
目录
在Selenium中,通过在ChromeDriver类中的get方法里输入网址,即可打开一个页面,例如你要打开百度的网址,如下代码:
ChromeDriver driver = new ChromeDriver();
driver.get("https://www.baidu.com/");
Ps:本文讲的所有API都是基于谷歌浏览器驱动,也就是ChromeDriver类下的API~
在Selenium中,在打开页面的情况下,通过indElement方法,输入By类(通过什么方式来定位元素)参数,即可定位页面元素。
例如定位百度页面的“百度一下”按钮,如下代码:
driver.findElement(By.cssSelector("#su"));//#su就是"百度一下"的CSS选择器
上述栗子中使用的是CSS选择器定位,你也可以使用xpath来定位~
详细的,如下:
By类中最常用的两个定位方法:
1. cssSelector(),它可以通过css选择器来定位元素;(推荐使用)
2. className(),它可以通过xpath来定位元素;
xpath如何使用呢?
最常用的是用层级的方式来表示: /子级 //跳级;(@为属性)
例如:谷歌浏览器中的Google标志
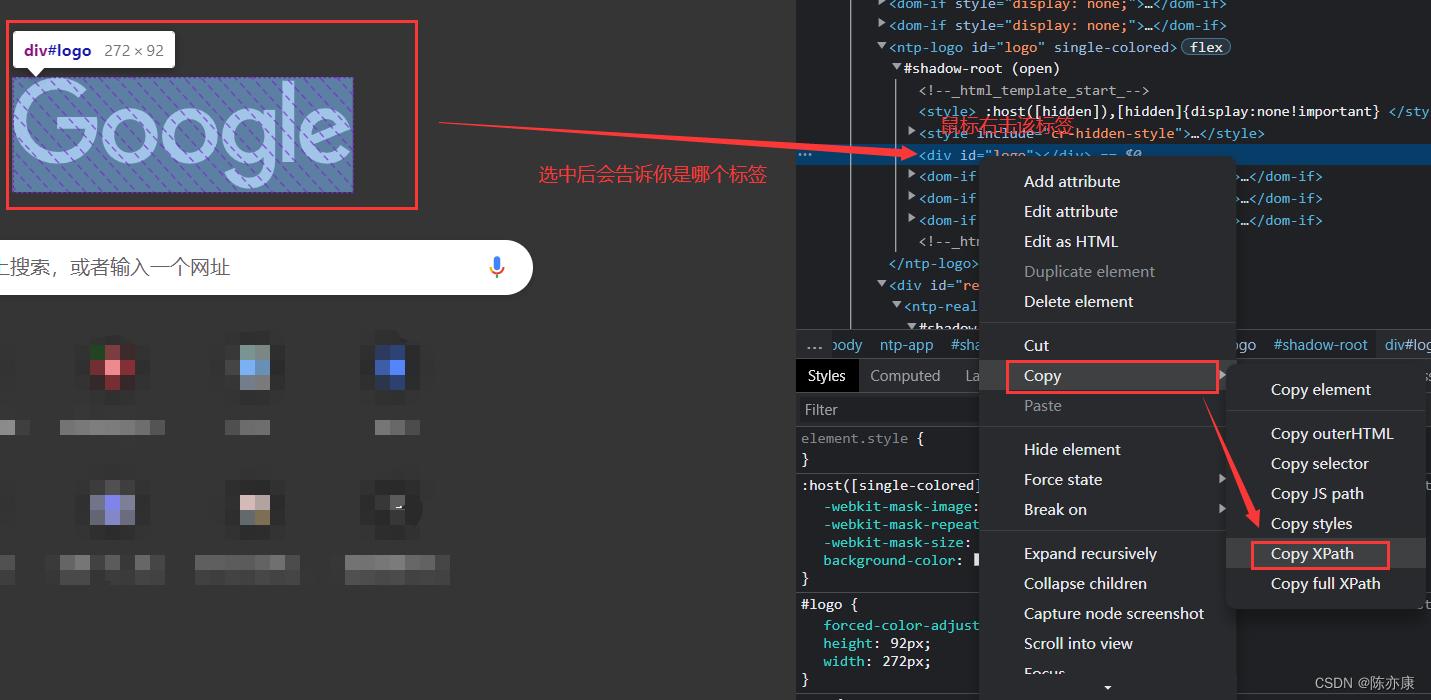
这样你就可以拿到这个标签的xpath://*[@id="logo"] 这便是跳级(前面的路径都不显示,直接表示属性id=“logo”这个标签)
或者是xpath://*[@id="csdn-copyright-footer"]/ul[1]/li[2]/a 这便是一个跳级加子集的方式;
值得注意的是:我们不要一个一个去推这个子集表示的方式,可以直接按照上图的方式进行拷贝xpath路径,配合着className()方法使用即可,但是有时候赋值selector或者xpath元素不一定是唯一的,需要我们进行手动修改到唯一(检查的时候通过 ctrl + f 即可检查是否唯一),这就是为什么我们要对xpath的语法要有一定了解的原因;
在Selenium中,使用sendKeys方法即可对你选中的元素进行输入文本,但是仅适用于文本文字和内容可以编辑的元素,例如在百度页面的搜索框内输入“你好”,如下代码:
//先使用findElement定位元素(返回一个WebElement类型的元素),再对定位的元素进行输入文本
driver.findElement(By.cssSelector("#kw")).sendKeys("你好");Ps:即使反向操作,也就是对不可编辑的元素进行操作,也不会报错,但是不会产生任何实际效果。
在Selenium中,对你定位到的元素使用click方法,即可进行鼠标点击操作,例如点击百度界面的“百度一下”按钮,代码如下:
//先使用findElement定位元素(返回一个WebElement类型的元素),再进行click
driver.findElement(By.cssSelector("#su")).click();
提交操作是干什么的?实际上就和你按下Enter键的效果是一样的,通过submit方法即可实现,例如在百度页面通过submit方法实现自动按下回车键,如下代码:
//先使用findElement定位元素(返回一个WebElement类型的元素),再进行submit
driver.findElement(By.cssSelector("#su")).submit();
Ps:selenium官方不推荐使用submit,更推荐click,因为可以使用submit的地方click都能代替,并且click使用场景更广(submit仅适用于表单元素)。
在Selenium中,可以使用clear将你定位的元素的文本内容进行清除,例如清除百度输入框中的文本,如下代码:
driver.findElement(By.cssSelector("#kw")).clear();
Ps:用来频繁的测试是否可以重复输入(适用sendKeys输入后,在用clear清除、再输入然后清除......)。
在Selenium中,通过getText可以获取你定位的元素的文本,例如获取百度页面热搜中的文本,如下代码:
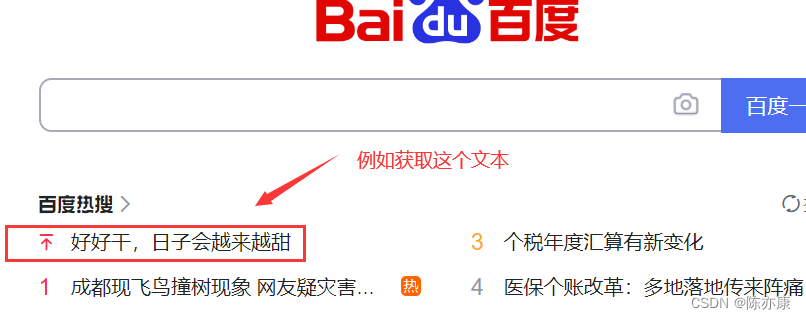
//获取到的文本返回值是一个String类型
String text = driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1) > a > span.title-content-title")).getText();
System.out.println(text);但如果你要获取“百度一下”这个按钮的文本就无法获取(但程序不会报错,只是返回一个空字符串),因为这个元素它不含文本,只有一些属性(id、class、type、value......),如下F12检查可以看到:

所以我们只能获取它的属性,那么属性该如何获取呢?通过getAttribute方法即可获取到,方式和获取文本一样,先定位元素,再获取;例如你要获取class属性,那么就是getAttribute("class);
在Selenium中,这个没什么特别要注意的点,基础操作,直接上代码:
System.out.println(driver.getTitle());
System.out.println(driver.getCurrentUrl());
在Selenium中,可以设置窗口的大小:最大化、最小化、全屏窗口、手动设置窗口大小;如下代码:
//窗口最大化
driver.manage().window().maximize();
//窗口最小化
driver.manage().window().minimize();
//全屏
driver.manage().window().fullscreen();
//手动设置大小(按顺序分别是宽和高)
driver.manage().window().setSize(new Dimension(1024, 500));
想象这样一个场景,我们使用Selenium打开一个网页,在从这个网页通过click点击超链接打开另一个网页,那么我们继续使用Selenium操作网页时,是对刚刚这两个网页中的哪一个网页进行操作?实际上还是第一个网页,如果你一意孤行还认为是对第二个网页进行操作,就有可能引发如下异常:(找不到该元素)

实际上,当浏览器每次打开一个标签页的时候,都会自动给每个标签页进行标识,也叫做“句柄”。
在Selenium中,我们有如下两种方式获得句柄:
//获取所有标签页的句柄
Set<String> handles = driver.getWindowHandles();
//获取当前页面的句柄
String curHandle = driver.getWindowHandle();
并且哪个页面对应哪个句柄,我们是不可知的,例如我打开了两个页面,获取句柄并打印,如下:

//获取当前页面的句柄
String curHandle = driver.getWindowHandle();
//切换到curHandle句柄
driver.switchTo().window(curHandle);
Ps:自动化基本没有需要切换窗口的场景,因为要进行测试,就直接拿到这个网页的地址即可,没必要这样切换!
想象一下,程序执行的速度 和 页面渲染的速度 谁快?必然是程序执行快,那么当代码执行到查找结果页的元素时,页面还没有加载完全,程序就会报错,如下代码:
public void test2() {
ChromeDriver driver = new ChromeDriver();
//打开百度页面
driver.get("https://www.baidu.com");
//在输入框中输入"你好"
driver.findElement(By.cssSelector("#kw")).sendKeys("你好");
//点击“百度一下”按钮
driver.findElement(By.cssSelector("#su")).click();
//点击一个搜索结果
driver.findElement(By.cssSelector("#\\31 > div > div > h3 > a")).click();
driver.close();
}
报错,如下图(找不到该元素)

解决办法:在点击“百度一下”这个按钮以后,休眠几秒即可(等待页面加载出来)。
但是自动化程序执行的速度非常快,我们怎么能知道这个地方出了什么问题呢?接着往下看~
首先需要在pom.xml中导入依赖,如下:
<!-- 保存屏幕截图文件需要用到的包 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>接着如下代码:
public void test2() throws IOException {
ChromeDriver driver = new ChromeDriver();
//打开百度页面
driver.get("https://www.baidu.com");
//在输入框中输入"你好"
driver.findElement(By.cssSelector("#kw")).sendKeys("你好");
//点击“百度一下”按钮
driver.findElement(By.cssSelector("#su")).click();
//屏幕截图(保存现场)
File srcfile = driver.getScreenshotAs(OutputType.FILE);//FILE表示以文件的形式保存
//把截图保存到指定路径下
String filename = "my.png";//没输入路径,就是当前项目下
FileUtils.copyFile(srcfile, new File(filename));
//点击一个搜索结果
driver.findElement(By.cssSelector("#\\31 > div > div > h3 > a")).click();
driver.close();
}
接着就可以观察到截图如下:
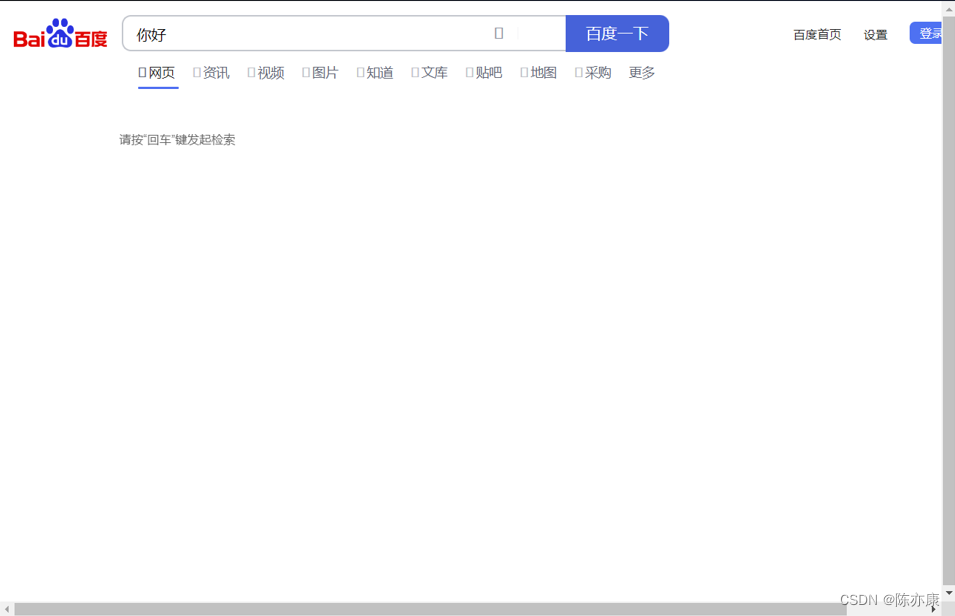
这样我们就可以发现原因,是由于页面没有加载出来的原因~
Ps:保存截图的时候,文件名时固定的格式(已经存在重名文件),程序多次生成的截图都会被同名覆盖,为了避免这个情况,我们可以将文件名设置为动态的,也就是加入时间戳。

大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear