目录
Morris遍历是一种用于二叉树遍历的算法,它可以在不使用栈或队列的情况下实现中序遍历。该算法的时间复杂度为O(n),空间复杂度为O(1)。
Morris遍历的基本思想是,利用叶子节点的空指针来存储临时信息,以达到节省空间的目的。具体来说,对于当前遍历到的节点,如果它有左子节点,就找到左子树中最右边的节点,将其右子节点指向当前节点,然后将当前节点更新为其左子节点。如果它没有左子节点,就输出当前节点的值,并将当前节点更新为其右子节点。重复以上步骤,直到遍历完整棵树。
Morris遍历的优点是空间复杂度低O(1),但它的缺点是会改变原来的二叉树结构,因此需要在遍历完后还原二叉树。此外,该算法可能会比递归或使用栈的算法稍微慢一些。
二叉树的线索化,主要是利用了叶子结点中的空指针域,存放了在某种遍历顺序下的前驱或者后续结点,从而达到了线索二叉树的目的
例如,下图中序遍历结果展示如下,根据中序遍历对空指针域进行线索化
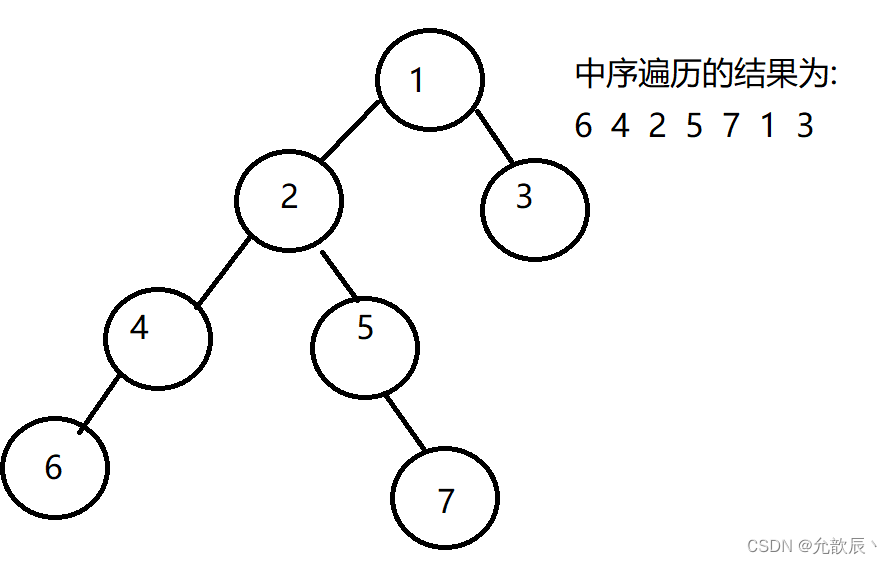
线索化的二叉树为下, 画在左边表示left结点指向,画在右边表示right指向,例如7的前驱结点为5,那么7的left指向5,7的后继节点为1,那么7的right指向1

由此,我们可能总结出这样的结论:中序遍历二叉树的指向当前结点的结点为当前结点的左子树的最右端结点,例如指向1的结点为1的左节点2的最右端结点为7,指向2结点的为2的左节点4的最右端结点4.这一点在之后的morris遍历中很重要
具体的代码实现如下:
public class InorderThreadedBinaryTree {
private ThreadTreeNode pre = null;
public void threadedNodes(ThreadTreeNode node) {
//如果node==null,不能线索化
if (node == null) {
return;
}
//1、先线索化左子树
threadedNodes(node.left);
//2、线索化当前结点
//处理当前结点的前驱结点
//以8为例来理解
//8结点的.left = null,8结点的.leftType = 1
if (node.left == null) {
//让当前结点的左指针指向前驱结点
node.left = pre;
//修改当前结点的左指针的类型,指向前驱结点
node.leftType = 1;
}
//处理后继结点
if (pre != null && pre.right == null) {
//让当前结点的右指针指向当前结点
pre.right = node;
//修改当前结点的右指针的类型=
pre.rightType = 1;
}
//每处理一个结点后,让当前结点是下一个结点的前驱结点
pre = node;
//3、线索化右子树
threadedNodes(node.right);
}
}
class ThreadTreeNode {
int val;
ThreadTreeNode left;
//0为非线索化,1为线索化
int leftType;
ThreadTreeNode right;
//0为非线索化,1为线索化
int rightType;
public ThreadTreeNode(int val) {
this.val = val;
}
}但是在实现Morris遍历的时候,并不需要把结点的左节点线索化,只需要把结点的右节点进行线索化即可,具体的原因在下面进行分析.
上面我们说了Morris遍历的时候只需要线索化右节点,这里给大家进行解释.当我们在中序遍历一棵树的时候,还比如是这样一棵树,我们一步步的node.left来到了6这个结点,这个结点的left为空,所以我们打印6这个结点的值,此时我们需要返回上一个结点,如果我们是要中序递归进行遍历的话,需要返回上一个栈,而我们Morris遍历的时候无法进行递归的返回,所以这个时候我们只需要把6的right结点进行线索化,这个时候6的right指向4,我们就可以返回到4,把4这个结点进行打印,4也线索化返回了2,把2进行打印,然后进行2的right结点5,5的left结点为空,因此打印5,之后进入到5的right结点7,打印7,7的right结点也进行了线索化,进入7的right结点为1,然后打印1,进入3结点并且打印
因为最好不要改变树的结构,所以我们在打印的时候,将线索化的结点的right结点置为空.

Morris遍历是利用了线索二叉树的思想,在遍历的过程中不适用栈,从而达到了空间复杂度为O(1)
具体的实现如下:
1.初始化当前的结点为根结点
2.若当前的结点的左节点为空,则输出当前结点,然后遍历当前结点的右子树,即'curr=curr.right'
3.若当前结点的左节点不为空,则找到当前结点的前驱节点,即当前结点左节点的最右侧结点,记为'prev'
public class Morris {
/**
* 将当前根结点中序遍历的结果存储到list集合中
* @param root 根结点
* @return 中序遍历的结合
*/
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
TreeNode curr = root;
while (curr != null) {
if (curr.left == null) { // 左子树为空,则输出当前节点,然后遍历右子树
res.add(curr.val); //如果要求直接打印,直接输出System.out.println(curr.val);
curr = curr.right;
} else {
// 找到当前节点的前驱节点
TreeNode prev = curr.left;
while (prev.right != null && prev.right != curr) {
prev = prev.right;
}
if (prev.right == null) {
// 将前驱节点的右子树连接到当前节点
prev.right = curr;
curr = curr.left;
} else {
// 前驱节点的右子树已经连接到当前节点,断开连接,输出当前节点,然后遍历右子树
prev.right = null;
res.add(curr.val);//如果要求直接打印,直接输出System.out.println(curr.val);
curr = curr.right;
}
}
}
return res;
}
}
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}测试:
还是这样一颗二叉树,输出如下:
[6, 4, 2, 5, 7, 1, 3]
前序和中序的遍历很想,只不过在打印(收集结点信息的时候不同),中序遍历是在当前结点的左节点为空(curr.left==null),或者当前结点已经被线索化(prev.right==curr)的时候进行打印,仔细观察前序遍历的过程,我们通过修改打印的顺序即可.前序遍历是在当前结点的左节点为空(curr.left==null),或者当前结点没有被线索化(prev.right==null)的时候进行打印
具体的思路如下:
1.初始化当前的结点为根结点
2.若当前的结点的左节点为空,则输出当前结点,然后遍历当前结点的右子树,即'curr=curr.right'
3.若当前结点的左节点不为空,则找到当前结点的前驱节点,即当前结点左节点的最右侧结点,记为'prev'

public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
TreeNode curr = root;
while (curr != null) {
if (curr.left == null) { // 左子树为空,则输出当前节点,然后遍历右子树
res.add(curr.val);//如果要求直接打印,直接输出System.out.println(curr.val);
curr = curr.right;
} else {
// 找到当前节点的前驱节点
TreeNode prev = curr.left;
while (prev.right != null && prev.right != curr) {
prev = prev.right;
}
if (prev.right == null) {
res.add(curr.val);//如果要求直接打印,直接输出System.out.println(curr.val);
// 将前驱节点的右子树连接到当前节点
prev.right = curr;
curr = curr.left;
} else {
// 前驱节点的右子树已经连接到当前节点,断开连接,输出当前节点,然后遍历右子树
prev.right = null;
curr = curr.right;
}
}
}
return res;
}测试:
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.left.right = new TreeNode(5);
root.left.right.right = new TreeNode(7);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.left.left = new TreeNode(6);
System.out.println(preorderTraversal(root));
}
还是这样一颗二叉树,输出如下:
[1, 2, 4, 6, 5, 7, 3]
后序Morris遍历实现起来有一定的难度,但是基本代码还是不变,只是在打印的地方有略微的区别,
具体的思路如下:
1.初始化当前的结点为根结点
2.若当前的结点的左节点为空,则输出当前结点,然后遍历当前结点的右子树,即'curr=curr.right'
3.若当前结点的左节点不为空,则找到当前结点的前驱节点,即当前结点左节点的最右侧结点,记为'prev'
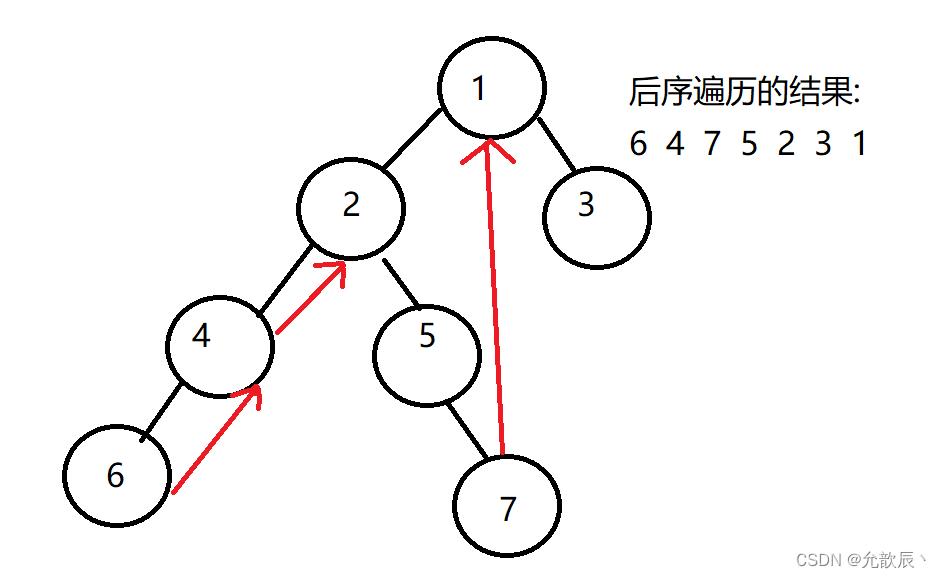
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
TreeNode dump = new TreeNode(0);//建立一个临时结点
dump.left = root; //设置dump的左节点为root
TreeNode curr = dump; //当前节点为dump
while (curr != null) {
if (curr.left == null) { // 左子树为空,则输出当前节点,然后遍历右子树
curr = curr.right;
} else {
// 找到当前节点的前驱节点
TreeNode prev = curr.left;
while (prev.right != null && prev.right != curr) {
prev = prev.right;
}
if (prev.right == null) {
// 将前驱节点的右子树连接到当前节点
prev.right = curr;
curr = curr.left;
} else {
reverseAddNodes(curr.left, prev, res);
// 前驱节点的右子树已经连接到当前节点,断开连接,输出当前节点,然后遍历右子树
prev.right = null;
curr = curr.right;
}
}
}
return res;
}
private void reverseAddNodes(TreeNode begin, TreeNode end, List<Integer> res) {
reverseNodes(begin, end); //将begin到end的进行逆序连接
TreeNode curr = end;
while (true) {//将逆序连接后端begin到end添加
res.add(curr.val);
if (curr == begin)
break;
curr = curr.right;
}
reverseNodes(end, begin);//恢复之前的连接状态
}
/**
* 将begin到end的进行逆序连接
*
* @param begin
* @param end
*/
private void reverseNodes(TreeNode begin, TreeNode end) {
TreeNode prev = begin;
TreeNode curr = prev.right;
TreeNode post;
while (prev != end) {
post = curr.right;
curr.right = prev;
prev = curr;
curr = post;
}
}测试:
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.left.right = new TreeNode(5);
root.left.right.right = new TreeNode(7);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.left.left = new TreeNode(6);
System.out.println(postorderTraversal(root));
}还是这样一颗二叉树,输出如下:
[6, 4, 7, 5, 2, 3, 1]
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我正在使用Rails3.2.2并希望递归加载某个目录中的所有代码。例如:[Railsroot]/lib/my_lib/my_lib.rb[Railsroot]/lib/my_lib/subdir/support_file_00.rb[Railsroot]/lib/my_lib/subdir/support_file_01.rb...基于谷歌搜索,我试过:config.autoload_paths+=["#{Rails.root.to_s}/lib/my_lib/**"]config.autoload_paths+=["#{Rails.root.to_s}/lib/my_lib/**/"
我想从0到2循环@a:0,1,2,0,1,2。defset_aif@a==2@a=0else@a=@a+1endend也许有更好的方法? 最佳答案 (0..2).cycle(3){|x|putsx}#=>0,1,2,0,1,2,0,1,2item=[0,1,2].cycle.eachitem.next#=>0item.next#=>1item.next#=>2item.next#=>0... 关于ruby-循环遍历数组的元素,我们在StackOverflow上找到一个类似的问题:
我在MySql中进行了查询,但在Rails和mysql2gem中工作。信息如下:http://sqlfiddle.com/#!2/9adb8/6查询工作正常,没有问题,并显示以下结果:UNITV1A1N1V2A2N2V3A3N3V4A4N4V5A5N5LIFE200120000000000ROB010012000000000-为rails2.3.8安装了mysql2gemgeminstallmysql2-v0.2.6-创建Controller:classPolicyController这是日志:SQL(0.9ms)selectdistinct@sql:=concat('SELECTpb
我一直在尝试使用简单的递归方法在Ruby中为一个更大的程序的一部分实现目录遍历。但是我发现Dir.foreach不包括其中的目录。我怎样才能列出它们?代码:defwalk(start)Dir.foreach(start)do|x|ifx=="."orx==".."nextelsifFile.directory?(x)walk(x)elseputsxendendend 最佳答案 问题是每次递归,你传递给File.directory?的路径isno只是实体(文件或目录)名称;所有上下文都丢失了。所以说你进入one/two/three/检
我有一个包含“日期”和“频率”字段的模型(频率是一个整数)。我正在尝试获取每个日期的前5个频率。本质上我想按日期分组,然后获得每组的前5名。到目前为止,我只检索组中的前1名:Observation.channel("channelOne").order('date','frequencydesc').group(:date).having('frequency=MAX(frequency)')我想要MAX(frequency)加上第二、第三、第四和第五大PERDATE。抱歉,如果这真的很简单或者我的术语不正确;我刚开始使用Rails:) 最佳答案
我想遍历目录中的每个jpg/jpeg文件以及每个子目录和该子目录的每个子目录等等。我希望能够浏览文件夹中的每个图像文件。有没有一种简单的方法可以做到这一点,或者递归方法是否效果最好? 最佳答案 Dir.glob("your_directory/**/*.{jpg,jpeg}") 关于ruby-遍历目录和子目录中的每个.jpg或.jpeg文件,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questi