今天的内容是哈希的应用:位图和布隆过滤器
目录
今天的内容从一道面试题开始引入:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在 这40亿个数中。 首先我们对40亿个无符号整数改变一下,它到底是多少G呢? 40亿个整数大概是 40亿*4个字节=160亿个字节 4G=2^32byte,大概为42亿九千万字节,所以1G大概就是10亿字节 ,所以40亿个整数大概就是16G,那这么大数据放到内存中肯定是放不下的,所以什么二分查找,什么map,set更何况还有额外的消耗,这更不可能完成了,于是我们可以利用哈希的思想来搞一个位图! 判断数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0 代表不存在。 位图是一种直接定址法的哈希,因此效率很高,用O(1)就可以探测到对应位是0还是1,效率非常高,因此可以快速判断。
利用每一个比特位的0或1的情况,来判断数在不在,所以40亿不重复的数,开辟2^32-1个比特位,转化为G,也就512m,内存很小。
举例说明:
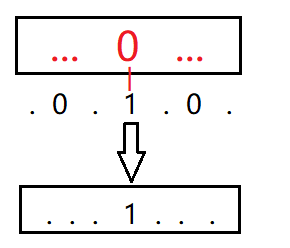
每个数我们可以先num/8,算出他在第几个char里,然后再num%8算出在哪一位
比如:23/8=2,在第二个char;23%8=7,在第七位上面。那如何把任意一位置1,且不改变其他位?
把它和左移(向高位移动)以后的1(即其他位是0,只有要改变那一位是1)和原来的数进行或运算,就可以得到结果。保证了其他位不变,只有该位被改变为了1.
那到底怎么移动呢?
(一个char中)
那可能有人就会想,这会不会跟大小端有关系,数据在内存中的存储形式???
错错错,大错特错,首先大小端只存在于大于1字节的数据类型中,其次不管从哪边移动,本质是向高位或者低位移动。
所以说,%8以后,是哪一位,1直接左移几位(即向高位移动)。
那么在把某一位置为1以后,要重新置为0的话,应该怎么搞呢?
同理得:直接将1移位以后,再取反,将结果和原数进行与运算。
那要测试这个数在不在位图中,怎么测试呢?也就是看某一位是不是1
直接返回 1移位以后和原数相与的结果,不为0则存在,为0则不存在。
我们来看代码实现:
template<size_t N> class bitset { public: bitset() { //_bit.resize((N/8) + 1, 0); _bit.resize((N >> 3) + 1, 0);//左移3位就相当于/8,效率更快一些,但要注意运算符的优先级 } void set(size_t x) { size_t i = x >> 3; size_t j = x % 8; _bit[i] |= (1 << j);//在知道是哪一个char之后,直接把这一个char相与。 } void reset(size_t x) { size_t i = x >> 3; size_t j = x % 8; _bit[i] &= (~(1 << j)); } bool test(size_t x) { size_t i = x >> 3; size_t j = x % 8; return _bit[i] & (1 << j); } private: vector<char> _bit; };

template<size_t n>
class two_bitset
{
public:
void set(size_t x)
{
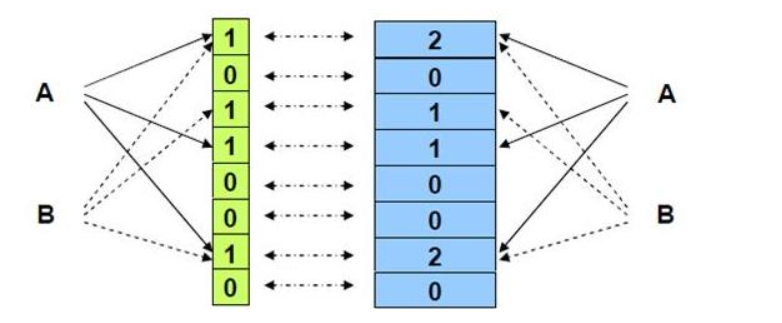
if (!_bs1.test(x) && !_bs2.test(x))//00
{
_bs2.set(x); //0次变1次
}
else if (!_bs1.test(x) && _bs2.test(x))//01
{
_bs1.set(x);
_bs2.reset(x);//1次变两次
}
}
void printonce()
{
for (size_t i = 0; i < n; ++i)
{
if (!_bs1.test(i) && _bs2.test(i))
{
cout << i << endl;
}
}
cout << endl;
}
private:
bitset<n> _bs1;
bitset<n> _bs2;
};
一个数如果在两个位图中的同一位置都是0,那么说明就是0次 ,再进来的数就要将00第二位set为01,表示出现一次,后面同理可得。
还是一道面试题来引入哈希切分:
直接哈希切分!! 
我们可以对100G大文件中的ip进行哈希切分,利用哈希表的思想,将哈希值相同的放入同一个小文件中,然后通过一个一个的小文件进入内存读取并统计个数,搞完一个clear掉,记录再进下一个。
理想很美好,现实却有点骨感?
单个文件超过1G:
因为存在哈希冲突,在数据进入小文件时,就会产生下面两种情况:
1.一个小文件中,差不多都是不重复的数据,且个数还挺多,且map再加额外开销,导致内存很大,直接报错。
2.一个小文件中,都是很多重复的数据,且个数还挺多,但是map却可以存下(重复的只增加次数),可以统计。
所以我们无需判断是哪种情况,直接无脑map,第一种情况发生就抛异常,捕获以后,换另一种哈希函数,再进行递归分割,拆成更小的文件后用map统计次数。
你懂了吗?
开始讲布隆过滤器之前,我们要说一说位图的缺点是什么?
最大的缺点就是:1.开空间得看数据范围,一般要求范围集中,分散的话空间消耗就会上升
2.只能针对整型
如果给了一堆字符串,可不可以使用位图判断是否存在呢?
当然可以,可以使用哈希函数,将字符串转化为整型,再去映射到位图中。
当针对字符串来判断是否存在时,位图+哈希其实就是我们要讲的布隆过滤器。
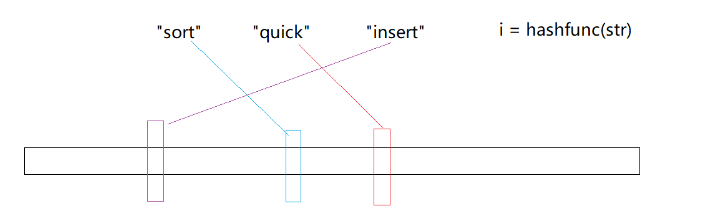
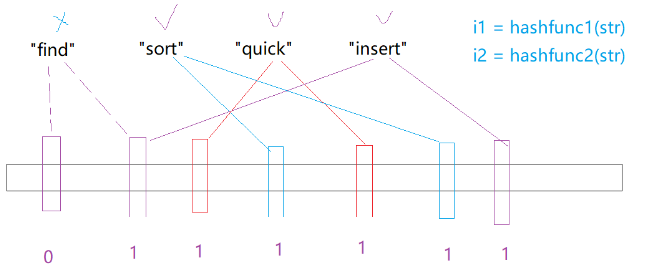
当不同的字符串通过哈希函数转化为整型映射到位图中时,就会发生哈希碰撞! 比如find通过哈希函数可能和insert映射到同一位置,那么当find不存在时,但是他的位置的确已经被置为1,所以这就导致了: 判断存在是不准确的 判断不存在一定是准确的,因为位置是0,那一定不存在 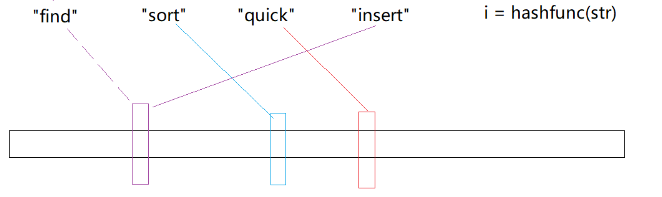
于是,我们就要想一些办法,让他的误判率低一些:
可以增加不同的哈希函数,转化为不同的哈希值,去映射到多个位置,降低误判率
这样的话,我们可以看到,只有当一个字符串映射的全部位置都置为1时,这个数才可能存在,说的是可能存在,因为也可能存在哈希碰撞。但降低了哈希碰撞的概率,降低了误判率。
那还有问题就是:一个字符串映射多个位图的位置,那位图应该开多大呢?
或者说如何选择哈希函数个数和布隆过滤器长度?
直接上大佬:大佬研究出来的一个公式:
现在来实现布隆过滤器:
template<
size_t N,
size_t M,
class K = string,
class Hash1= BKDRHash,
class Hash2= APHash,
class Hash3 = DJBHash>
class Bloomfilter
{
public:
void set(const K& key)
{
size_t i = Hash1()(key) % (N * M);
size_t j = Hash2()(key) % (N * M);
size_t k = Hash3()(key) % (N * M);
_bs.set(i);
_bs.set(j);
_bs.set(k);
}
//void reset() 没有reset的原因是:因为存在哈希冲突,修改一个数的哈希值映射位置的值,会影响到其他的数,导致结果不准确。
//硬要有reset,就需要计数,通过计数(--)来控制,那就需要成倍的位图来表示个数,严重浪费内存空间。
//布隆过滤器,存在哈希冲突,所以确定不了一定存在的值
//但是可以确定一定不存在的值
bool test(const K& key)
{
size_t i = Hash1()(key) % (N * M);
if (!_bs.test(i))
{
return false;
}
size_t j = Hash2()(key) % (N * M);
if (!_bs.test(j))
{
return false;
}
size_t k = Hash3()(key) % (N * M);
if (!_bs.test(k))
{
return false;
}
//到这里说明可能存在
return true;
}
private:
bitset <N* M> _bs;
};那布隆过滤器支持删除吗?当然不支持!
没有reset(不可以删除)的原因是:因为存在哈希冲突,修改一个数的哈希值映射位置的值,会影响到其他的数,导致结果不准确。
硬要有reset,就需要计数,通过计数(--)来控制,那就需要成倍的位图来表示个数,严重浪费内存空间。
如上图所示这样实现
1.日常应用中,最常见的场景:
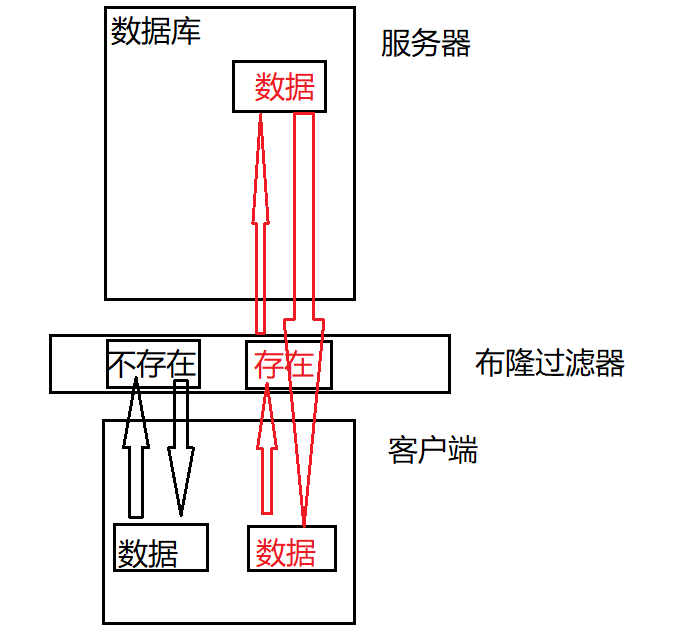
当数据量比较大时,会存放在磁盘中,磁盘访问速度相对来说很慢,所以在客户端和服务器中间加入布隆过滤器就会很大程度上加快访问速度,提高效率。
在过滤器阶段,数据不存在时,直接返回不存在;存在时,是可能存在(因为存在哈希冲突),所以会继续访问磁盘中的数据,数据在磁盘中存在即存在,不存在返回不存在。
2. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出 精确算法和近似算法。 query-般是查询指令,比如可能是一个网络请求, https://zhuanlan.zhihu.com/p/43263751/
或者是一个数据库sq|语句
假设平均每个query是50byte, 100亿个query合计多少内存? -- 500G精确算法:交集中一定是准确的(哈希切分) 近似算法:那么一定是允许有误判的情况(有误差),那么就可以使用布隆过滤器。 当看到这个题目时,可能就会想到位图来解决,但是100亿个字符串都是不相同的,100亿个字符串已经超过了1G,不可行。 精确算法: 利用哈希函数,将100亿个query是500G,因为要到内存中比较两个文件,所以需要分为1000个小文件,每个小文件占用0.5G,那么两个小文件就可以都进内存中比较了。 如图所示: 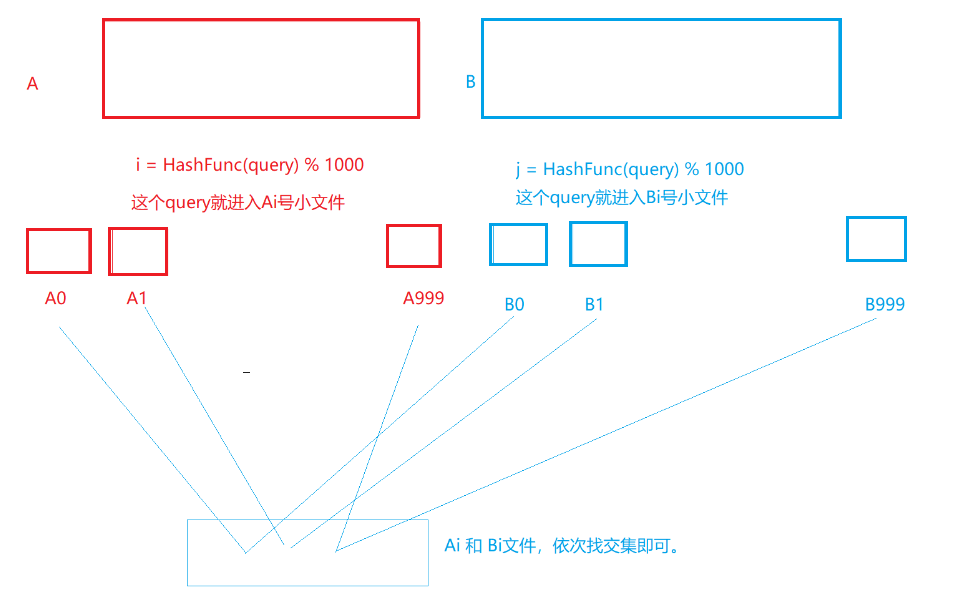
当然也会出现哈希冲突超过0.5G的情况,若是重复数较多,但是我们是找交集,所以用位图来存或不在时,0.5G的小文件中数据个数占的内存一定小于0.5G,然后两个位图相与即可。
但如果是都不重复,就需要递归继续分割。用位图找交集
不同的场景需要我们灵活的去找适合的方法去解决问题。
我们下期再见!
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu