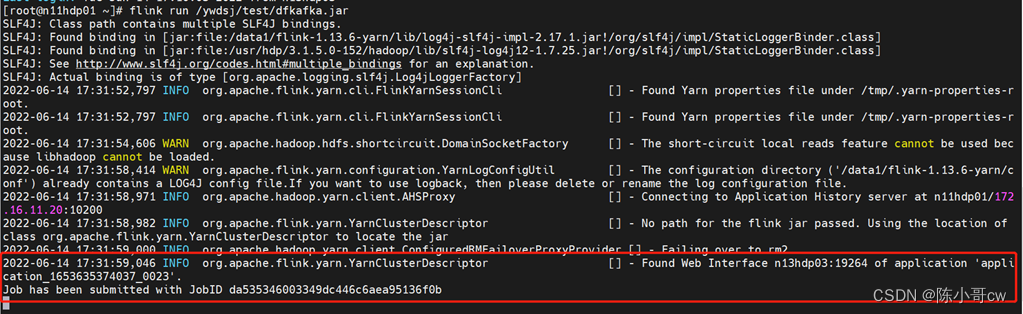
flink run /ywdsj/test/dfkafka.jar
任务提交成功后,可在 YARN 的Web UI 界面查看运行情况。
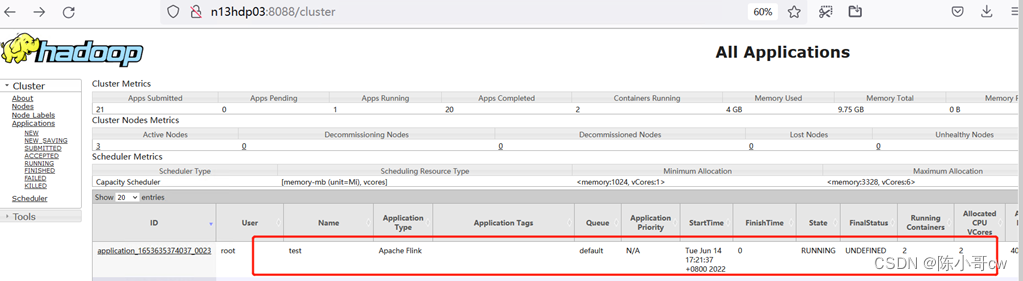
从图中可以看到我们提交的任务仍然是提交到 Yarn-Session上,这时 Flink 的 Web UI 页面可以看到有两个running job了
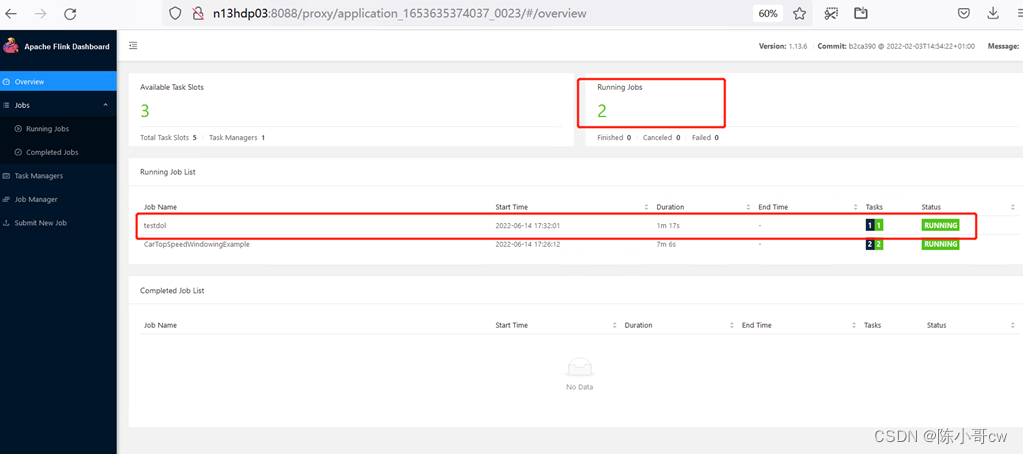
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群。
Per-job Cluster模式将在YARN上启动一个Flink集群,然后运行本地提供的应用程序jar包,最后将JobGraph提交给YARN上的JobManager。如果你传递了–detached参数,一旦提交被接受,客户端将停止。
执行命令提交作业
flink run -d -t yarn-per-job $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
早期版本也有另一种写法:
flink run -m yarn-cluster $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
注意这里是通过参数-m yarn-cluster指定向 YARN 集群提交任务。
在 YARN 的ResourceManager 界面查看执行情况,如图所示。
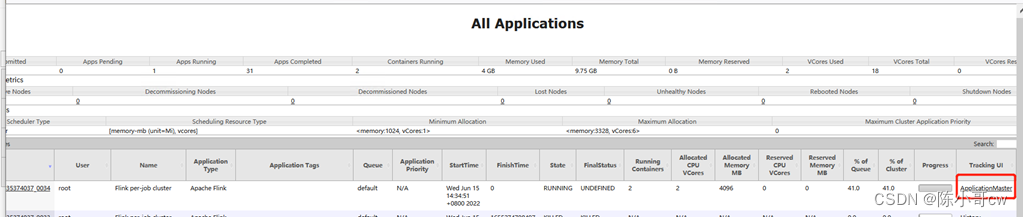
点击可以打开 Flink Web UI 页面进行监控
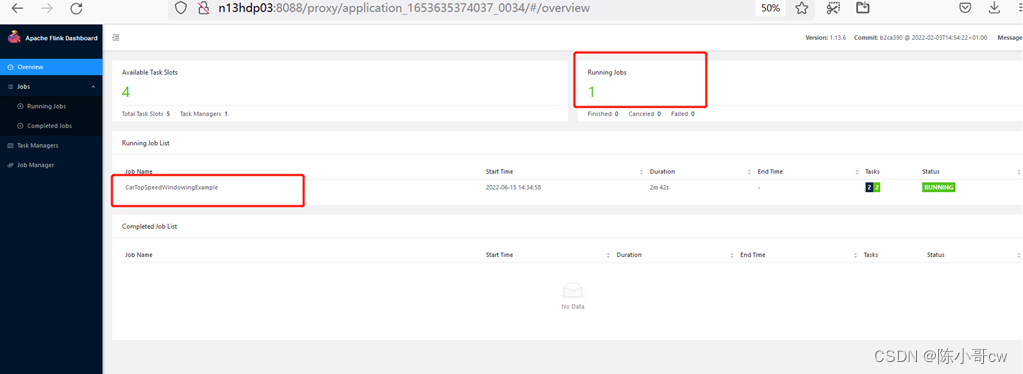
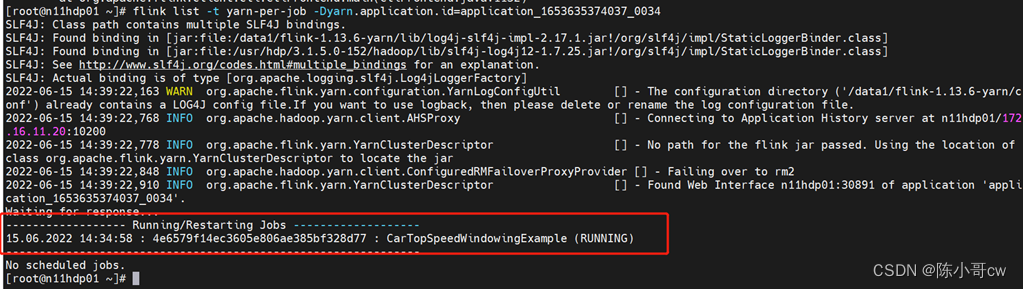
可以使用命令行查看作业
flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
取消作业
flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的 application_XXXX_YY 是当前应用的 ID,<jobId>是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉。
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可。
flink run-application -t yarn-application $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
在命令行中查看或取消作业
flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
也可以通过yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程
flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://mycluster/my-remote-flink-dist-dir" hdfs://mycluster/jars/my-application.jar
这种方式下 jar 可以预先上传到 HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答