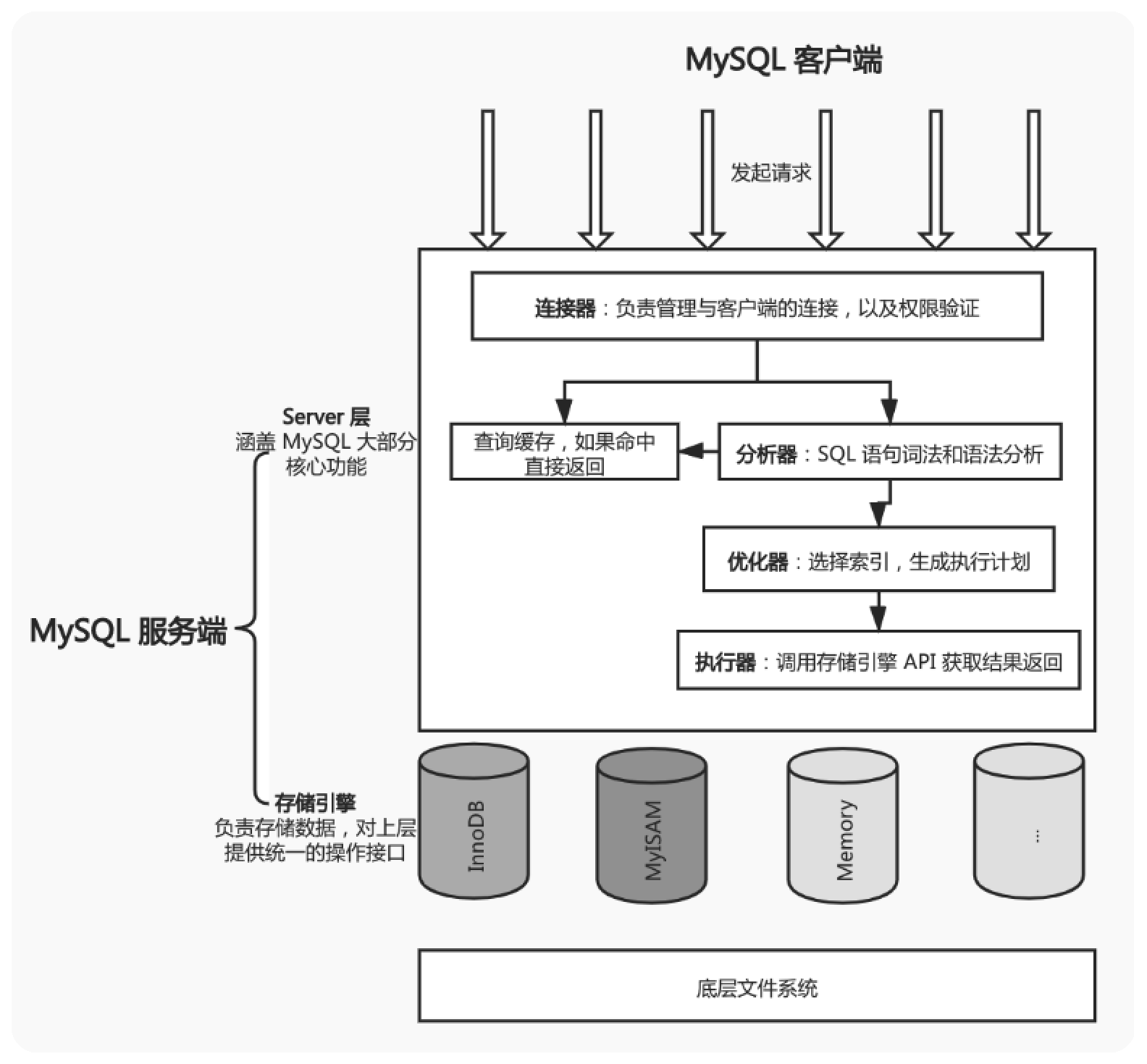
主要分为两部分,server层和存储引擎
连接器、查询缓存、分析器、优化器、执行器等,涵盖mysql的大多数核心服务过功能,以及所有的内置函数,所有跨存储引擎的功能都在这一层实现,比如存储过程,触发器,视图等InnoDB、MyISAM等多个引擎。从mysql5.5.5版本开始InnoDB成为了默认引擎。由mysql客户端发起请求,连接器负责与客户端连接验证权限,连接成功之后开始查询缓存(当缓存开启时),如果命中则直接返回数据,如果没有命中则交由分析器进行sql词法和语法分析,然后交给优化器进行选择索引生成执行计划,最后交给执行器去调用存储引擎的API获取结果并返回
当 MySQL 服务端拿到一条 SQL 查询语句后,首先会查询缓存,看之前是不是执行过这条语句。如果执行过,会缓存在内存中,这个时候直接返回之前缓存的查询结果给客户端即可;如果在缓存中没有找到对应的记录,就会继续后面的操作,并且在最终执行完成后,将查询结果保存到查询缓存。
注:MySQL 8.0 版本开始将不再支持查询缓存功能。
可以通过show variables like '%query_cache%';语句查看系统查询缓存的设置
query_cache_type 为 OFF 表示默认关闭。你可以在配置文件中配置该值来决定是否启用查询缓存。
如果查询缓存没有启用或者没有命中,就开始真正执行 SQL 查询语句了。
MySQL 会通过分析器对 SQL 语句做词法分析,以确定到底要做什么,比如 select 表示查询语句,update 表示更新语句等,表名是什么,查询的字段有哪些,查询的条件是什么。
如果 SQL 语句词法和语法分析都没有问题,接下来,会经由优化器生成执行计划,这里面主要的工作是数据表包含索引的时候,判定是否使用索引,以及使用哪些索引效率最高(扫描行数最少),我们可以在执行一个 SQL 查询语句之前通过 explain 语句查看它的执行计划:
根据执行计划执行sql查询语句时,会先验证权限,有相应权限才会继续执行,否则会报权限错误
具体的查询操作是通过存储引擎提供的API接口完成的。执行器调用这些接口可以完成诸如读取下一行记录、插入记录、更新记录之类的日常数据库操作,执行 SQL 查询返回所有满足条件的结果集也是如此。
和sql查询语句一样,MySql客户端提交SQL更新语句前,先要通过连接器建立连接,连接器验证权限等相关操作,然后交给分析器进行词法和语法分析后由执行器负责具体的执行。(修改、删除语句也是一样)
当一张数据表有更新的时候,对应的查询缓存数据就会被清空。
与查询流程不一样的是,更新还涉及到日志的写入,redo log(重做日志)和binlog(归档日志)
MySql的设计者引入了WAL技术(Write-Ahead Logging),即先写日志,在写磁盘。
比如InnoDB引擎,当有记录需要更新的时候,InnoDB就会先把记录写到redolog里边,并更新内存,这时候更新操作就算是完成,等InnoDB空闲的时候,在将这个操作更新到磁盘里边。这样做就是因为如果每次更新操作都要写到磁盘的话,整个IO成本会非常高。
redo Log 是InnoDB引擎提供的日志系统,bindlog可以一直追加写入,负责数据库全量数据的备份和恢复,数据库集群的主从同步也是基于binlog实现的。
binlog是属于MySql Server层面的,所有存储引擎都可以共用它
在 InnoDB 引擎出现之前,MySQL 默认的存储引擎是 MyISAM,那个时候为了实现数据备份和恢复,使用的是 binlog,不过 binlog 是一个归档日志,不具备数据库崩溃重启后的数据恢复功能
prepare 状态,然后告知执行器执行完成了,随时可以提交事务;commit 状态,更新完成。
在上述步骤中,将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是「两阶段提交」。
如果不使用两阶段提交,会导致两份日志恢复的数据不一致:比如先写 redo log,binlog 还没有写入,数据库崩溃重启;或者先写 binlog,redo 还没有写入数据库崩溃重启,都将造成恢复数据的不一致。
而使用两阶段提交后,就可以保证两份日志恢复的数据一致:只有 binlog 写入成功的情况下,才会提交 redo log,否则 redo log 处于 prepare 状态,事务会回滚,这样一来,就保证了数据的一致性。
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption