给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例 1:
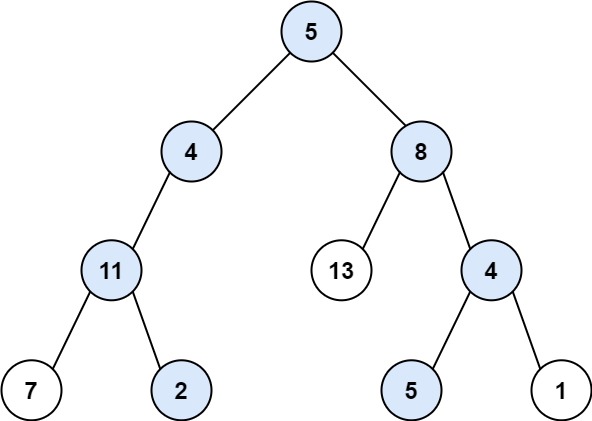
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
示例 2:
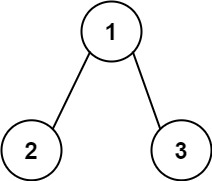
输入:root = [1,2,3], targetSum = 5
输出:[]
示例 3:
输入:root = [1,2], targetSum = 0
输出:[]
提示:
树中节点总数在范围 [0, 5000] 内
-1000 <= Node.val <= 1000
-1000 <= targetSum <= 1000
作者:Krahets
链接:https://leetcode.cn/leetbook/read/illustration-of-algorithm/5dy6pt/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先能够想到的是用二叉树递归的方式来查找路径,每次递归都需要修改target的值,在这种做法中有一个问题:如何设置返回值,从而返回路径列表,且在程序中如何修改路径列表?
在官方题解中,在类的定义中适用result、path两个公共变量,可以让不同的函数均基于这块公共区域加以修改。
遍历使用的是先序遍历。
path路径中;需要注意的是,由于list.add()使用的是浅拷贝,如果每次将path添加到结果列表中使用的是result.add(path),这样写忽略了list.add()是进行浅拷贝的,即每个路径结果path都指向同一个内存地址,后续在此内存地址上的操作将会改变前期的结果。最终出现[[x,y,z][x,y,z][x,y,z]]三个子列表相同的情况。因此,每次写入result列表应该新建一个path对象。
//LinkedList
LinkedList<E> listname=new LinkedList<E>();//初始化
LinkedList<E> listname=new LinkedList<E>(oldlist);//将oldlist的元素复制一份给listname,且是深拷贝
LinkedList.add(elment);//在链表尾部添加元素
LinkedList.removeFirst();//取出链表头部元素
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
// 考虑迭代,左右子树再找某个目标值的路径。
class Solution {
LinkedList<List<Integer>> result=new LinkedList<List<Integer>>();
LinkedList<Integer> path=new LinkedList<Integer>();
public List<List<Integer>> pathSum(TreeNode root, int target) {
recur(root,target);
return result;
}
void recur(TreeNode root, int target) {
if(root!=null){
path.add(root.val);
target-=root.val;
if(target==0&&root.left==null&&root.right==null){//遍历到叶节点且目标值正好等于路径之和
LinkedList<Integer> path_temp=new LinkedList<Integer>(path);
result.add(path_temp);
}
recur(root.left,target);
recur(root.right,target);
path.removeLast();//回退时将当前元素出栈
}
}
}
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我在新的Debian6VirtualBoxVM上安装RVM时遇到问题。我已经安装了所有需要的包并使用下载了安装脚本(curl-shttps://rvm.beginrescueend.com/install/rvm)>rvm,但以单个用户身份运行时bashrvm我收到以下错误消息:ERROR:Unabletocheckoutbranch.安装在这里停止,并且(据我所知)没有安装RVM的任何文件。如果我以root身份运行脚本(对于多用户安装),我会收到另一条消息:Successfullycheckedoutbranch''安装程序继续并指示成功,但未添加.rvm目录,甚至在修改我的.bas