✨博客主页:米开朗琪罗~🎈
✨博主爱好:羽毛球🏸
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
目录
函数:img, contours, hierarchy = cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
参数介绍:
cv2.RETR_EXTERNAL:只检测外轮廓
cv2.RETR_LIST:检测的轮廓不建立等级关系
cv2.RETR_CCOMP:建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE:建立一个等级树结构的轮廓。
cv2.CHAIN_APPROX_NONE:存储所有的轮廓点, 相邻的两个点的像素位置差不超过1, 即max(abs(x1-x2), abs(y2-y1)) == 1
cv2.CHAIN_APPROX_SIMPLE:压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息。
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS:用teh-Chinl chain 近似算法
https://blog.csdn.net/hjxu2016/article/details/77833336
注意:在查找物体轮廓之前要先对图像进行灰度化与二值化操作!
实验使用图像:

import cv2
import numpy as np
original = cv2.imread(r'C:\Users\Lenovo\Desktop\contour.jpg')
print(original.shape)
# 查找物体轮廓
def findcontour(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 图像灰度化
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 图像二值化
image, contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 查找物体轮廓
return image, contours, hierarchy
image, contours, hierarchy = findcontour(original)
我们打印轮廓数量:
print('轮廓数:', len(contours))
得到:轮廓数: 3
注意:findcontours函数会“原地”修改输入的图像!!!
函数:img = cv2.drawContours(image, contours, contourIdx, color, thickness=None, lineType=None, hierarchy=None, maxLevel=None, offset=None)
参数介绍:
contours = cv2.drawContours(original, contours, -1, (255, 0, 0), 5) # 绘制所有轮廓
cv2.imshow("contour", contours)
cv2.waitKey()
所有轮廓绘制的结果如下:

nums = len(contours)
color = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]
contourssplit=[]
for i in range(nums):
temp = np.zeros(original.shape, np.uint8)
contourssplit.append(temp)
contourssplit[i] = cv2.drawContours(contourssplit[i], contours, i, color[i], 2)
cv2.imwrite(r'C:\\Users\\Lenovo\\Desktop\\%d.jpg' % i, contourssplit[i])
cv2.imshow("contours" + str(i), contourssplit[i])
cv2.waitKey()
逐个轮廓绘制的结果如下:



计算轮廓面积
函数:area= cv2.contourArea(contour,oriented)
参数介绍:
true:此函数依赖轮廓的方向(顺时针或逆时针)返回一个已标记区域的值。
false:默认值。意味着返回不带方向的绝对值。
该函数有个缺点:由于其计算方式是利用格林公式计算轮廓面积,所以如果遇到具有自交点的轮廓,该函数会给出错误的结果。
统计轮廓信息
⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️重点⬇️⬇️⬇️⬇️⬇️⬇️⬇️⬇️
函数:moment = cv2.moments(contour)
参数介绍:
函数返回一个字典,你可以从中得到有关轮廓的各种信息,包括面积、重心等!
计算轮廓周长
函数:perimeter=cv2.arcLength(contour, closed)
参数介绍:
True:轮廓封闭。
False:轮廓不封闭。
我们先看cv2.moments中的信息,使用debug看a中的数据:
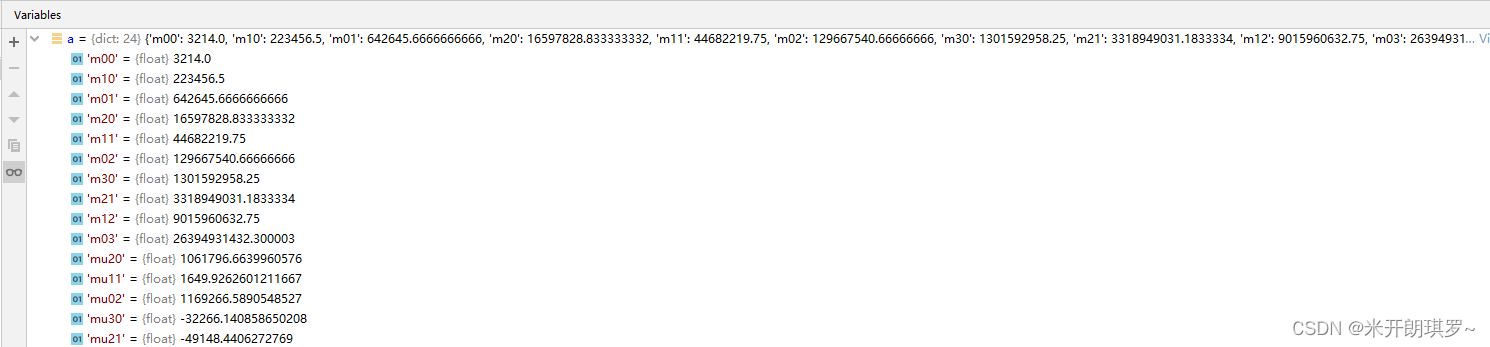
a是一个具有24个键值对的字典,包含了轮廓的各个信息。
使用cv2.moments(contours[i])['m00']得到轮廓面积;
使用int(cv2.moments(contours[i])['m10']/cv2.moments(contours[i])['m00'])和
int(cv2.moments(contours[i])['m01']/cv2.moments(contours[i])['m00'])得到轮廓重心;
使用cv2.arcLength(contours[i], True)得到轮廓的长度。
nums = len(contours)
color = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]
contourssplit=[]
for i in range(nums):
temp = np.zeros(original.shape, np.uint8)
contourssplit.append(temp)
contourssplit[i] = cv2.drawContours(contourssplit[i], contours, i, color[i], 2)
a = cv2.moments(contours[i])
print("轮廓" + str(i) + "的面积:%d" % cv2.moments(contours[i])['m00'])
print("轮廓" + str(i) + "的重心:%d" % int(cv2.moments(contours[i])['m10']/cv2.moments(contours[i])['m00']),
int(cv2.moments(contours[i])['m01']/cv2.moments(contours[i])['m00']))
print("轮廓" + str(i) + "的长度:%d" % cv2.arcLength(contours[i], True))
结果如下:
轮廓0的面积:3214
轮廓0的重心:69 199
轮廓0的长度:403
轮廓1的面积:4752
轮廓1的重心:202 142
轮廓1的长度:336
轮廓2的面积:8019
轮廓2的重心:69 67
轮廓2的长度:336
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht