一句话概述:Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,同时也是 Elastic Stack 的核心。
其应用于比如说全文搜索、购物推荐、附近定位推荐等。
官网下载链接:https://www.elastic.co/cn/downloads/elasticsearch
Elasticsearch 是免安装的,只需要把 zip 包解压就可以了。

1)bin 目录下是一些脚本文件,包括 Elasticsearch 的启动执行文件。
2)config 目录下是一些配置文件。
3)jdk 目录下是内置的 Java 运行环境。
4)lib 目录下是一些 Java 类库文件。
5)logs 目录下会生成一些日志文件。
6)modules 目录下是一些 Elasticsearch 的模块。
7)plugins 目录下可以放一些 Elasticsearch 的插件。
直接双击 bin 目录下的 elasticsearch.bat 文件就可以启动 Elasticsearch 服务了。

启动后输出了很多信息,只需要看启动日志中是否有started字眼,就表示启动成功了。
确认是否真正启动成功,可以在浏览器的地址栏里输入 http://localhost:9200 进行查看(9200 是 Elasticsearch 的默认端口号)。

官网下载链接:https://www.elastic.co/cn/downloads/kibana
下载后解压如下图(不同版本可能不一样)
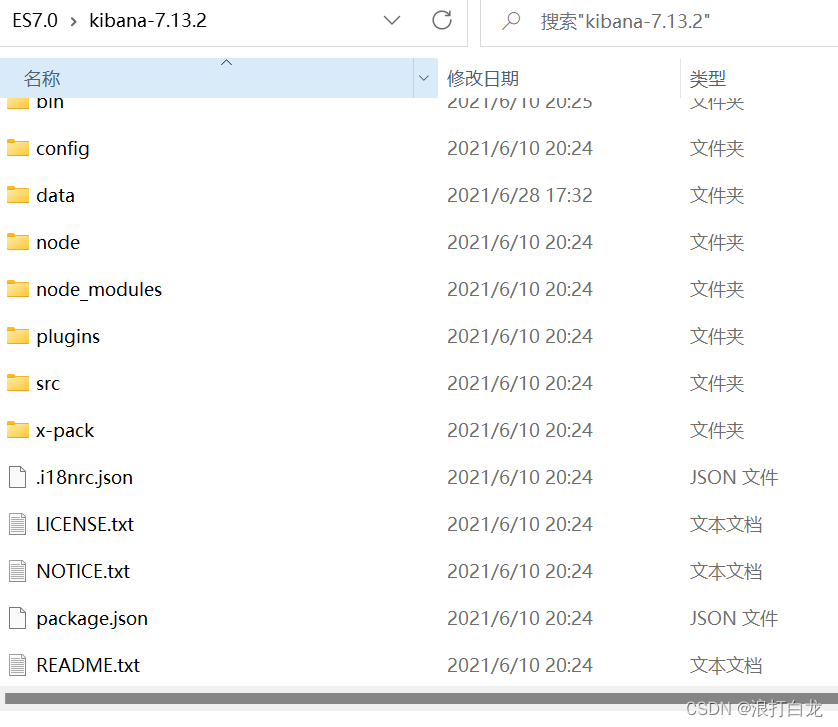
各级目录不一一解释什么意思,大家可以自行去问度娘。
启动同样跟elasticsearch的启动一样,直接点击bin目录下的kibana.bat即可启动,启动速度相对较慢一点。
当看到 [Kibana][http] http server running 的信息后,说明服务启动成功了。
验证:在浏览器地址栏输入 http://localhost:5601 查看 Kibana 的图形化界面。
GET _cluster/health 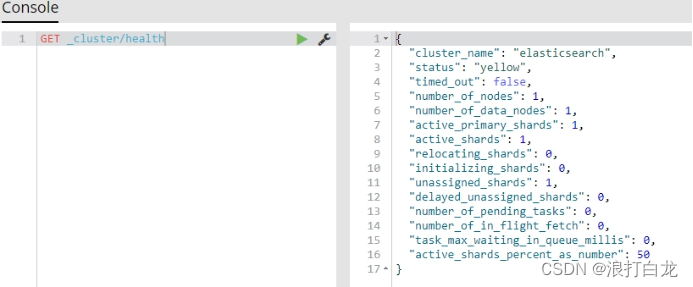
GET _cat/health?v 集群的状态:Green: 所有的primary shard和所有的replica shard 都是active的Yellow:所有的primary shard都是active的但是部分replica shard不是activeRed: 不是所有的primary shard都是active的,可能会造成数据丢失
集群的状态:Green: 所有的primary shard和所有的replica shard 都是active的Yellow:所有的primary shard都是active的但是部分replica shard不是activeRed: 不是所有的primary shard都是active的,可能会造成数据丢失
Es规定primary shard和与他对应的replica shard 不能再同一台机器上,所以当前的状态是yellow的
GET _cat/indices?v
PUT /index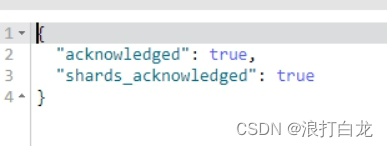
PUT /ecommerce/product/1
{
"name": "gaolujie yagao",
"price": 20,
"desc": "gaolujie yaga desc",
"tags": "meibai jieya"
}
GET /ecommerce/product/1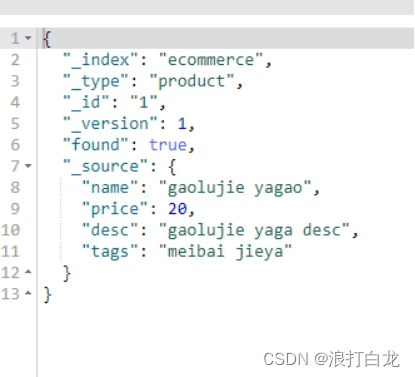
i. 全量更新 (更新后可能部分列丢失)
PUT /ecommerce/product/1
{
“name” : “heimei”
}
ii. portial update(需要更新什么 就写什么)
POST /ecommerce/product/1/_update
{
“doc”:{
“name” : “heimei”
}
}
#创建索引结构
PUT sku
{
"mappings": {
"doc":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart"
},
"price":{
"type":"integer"
},
"image":{
"type":"text"
},
"createTime":{
"type":"date"
},
"spuId":{
"type":"text"
},
"categoryName":{
"type":"keyword"
},
"brandName":{
"type":"keyword"
},
"spec":{
"type":"object"
},
"saleNum":{
"type":"integer"
},
"commentNum":{
"type":"integer"
}
}
}
}
}
#增加文档
POST sku/doc
{
"name":"华为手机",
"price":4500,
"spuId":"106",
"createTime":"2019-06-25",
"categoryName":"手机",
"brandName":"华为",
"saleNum":54532,
"commentNum":32543,
"spec":{
"网络制式":"全网通",
"屏幕尺寸":"6.5"
}
}
#新增指定ID文档
PUT sku/doc/1
{
"name":"小米电视",
"price":3500,
"spuId":"117",
"createTime":"2019-06-25",
"categoryName":"电视",
"brandName":"小米",
"saleNum":2332,
"commentNum":4123,
"spec":{
"网络制式":"联通4G",
"屏幕尺寸":"6.5"
}
}
#查询所有文档
GET /sku/_search
{
"query": {
"match_all": {}
}
}
#匹配查询(单字段查询 分词查询默认为or)
GET /sku/doc/_search
{
"query": {
"match": {
"name": "小米手机"
}
}
}
#匹配查询(精准查找)
GET /sku/doc/_search
{
"query": {
"match": {
"name": {
"query": "小米电视",
"operator": "and"
}
}
}
}
#多字段查询(multi_match)
GET /sku/_search
{
"query": {
"multi_match": {
"query": "小米",
"fields": ["name","brandName","categoryName"]
}
}
}
#词条匹配(term)
GET /sku/_search
{
"query": {
"term": {
"price": "1000"
}
}
}
#多词条匹配(terms)
GET /sku/_search
{
"query": {
"terms": {
"price": [
"1000",
"3500"
]
}
}
}
#布尔查询(bool)
#查询名称包含手机的,并且品牌为小米的。
GET /sku/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}},
{"term": {"brandName": "小米"}}
]
}
}
}
#布尔查询(bool)
#查询名称包含手机的,或者品牌为小米的。
GET /sku/_search
{
"query": {
"bool": {
"should": [
{"match": {"name": "手机"}},
{"term": {"brandName": "小米"}}
]
}
}
}
#过滤查询
GET /sku/_search
{
"query": {
"bool": {
"filter":[
{"match":{"brandName":"小米"}}
]
}
}
}
#分组查询
#按分组名称聚合查询,统计每个分组的数量
GET /sku/_search
{
"size": 0,
"aggs": {
"sku_category": {
"terms": {
"field": "categoryName"
}
}
}
}
虽然有图形化界面可供我们操作,但是对于程序员来说更多的是在程序中如何使用,当然ES也提供了API供我们使用。
第一步,在项目中添加 Elasticsearch 客户端依赖:
版本号根据使用者喜好设置
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.13.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.13.2</version>
</dependency>
第二步,在SpringBoot的application.yml中添加 Elasticsearch配置:
# Spring配置
spring:
elasticsearch:
ip: 192.168.xx.xx
port: 9200
pool: 5
cluster:
name: my-application
第三步,编写ES读取配置类:
@Configuration
public class ElasticSearchConfig {
// 获取yml中es的配置
@Value("${spring.elasticsearch.ip}")
String esIp;
@Value("${spring.elasticsearch.port}")
int esPort;
@Value("${spring.elasticsearch.pool}")
String esClusterPool;
// 注册 rest高级客户端
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost(esIp,esPort,"http")
)
);
return client;
}
}
第四步,编写ES工具类:代码不免有细小错误请理解
@Slf4j
@Component
public class EsUtileService {
@Autowired
RestHighLevelClient restHighLevelClient;
/**
* 创建索引
*
*/
public boolean createIndex(String indexName) {
try {
CreateIndexRequest createIndexRequest = new CreateIndexRequest(indexName);
CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
log.info("创建索引 response 值为: {}", response.toString());
return true;
}catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 判断索引是否存在
*
*/
public boolean existIndex(String indexName) {
try {
GetIndexRequest getIndexRequest = new GetIndexRequest(indexName);
return restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
}catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 删除索引
*
*/
public boolean deleteIndex(String indexName) {
try {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(indexName);
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
log.info("删除索引{},返回结果为{}", indexName, delete.isAcknowledged());
return delete.isAcknowledged();
}catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 根据id删除文档
*
*/
public boolean deleteDocById(String indexName, String id) {
try {
DeleteRequest deleteRequest = new DeleteRequest(indexName, id);
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除索引{}中id为{}的文档,返回结果为{}", indexName, id, deleteResponse.status().toString());
return true;
}catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 批量插入数据
*
*/
public boolean multiAddDoc(String indexName, List<JSONObject> list) {
try {
BulkRequest bulkRequest = new BulkRequest();
list.forEach(doc -> {
String source = JSON.toJSONString(doc);
IndexRequest indexRequest = new IndexRequest(indexName);
indexRequest.source(source, XContentType.JSON);
bulkRequest.add(indexRequest);
});
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
log.info("向索引{}中批量插入数据的结果为{}", indexName, !bulkResponse.hasFailures());
return !bulkResponse.hasFailures();
}catch (Exception e) {
log.error(e.getMessage(), e);
}
return false;
}
/**
* 更新文档
*
*/
public boolean updateDoc(String indexName, String docId, JSONObject jsonObject) {
try {
UpdateRequest updateRequest = new UpdateRequest(indexName, docId).doc(JSON.toJSONString(jsonObject), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
int total = updateResponse.getShardInfo().getTotal();
log.info("更新文档的影响数量为{}",total);
return total > 0;
}catch (Exception e) {
e.printStackTrace();
}
return false;
}
/**
* 根据id查询文档
*/
public JSONObject queryDocById(String indexName, String docId) {
JSONObject jsonObject = new JSONObject();
try {
GetRequest getRequest = new GetRequest(indexName, docId);
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
jsonObject = (JSONObject) JSONObject.toJSON(getResponse.getSource());
}catch (Exception e) {
e.printStackTrace();
}
return jsonObject;
}
/**
* 通用条件查询,map类型的参数都为空时,默认查询全部
*
*/
public PageResult<List<JSONObject>> conditionSearch(String indexName, Integer pageNum, Integer pageSize, String highName, Map<String, Object> andMap, Map<String, Object> orMap, Map<String, Object> dimAndMap, Map<String, Object> dimOrMap) throws IOException {
SearchRequest searchRequest = new SearchRequest(indexName);
// 索引不存在时不报错
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
//构造搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = buildMultiQuery(andMap, orMap, dimAndMap, dimOrMap);
sourceBuilder.query(boolQueryBuilder);
//高亮处理
if (!StringUtils.isEmpty(highName)) {
buildHighlight(sourceBuilder, highName);
}
//分页处理
buildPageLimit(sourceBuilder, pageNum, pageSize);
//超时设置
sourceBuilder.timeout(TimeValue.timeValueSeconds(60));
searchRequest.source(sourceBuilder);
//执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
List<JSONObject> resultList = new ArrayList<>();
for (SearchHit hit : searchHits) {
//原始查询结果数据
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//高亮处理
if (!StringUtils.isEmpty(highName)) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get(highName);
if (highlightField != null) {
Text[] fragments = highlightField.fragments();
StringBuilder value = new StringBuilder();
for (Text text : fragments) {
value.append(text);
}
sourceAsMap.put(highName, value.toString());
}
}
JSONObject jsonObject = JSONObject.parseObject(JSONObject.toJSONString(sourceAsMap));
resultList.add(jsonObject);
}
long total = searchHits.getTotalHits().value;
PageResult<List<JSONObject>> pageResult = new PageResult<>();
pageResult.setPageNum(pageNum);
pageResult.setPageSize(pageSize);
pageResult.setTotal(total);
pageResult.setList(resultList);
pageResult.setTotalPage(total==0?0: (int) (total % pageSize == 0 ? total / pageSize : (total / pageSize) + 1));
return pageResult;
}
/**
* 构造多条件查询
*
*/
public BoolQueryBuilder buildMultiQuery(Map<String, Object> andMap, Map<String, Object> orMap, Map<String, Object> dimAndMap, Map<String, Object> dimOrMap) {
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
//该值为true时搜索全部
boolean searchAllFlag = true;
//精确查询,and
if (!CollectionUtils.isEmpty(andMap)) {
for (Map.Entry<String, Object> entry : andMap.entrySet()) {
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(entry.getKey(), entry.getValue());
boolQueryBuilder.must(matchQueryBuilder);
}
searchAllFlag = false;
}
//精确查询,or
if (!CollectionUtils.isEmpty(orMap)) {
for (Map.Entry<String, Object> entry : orMap.entrySet()) {
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(entry.getKey(), entry.getValue());
boolQueryBuilder.should(matchQueryBuilder);
}
searchAllFlag = false;
}
//模糊查询,and
if (!CollectionUtils.isEmpty(dimAndMap)) {
for (Map.Entry<String, Object> entry : dimAndMap.entrySet()) {
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery(entry.getKey(), "*" + entry.getValue() + "*");
boolQueryBuilder.must(wildcardQueryBuilder);
}
searchAllFlag = false;
}
//模糊查询,or
if (!CollectionUtils.isEmpty(dimOrMap)) {
for (Map.Entry<String, Object> entry : dimOrMap.entrySet()) {
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery(entry.getKey(), "*" + entry.getValue() + "*");
boolQueryBuilder.should(wildcardQueryBuilder);
}
searchAllFlag = false;
}
if (searchAllFlag) {
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
boolQueryBuilder.must(matchAllQueryBuilder);
}
return boolQueryBuilder;
}
/**
* 构建高亮字段
*
*/
public void buildHighlight(SearchSourceBuilder sourceBuilder, String highName) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
//设置高亮字段
highlightBuilder.field(highName);
//多个高亮显示
highlightBuilder.requireFieldMatch(false);
//高亮标签前缀
highlightBuilder.preTags("<span style='color:red'>");
//高亮标签后缀
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
}
/**
* 构造分页
*/
public void buildPageLimit(SearchSourceBuilder sourceBuilder, Integer pageNum, Integer pageSize) {
if (sourceBuilder!=null && !StringUtils.isEmpty(pageNum) && !StringUtils.isEmpty(pageSize)) {
sourceBuilder.from(pageSize * (pageNum-1) );
sourceBuilder.size(pageSize);
}
}
}
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po