策略:选择图中的一个顶点作为起始点,每一步贪心选择不在当前生成树中的最近顶点加入生成树中,直到所有顶点都加入到树中。
算法如下:
(1)、假如G为无向连通带权图,每两个相邻节点构成一个带权边,其值设为:权值。即:(所有每相邻的两个节点都有各自的权值,只是权值大小不同)
(2)、设集合 W和D,W用于存放G的最小生成树的顶点集合,D存放G的最小生成树的权值集合
(3)、选中G的一个节点 (其索引为data-0) 作为初值,从顶点data0开始构建最小生成树。集合D的初值为D{}。
(4)、标记W[data0]=1.表示标记已被选中的节点
(5)、data0节点找出周围相邻,且带权边最小的节点(其索引为data-n)。
(6)、将节点data-n加入集合W。标记W[data-n]=1;将带权边(data0,data-n)加入集合D
(7)、重复上面步骤
图解步骤:
(1)、无向连通图

(2)、以节点A开始延申:发现(A,G)间的权值最小,于是选中G为连通点

(3)、以A、G节点为顶点找与之相邻的最小权值边:发现(G,B)间的带权边值最小,选中B
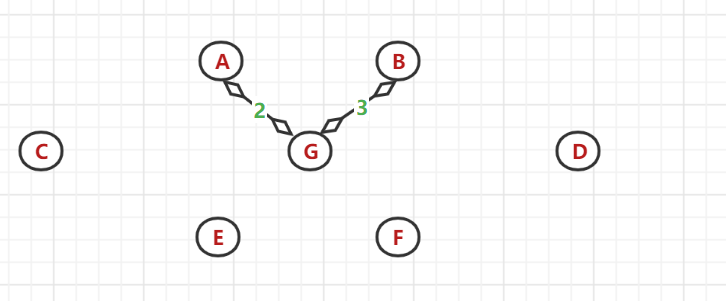
(4)、又以 A、G、B节点为顶点找与之相邻的最小权值边:发现(G,E)间的带权边值最小,选中E
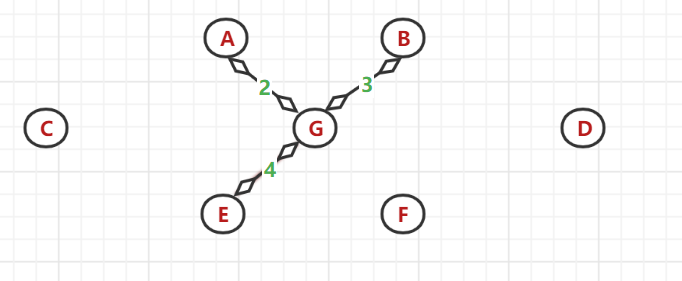
(5)、又以 A、G、B、E节点为顶点找与之相邻的最小权值边:发现(B,A)与(E,F)间的带权边值最相同且最小,但A和B节点都是已使用过的节点,所以选中 F 节点

(6)、依次选择,得到最后的最小生成树

代码如下:
import java.util.Arrays;
/*
贪心策略:最小生成树-普里姆算法
:在包含n个顶点的无向连通图中,找出只有(n-1)条边且包含n个顶点的连通子图。使其形成最小连通子图。连通子图不能出现回路
分析:
1.设置集合 W和集合 D 。其中W存入的是无向连通图中最小生成树的顶点集合;D存入的是最小生成树每相邻两个顶点之间的连接边的集合
2.另集合W的初值为 W{w0}(即从w0顶点开始构建最小生成树),另集合D初始值为 D{}
3.设V为还未被选中的顶点。
4.从w与v=V-W 中组成的所有带权边中选出最小的带权边(wn,vn).
5.将顶点vn加入集合W中。此时集合W{wn,vn},集合D{(wn,vn)}
6.重复上面步骤,直到V中所有顶点都加入到了W中,边有n-1条带权边。结束
代码:探讨修路问题
*/
public class test1 {
public static void main(String[] args) {
//所有节点
char[] ndata=new char[]{'A','B','C','D','E','F','G'};
//获取节点个数
int nodes = ndata.length;
//邻接矩阵.用较大的数10000表示两点不连通
int[][] ndlenght=new int[][]{
//A ,B,C, D , E , F ,G
{10000,5,7,10000,10000,10000,2}, //A
{5,10000,10000,9,10000,10000,3}, //B
{7,10000,10000,10000,8,10000,10000},//C
{10000,9,10000,10000,10000,4,10000},//D
{10000,10000,8,10000,10000,5,4}, //E
{10000,10000,10000,4,5,10000,6}, //F
{2,3,10000,10000,4,6,10000}, //G
};
//创建图对象
Chart chart=new Chart(nodes);
//创建生成数对象
MinTree mt=new MinTree();
//创建邻接矩阵
mt.creathart(chart,nodes,ndata,ndlenght);
//获取矩阵
// mt.dischart(chart);
mt.Prim(chart,0);
}
}
/*
第二步:
创建生成树对象
*/
class MinTree{
/**
* 创建邻接矩阵
* @param chart :图对象
* @param nodes :节点个数
* @param ndata :存放节点数据
* @param ndlenght :带权边
*/
public void creathart(Chart chart,int nodes,char[] ndata,int[] [] ndlenght){
//i:已经被选中的节点,ndata[i0]就是为初值,ndata[0]节点开始生成树。一共有nodes个
for (int i=0;i<nodes;i++){
//将当前已被选的节点存入图对象的ndata中
chart.ndata[i]=ndata[i];
//j:还未被选中的节点
for (int j=0;j<nodes;j++){
//将所有可能两两连接的节点组合,存入图对象的邻接矩阵中
chart.ndlenght[i][j]=ndlenght[i][j];
}
}
}
//显示图矩阵
public void dischart(Chart chart){
for (int[] link:chart.ndlenght){
System.out.println(Arrays.toString(link));
}
}
/**
* 普里姆算法:
* 最小生成树
* @param chart:图
* @param v :初值
*/
public void Prim(Chart chart,int v){
//存放已被选中的节点,初始都为0
int[] ondata=new int[chart.nodes];
//标记初值节点已被选中,1(表示被选中了的)
ondata[v]=1;
//设即将相连的两个节点下标为 index1、index2。由于还没有存入,所以初始为-1
int index1=-1;
int index2=-1;
//由于还不知道第一个边长为多少,所以先虚拟设置一个最大带权边长。后面后被替换的
int max=10000;
//k:表示最多生成(n-1)条带权边
for (int k=1;k<chart.nodes;k++){
//i:表示以被选中的节点;j:还未被选中的节点
for (int i=0;i<chart.nodes;i++){
for (int j=0;j<chart.nodes;j++){
if (ondata[i]==1&&ondata[j]==0&&chart.ndlenght[i][j]<max){
max=chart.ndlenght[i][j];
index1=i;
index2=j;
}
}
}
System.out.println("节点:<"+chart.ndata[index1]+","+chart.ndata[index2]+">,==>带权边长:"+max);
//将当前节点标记为以访问使用的节点
ondata[index2]=1;
//重置max
max=10000;
}
}
}
/*
第一步:
创建图对象
*/
class Chart{
int nodes; //图中节点个数
char[] ndata; //存放节点数据
int[] [] ndlenght; //存放带权边。也是邻接矩阵
//构造器
public Chart(int nodes) {
this.nodes = nodes;
//初始化,数组长度为nodes(节点个数)
ndata=new char[nodes];
//初始化,矩阵为nodes行nodes列
ndlenght=new int[nodes][nodes];
}
}
结果:

策略:每一次贪心的选择从剩下的边中最小的边且不产生环路的,加入到已选边的集合中。直到所有顶点都加入进来。
按照权值从小到大选择n-1条边,并且这些边不构成环路。
算法如下:
(1)、构建有n个顶点的无边连通图 W ,
(2)、对无向连通图 H 中的各个带权边从小到大排序
(3)、依次从小到大将 H 中的带权边加入到 W中(期间不能构成环路)
算法图解及判断环路:
环路:已加入加入到无边联通图中的顶点的终点不能相同
终点:将所有顶点从小到大排序后,某个顶点的终点就是"与它相连的最大的顶点";
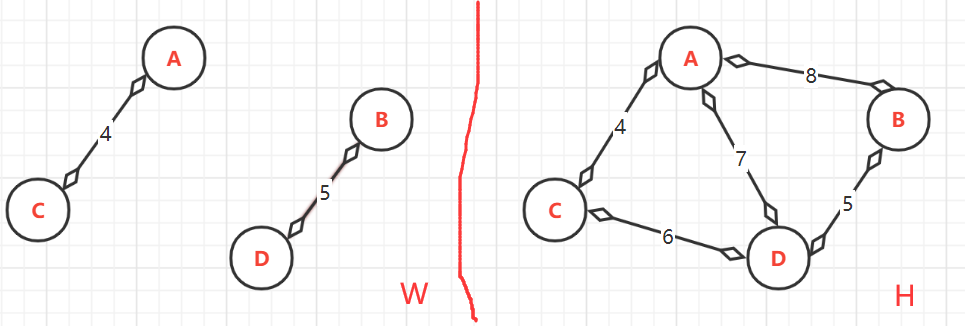
(1)、无边连通图 W。与无向连通图 H(1:顶点以排序;2.权值以排序)
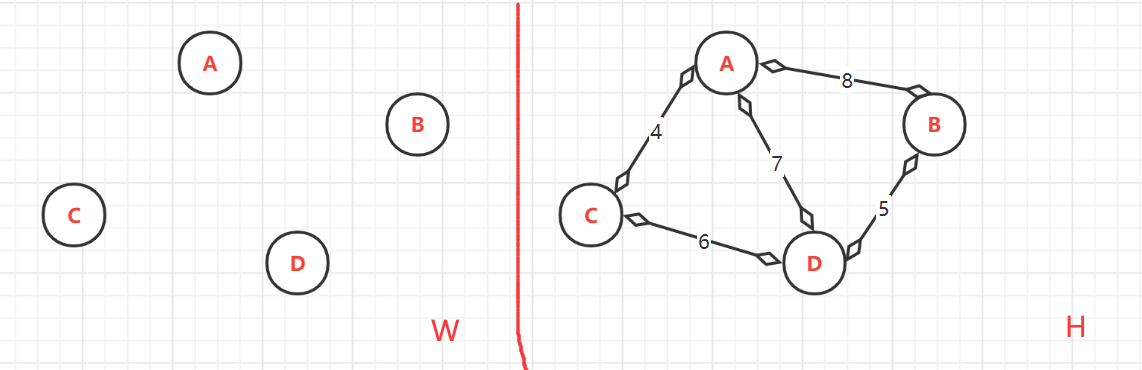
(2)、将H中从小到大排序后的边依次加入 W中。
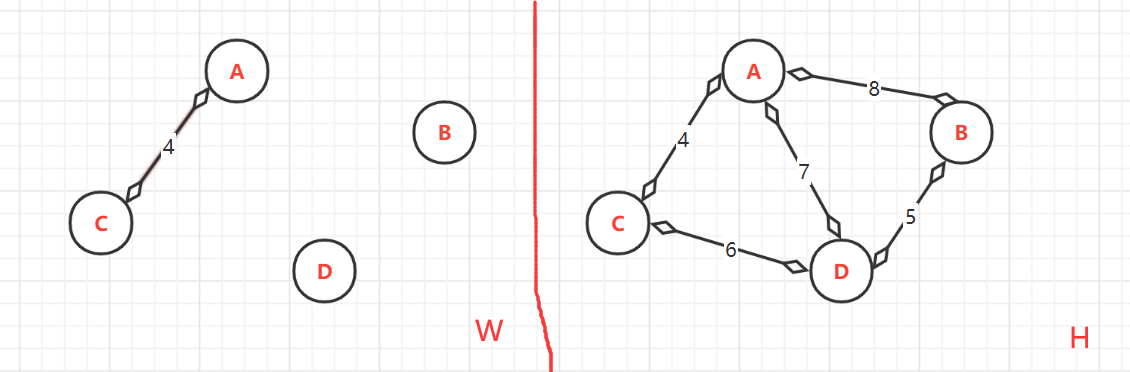
(2.1)、第一次:<A,C>=4,
顶点的终点:因为顶点是已排序为{A,B,C,D},而目前加入到W中的只有{A,C}。所以A与C连通的最大顶点是:A--->C;C--->C
- (2.2)、第二次:<B,D>=5,
- 顶点的终点:此时**W**中有{A,C},{B,D}。由于目前{B,D}还没有与{A,C}连通,所以B与D连通的最大顶点是:B--->D;D--->D,
- (2.3)、第三次:<C,D>=6,这里虽然前面C与D被加入过,但它们的终点却不同。
- 顶点的终点:此时**W**中有{A,C},{B,D},{C,D}。由于{C,D}的加入导致{A,B,C,D}相互连接,所最大顶点是:A--->D;B--->D;C--->D;D--->D,
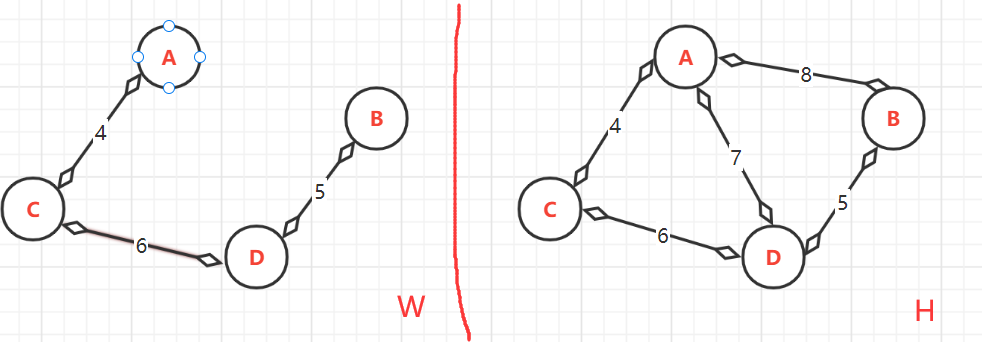
- (2.4)、第四次:<A,D>=7。由于前面得出A,与D的最大顶点(终点)相同为D,如果加入会构成环路。所以不能加入.跳过此边,加入下一条边
- (2.5)、第五次:<A,B>=8。由于前面得出A,与B的最大顶点(终点)相同为D,如果加入会构成环路。所以不能加入。所以加入下一条边,发现没有,所有边都已加入到了。
(3)、注意:在(2.3)时。其实所有顶点都已加入到了W中,所以就不需要判断后面的了。后面的结论只是为了说明终点与环路。
代码如下:
import java.util.Arrays;
/**
* 最小生成树:克鲁斯卡尔算法
* 将无向连通图中的各个边从小到大排序,依次放入无边连通图中(不能出现环路)
*/
public class test1 {
private int geshu; //边的个数
private char[] data; //存放节点
private int[][] allquanzhi; //存放带权边,邻接矩阵
//标记不能相连通的两个节点,即不相邻的两个节点所形成的带权边。为Integer最大值
private static final int maxlen = Integer.MAX_VALUE;
public static void main(String[] args) {
// char[] data={'A','B','C','D','E'};
// int[][] allquanzhi={
// {0,20,maxlen,60,15},
// {20,0,42,maxlen,maxlen},
// {maxlen,42,0,30,maxlen},
// {60,maxlen,30,0,23},
// {15,maxlen,maxlen,23,0},
// };
char[] data={'A','B','C','D'};
int[][] allquanzhi={
{0,8,4,7},
{8,0,maxlen,5},
{4,maxlen,0,6},
{7,5,6,0}
};
test1 t=new test1(data,allquanzhi);
//打印矩阵
t.dayinjuzheng();
Bian[] bians=t.andbian();
System.out.println("排序前的边集合"+Arrays.toString(bians));
t.biansort(bians);
System.out.println("排序后的边集合"+Arrays.toString(bians));
t.KrusKal();
}
//定义构造器
public test1(char[] data, int[][] allquanzhi) {
//初始化顶点数
int spotgeshu = data.length;
//初始化顶点(节点)
this.data = data;
//初始化 边
this.allquanzhi = allquanzhi;
//统计边的个数
for (int i = 0; i < spotgeshu; i++) {
for (int j = i+1; j < spotgeshu; j++) {
if (this.allquanzhi[i][j] < maxlen) {
geshu++;
}
}
}
}
//打印邻接矩阵
public void dayinjuzheng() {
System.out.println(geshu);
for (int i = 0; i < data.length; i++) {
for (int j = 0; j < data.length; j++) {
//格式化输出
System.out.printf("%15d\t", +allquanzhi[i][j]);
}
System.out.println();
}
}
/*
对边排序:冒泡《从小到大》
*/
public void biansort(Bian[] bian){
for (int i=bian.length-1;i>0;i--){
for (int j=0;j<i;j++){
if (bian[j].bianquanzhi>bian[j+1].bianquanzhi){
Bian temp=bian[j];
bian[j]=bian[j+1];
bian[j+1]=temp;
}
}
}
}
/*
判断顶点是否存在
返回顶点的索引
*/
public int ismbian(char ch){
for (int i=0;i<data.length;i++){
if (data[i]==ch){
return i;
}
}
//如果ch不是顶点就返回-1
return -1;
}
/*
将所以相邻边存入Bian[]中
*/
public Bian[] andbian(){
int index=0;
Bian[] bians=new Bian[geshu];
for (int i=0;i<data.length;i++){
for (int j=i+1;j<data.length;j++){
if (allquanzhi[i][j]!=maxlen){
bians[index++]=new Bian(data[i],data[j],allquanzhi[i][j]);
}
}
}
return bians;
}
/*
获取小标为i的顶点的终点,用于判断两个顶点的终点是否相同
star:存入的是顶点的终点的索引,初始化为{0,0,0,0,...},
i:顶点的索引
*/
public int getEnd(int[] star,int i){
//动态的判断以此顶点的索引,
//相连的前一个顶点的终点索引就是后一个顶点的索引
//由于第一次的顶点的终点是自己的索引都
//如果在star中找到了终点
while (star[i]!=0){
//就将此终点的值变为新的顶点的索引(找到此索引对应的顶点的终点,直到新的索引在star中没有找到终点,即为0,就将此索引返回为最初始的节点的终点索引)
i=star[i];
}
//返回为终点
return i;
}
/*
最小生成树克鲁斯卡尔算法
*/
public void KrusKal(){
int index=0; //最后结果数组的索引
//存放最小生成树每个顶点的终点
int[] star=new int[geshu];
//保存最终生成树
Bian[] fin=new Bian[geshu];
//获取边的集合
Bian[] andnewbian = andbian();
//对所有边进行排序
biansort(andnewbian);
//遍历边集合。在判断的同时判断是否形成回路
for (int i=0;i<geshu;i++){
//上面andbian存放获得的边的类:bians[index++]=new Bian(data[i],data[j],allquanzhi[i][j]);
//获取第一边的起点(顶点),对应的是data[i]
int h1=ismbian(andnewbian[i].da1);
//获取第一条边的第二个顶点,对应的是data[j]
int h2=ismbian(andnewbian[i].da2);
//获取第一个顶点的终点
int end = getEnd(star, h1);
//获取第二个顶点的终点
int end1 = getEnd(star, h2);
//判断回路:如果没有构成回路
if (end!=end1){
//设置end1为已有生成数的终点
star[end]=end1;
//此时最终生成树有了一条边
fin[index++]=andnewbian[i];
}
}
System.out.println("最后生成树:"+Arrays.toString(fin));
System.out.println("最小生成树:");
for (int i=0;i<index;i++){
System.out.println(fin[i]);
}
}
}
/*
边类
*/
class Bian{
//组成一条边的两个节点
char da1;
char da2;
//边权值
int bianquanzhi;
public Bian(char da1, char da2, int bianquanzhi) {
this.da1 = da1;
this.da2 = da2;
this.bianquanzhi = bianquanzhi;
}
@Override
public String toString() {
return "bian{" +
"da1=" + da1 +
", da2=" + da2 +
", bianquanzhi=" + bianquanzhi +
'}';
}
}
结果:

目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
假设我有以下类(class):classPersondefinitialize(name,age)@name=name@age=ageenddefget_agereturn@ageendend我有一组Person对象。是否有一种简洁的、类似于Ruby的方法来获取最小(或最大)年龄的人?如何根据它对它们进行排序? 最佳答案 这样做会:people_array.min_by(&:get_age)people_array.max_by(&:get_age)people_array.sort_by(&:get_age)
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
看来我正在回顾SO帖子中采取的步骤:Capybara,PoltergeistandPhantomjsandgivinganemptyresponseinbody.(如果你愿意,可以将其标记为重复,但我包含了一个最小的独立测试用例和版本号。)问题我做错了什么吗?我可以运行另一个可能有助于隔离问题的最小测试吗?文件:pgtest.rbrequire'rubygems'require'capybara'require'capybara/dsl'require'capybara/poltergeist'modulePGTestincludeCapybara::DSLextendselfdeft
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶