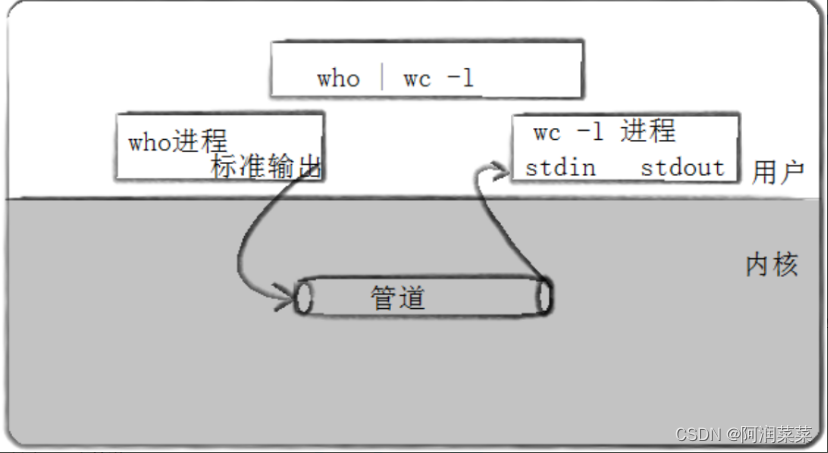
其实管道通信是Unix中最古老的进程间通信的形式了:
管道通信是一种进程间通信的方式,它可以让一个进程的输出作为另一个进程的输入,实现数据的传输、资源的共享、事件的通知和进程的控制。
管道通信分为两种类型:匿名管道和命名管道。
匿名管道是只能在父子进程间使用的,它通过pipe()函数创建,并返回两个文件描述符,一个用于读,一个用于写。
命名管道是可以在任意进程间使用的,它通过mkfifo()或mknod()函数创建一个特殊的文件,然后通过open()函数打开,并返回一个文件描述符,用于读或写。
管道通信的特点是面向字节流、占用内存空间、只能单向传输、有固定的大小和缓冲区等。
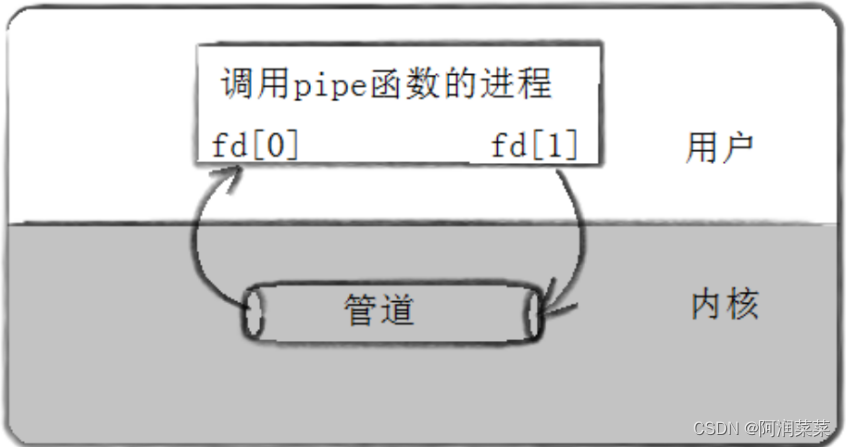
pipe()函数是用来创建一个匿名管道的,它的原型是:
#include <unistd.h>
int pipe(int pipefd[2]); // 返回值:若成功返回0,失败返回-1
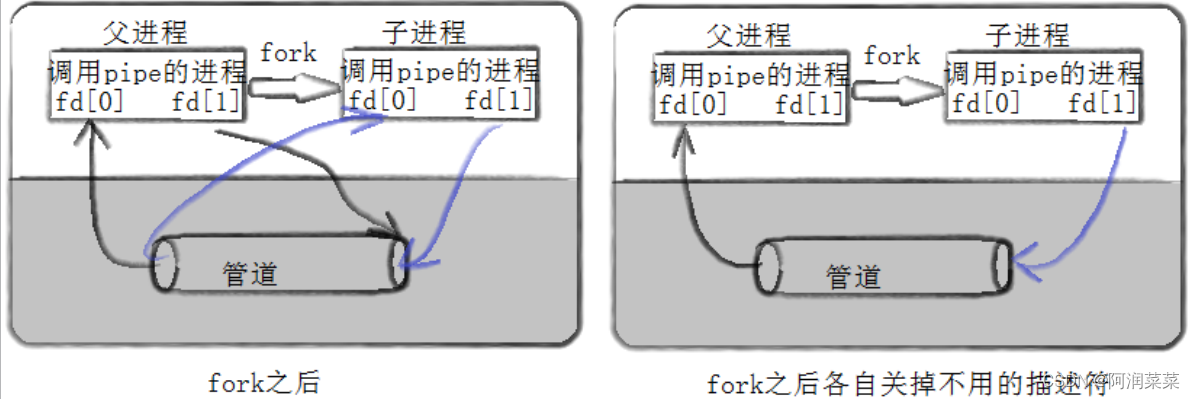
pipe()函数会返回两个文件描述符,pipefd[0]用于读取管道中的数据,pipefd[1]用于向管道中写入数据。匿名管道只能在具有亲缘关系的进程间通信,通常是父子进程或兄弟进程。
mkfifo()函数是用来创建一个命名管道的,它的原型是:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode); // 返回值:成功返回0,出错返回-1
mkfifo()函数会在文件系统中创建一个特殊的文件,该文件用于提供FIFO功能,即命名管道。命名管道可以在无关的进程间通信,只要知道它的路径名。命名管道需要用open()函数打开,并返回一个文件描述符,用于读或写。
pipe()函数和mkfifo()函数的区别主要有以下几点:
管道通信的本质是利用内核提供的一块缓存区来实现不同进程间的数据传输、资源共享、事件通知和进程控制。
管道通信分为匿名管道和命名管道,它们都是一种特殊的文件,可以用普通的文件I/O函数进行操作。
1.匿名管道是通过pipe()函数创建并返回两个文件描述符,一个用于读,一个用于写。匿名管道只能在具有亲缘关系的进程间通信,通常是父子进程或兄弟进程。
2.命名管道是通过mkfifo()函数或mknod()函数创建一个特殊的文件,并通过open()函数打开并返回一个文件描述符,用于读或写。命名管道可以在任意进程间通信,只要知道它的路径名。
3.无论是匿名管道还是命名管道,它们都使用了环形缓冲区来存储数据。环形缓冲区是由16个内存页成的,每个内存页有一个pipe_buffer对象来管理。环形缓冲区有一个读指针和一个写指针来记录读写操作的位置。
4.当向管道写入数据时,从写指针指向的位置开始写入,并且将写指针向前移动。而从管道读取数据时,从读指针开始读入,并且将读指针向前移动。当对没有数据可读的管道进行读操作,或者对没有空闲空间的管道进行写操作时,会阻塞当前进程,除非设置了非阻塞标志(O_NONBLOCK)。
一般步骤如下:
一个示例代码:
// 父进程向子进程发送字符串
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
#define BUFSIZ 1024
int main()
{
int pipefd[2]; // 管道文件描述符
char buf[BUFSIZ]; // 缓冲区
char *msg = STRING; // 消息
// 创建匿名管道
if (pipe(pipefd) == -1)
{
perror("pipe()");
exit(1);
}
// 创建子进程
pid_t pid = fork();
if (pid == 0) // 子进程
{
close(pipefd[1]); // 关闭管道写端
if (read(pipefd[0], buf, BUFSIZ) < 0) // 从管道读端读取数据
{
perror("read()");
exit(1);
}
printf("%s\n", buf); // 打印数据
exit(0);
}
else // 父进程
{
close(pipefd[0]); // 关闭管道读端
if (write(pipefd[1], msg, strlen(msg)) < 0) // 向管道写端写入数据
{
perror("write()");
exit(1);
}
wait(NULL); // 等待子进程结束
//wait(NULL)函数会暂停当前进程的执行,直到有一个子进程终止或发生信号
}
return 0;
}
必须在创建子进程之前创建匿名管道才能实现父子进程通信吗?为什么?
必须的!
必须在创建子进程之前创建匿名管道的原因有以下几点:
一般步骤如下:
这里再次理解一下进程阻塞:
代码:
// 服务器进程向客户端进程发送字符串
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FIFO_NAME "testfifo" // 命名管道路径名
#define STRING "hello world!" // 消息
int main()
{
int pipefd; // 管道文件描述符
char *msg = STRING; // 消息
// 创建命名管道
if (mkfifo(FIFO_NAME, 0666) == -1)
{
perror("mkfifo()");
exit(1);
}
// 打开命名管道
pipefd = open(FIFO_NAME, O_WRONLY);
if (pipefd == -1)
{
perror("open()");
exit(1);
}
// 向命名管道写入数据
if (write(pipefd, msg, strlen(msg)) < 0)
{
perror("write()");
exit(1);
}
// 关闭命名管道
close(pipefd);
return 0;
}
命名管道通信的大概原理如下:
大志原理代码示例如下: 具体看我的代码仓库中的代码示例
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define MAX 1024
int main()
{
if (mkfifo("./fifo", 0644) < 0) //创建命名管道,并判断是否创建成功
{
perror("mkfifo error!\n");
return 1;
}
int fd = open("./fifo", O_RDONLY); //让./fifo以只读方式打开
if (fd < 0)
{
perror("read error!\n");
return 2;
}
char buf[MAX];
while (1)
{
buf[0] = 0;
printf("Please wait...\n");
ssize_t s = read(fd, buf, sizeof(buf) - 1); //从管道中读取数据
if (s > 0) //读取成功
{
buf[s - 1] = 0;
printf("client# %s\n", buf);
}
else if (s == 0)
{
printf("client quit,server quit too!\n");
break;
}
else
{
perror("read");
}
}
close(fd); //关闭读端
return 0;
}
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define MAX 1024
int main()
{
int fd = open("./fifo", O_WRONLY); //把./fifo文件以只写方式打开
if (fd < 0)
{
perror("read");
return 1;
}
char buf[MAX];
while (1)
{
buf[0] = 0;
printf("Please Enter:> ");
scanf("%s", buf);
write(fd, buf, strlen(buf)); //往管道里面写入数据
}
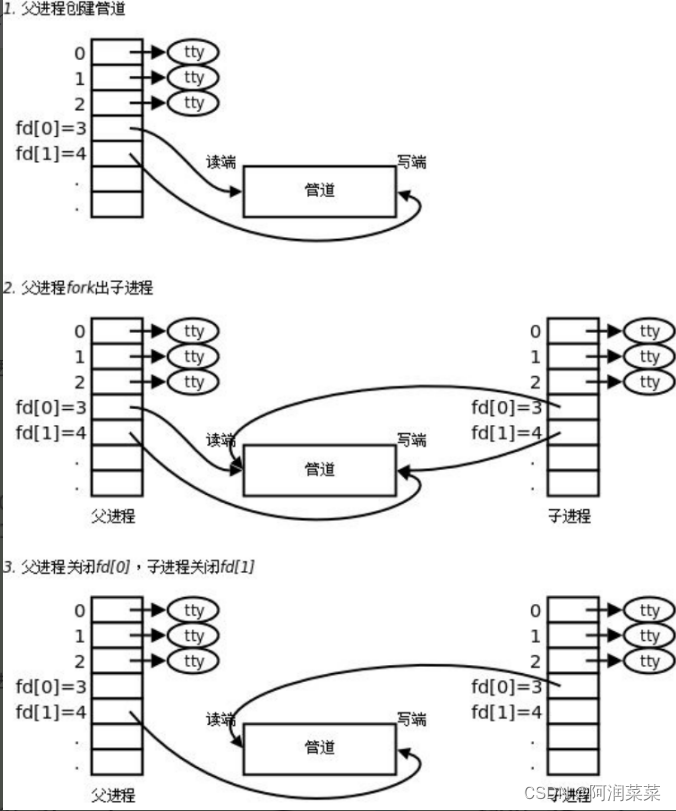
我们知道文件描述符是一个数字,用来表示进程打开的文件。每个进程都有一个文件描述符表,用来存储文件描述符和对应的文件指针。
管道是一种利用内核缓冲区实现进程间通信的方法,它可以让一个进程的输出作为另一个进程的输入,实现数据的单向传输。
管道由pipe()系统调用创建,返回两个文件描述符,分别代表管道的读端和写端。通常,一个进程创建管道后,再fork出一个子进程,然后父子进程分别关闭不需要的管道端,建立通信连接
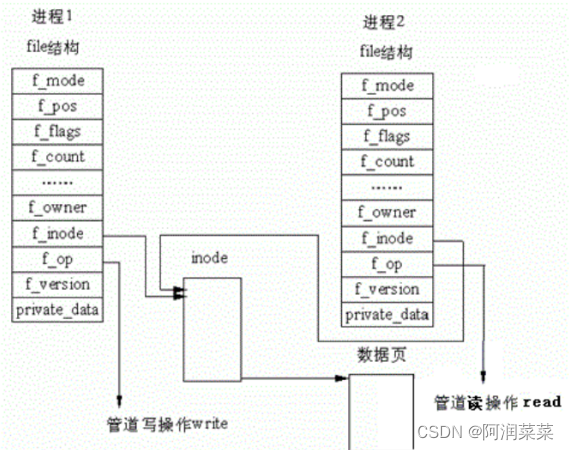
Again:管道通信是一种利用内核缓冲区实现进程间通信的方法,它可以让一个进程的输出作为另一个进程的输入,实现数据的单向传输。
所以,看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”!
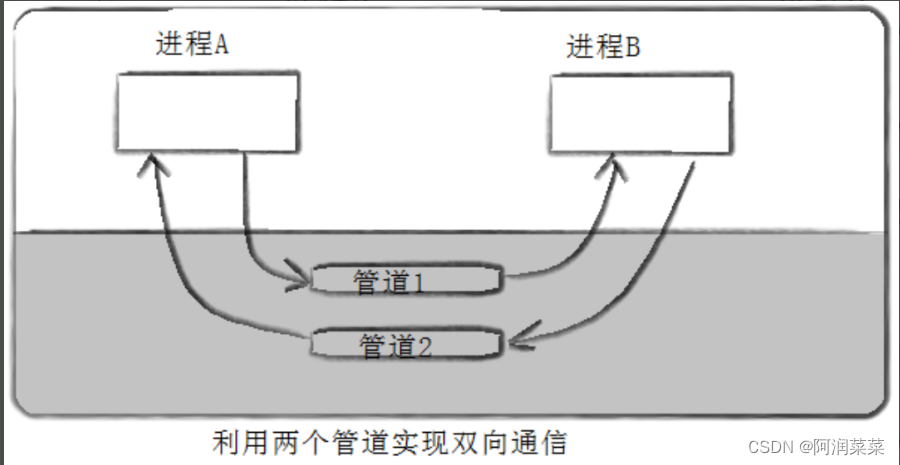
管道通信的优点有以下几点:
管道通信的缺点有以下几点:
改进管道通信性能和效率的方法有以下几点:

我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
在尝试实现应用auto_orient的过程之后!对于我的图片,我收到此错误:ArgumentError(noimagesinthisimagelist):app/uploaders/image_uploader.rb:36:in`fix_exif_rotation'app/controllers/posts_controller.rb:12:in`create'Carrierwave在没有进程的情况下工作正常,但在添加进程后尝试上传图像时抛出错误。流程如下:process:fix_exif_rotationdeffix_exif_rotationmanipulate!do|image|