在上一篇文章中我们学习了DOM,接下来让我们先通过和DOM的对比来简单了解一下BOM
首先我们先来复习一下DOM:
然后我们来介绍一下BOM:
BOM(Browser Object Model)即浏览器对象模型,它提供了独立于内容而与浏览器窗口进行交互的对象,其核心对象是window
BOM由一系列相关的对象构成,并且每个对象都提供了很多方法和属性(BOM包含DOM)
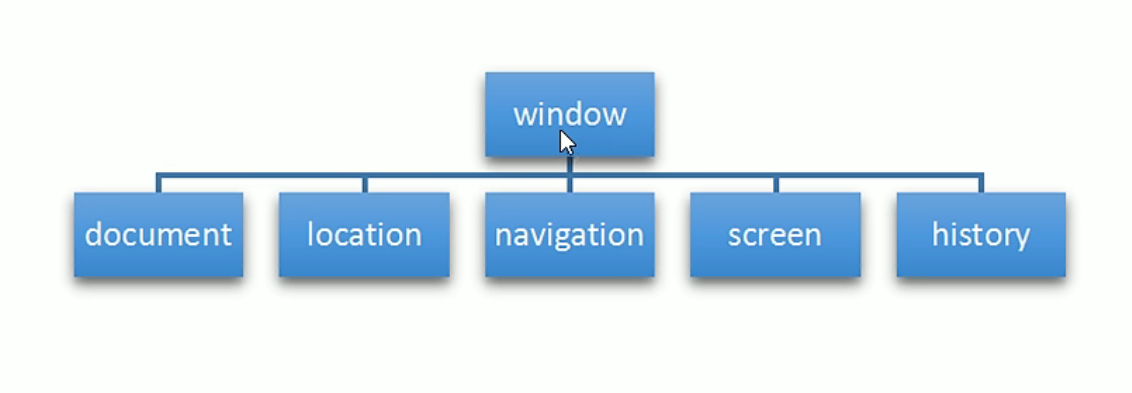
window对象是浏览器的顶级对象,它具有双重角色:
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
// window是BOM的顶级对象,我们所定义的属性和方法都属于window
// 我们定义一个属性(可以加上window前缀)
var code = 123;
console.log(window.code);
// 我们定义一个方法(可以加上window前缀)
var fn = function() {
// alert也属于window的方法
window.alert('11');
}
window.fn();
</script>
</body>
</html>
我们的JavaScript代码常常在HTML和CSS构造之后才会运行,因而JavaScript代码常常放于HTML的body底部
但是window的窗口加载事件可以改变我们的JavaScript书写位置:
window.onload = function(){}
window.addEventListener('load',function(){})
window.onload是窗口加载事件,当文档内容完全加载完成后会触发该事件,调用其内部的处理函数
document.addEventListener('DOMContentLoaded',function(){})
DOMContentLoaded事件触发,代表仅当DOM加载完毕(不包括图片,flash等)就会执行内部处理函数
注意:
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<!-- 正常情况下,我们的script应该写在body末尾,写在这个部分是无法正常使用的 -->
<script>
// 这时就需要采用页面加载事件来等待页面加载完成后再去加载JavaScript内容
// window.onload方法在整个script中只能使用一次,不推荐
window.onload = function() {
// 在里面书写内容
var but = document.querySelector('button');
but.onclick = function(){
alert('我是弹窗')
}
}
// window.addEventListener('load',function(){})可以多次调用,推荐使用
window.addEventListener('load',function(){
alert('页面内容加载完成');
})
// document.addEventListener('DOMContentLoaded',function(){})仅针对DOM的加载,DOM加载后即可使用
document.addEventListener('DOMContentLoaded',function(){
alert('DOM内容加载完成');
})
</script>
<button>点我弹出弹窗</button>
</body>
</html>
我们通过手动拉扯页面边框可以调整页面大小:
window.onresize = function(){}
window.addEventListener('resize',function(){})
window.onresize是调整窗口大小加载事件,当触发时调用内部处理函数
注意:
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<!-- 我们设置一下div的大小,我们希望页面小于一定程度,div消失 -->
<style>
div {
height: 200px;
width: 200px;
background-color: pink;
}
</style>
</head>
<body>
<script>
window.addEventListener('load',function(){
// 页面调整大小有两种语法
// window.onresize = function(){}
// window.addEventListener('resize',function({}))
// 其中resize就是调整窗口加载事件,当触发就调用的处理函数
window.addEventListener('resize',function(){
console.log('页面变化了');
})
// 我们希望页面宽度小于800,div隐藏
var div = document.querySelector('div');
window.addEventListener('resize',function(){
if(window.innerWidth < 800){
div.style.display = 'none';
} else {
div.style.display = 'block';
}
})
})
</script>
<div></div>
</body>
</html>
window对象为我们提供了两种定时器:
在讲解定时器之前,我们先来了解一下回调函数:
Timeout分为创建和停止:
//创建方法:
window.setTimeout(调用函数,[延迟毫秒数])
//停止方法:
window.clearTimeout(timeout ID)
setTimeout讲解:
clearTimeout讲解:
注意:
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<button>点击我停止计时器</button>
<script>
// 定时器方法:window.setTimeout(调用函数,{延迟毫秒}),window可以省略
setTimeout(function(){
console.log('3s到了');
},2000)
// 当毫秒数不设置时,默认为0,立即触发
setTimeout(function(){
console.log('立刻触发');
})
// 定时器函数可以是外部函数
function timeback(){
console.log('6s到了');
}
// 我们为了区分定时器,常常会加上标识符
// 当你定义时,这个setTimeout自动开始计时
var timer1 = setTimeout(timeback,6000);
// 我们也可以取消掉定时器setTimeout
// 首先我们定义定时器
var timer = setTimeout(function() {
console.log("10s后爆炸!");
},10000)
// 获得button,在button上捆绑上停止计时器的操作
var button = document.querySelector('button');
button.addEventListener('click',function(){
clearTimeout(timer);
})
</script>
</body>
</html>
Interval分为创建和停止:
//创建方法:
window.setInterval(调用函数,[延迟毫秒数])
//停止方法:
window.clearInterval(Interval ID)
setInterval讲解:
clearInterval讲解:
注意:
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<button class="begin">点击我开启定时器</button>
<button class="end">点击我终止计时器</button>
<script>
var begin = document.querySelector('.begin');
var end = document.querySelector('.end');
// 注意需要把setInterval的名称定义在外面,使其变为全局变量
var timer = null;
begin.addEventListener('click',function(){
// setInterval(回调函数,【间隔秒数】)
timer = setInterval(function(){
console.log('1s');
},1000);
})
end.addEventListener('click',function(){
clearInterval(timer);
})
</script>
</body>
</html>
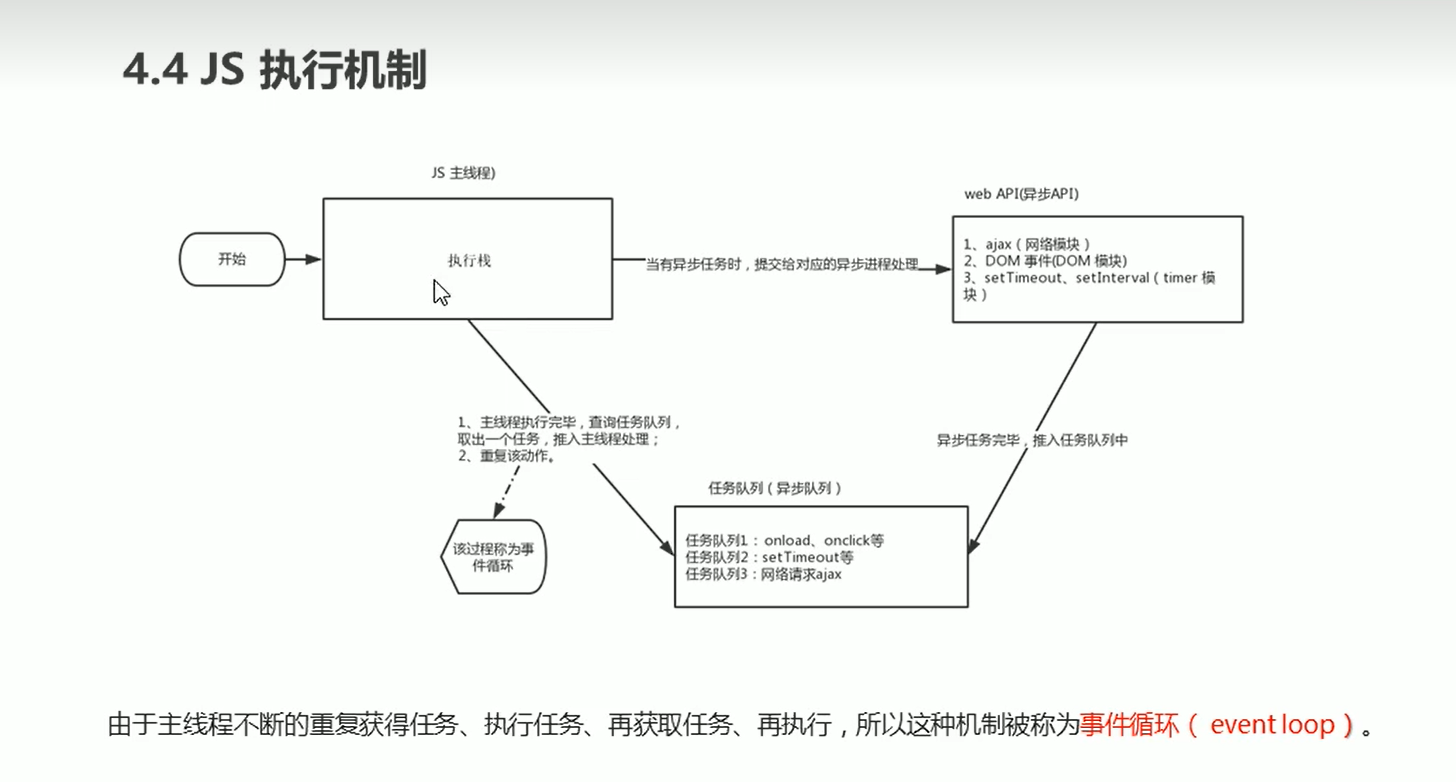
在了解JavaScript的执行机制前,我们需要先了解JavaScript的基本信息:
所以在HTML5中,允许JavaScript脚本建立多个线程,于是出现了同步和异步:
同时也就区分出同步任务和异步任务:
因而JavaScript的执行机制如下:
我们给出一张图片来解释上述内容:
在学习location对象之前,我们先来了解一下URL:
protocol://host[:port]/path/[?query]#fragment
http://www.itcast.cn/index.html?name=andy&age=18#link
| 组成 | 说明 |
|---|---|
| protocol | 通信协议 常用的http,ftp,maito |
| host | 主机(域名) |
| port | 端口号 可选. 省略时使用方案的默认端口 |
| path | 路径 由零个或多个'/'隔开的字符串,一般用来表示主机上的一个目录或文件地址 |
| query | 参数 以键值对的形式,用&隔开 |
| fragment | 片段 #后面内容常用于连接 锚点 |
在了解了URL之后我们来介绍一下location:
| location对象属性和方法 | 返回值 |
|---|---|
| location.href | 获得或设置 整个URL |
| location.host | 返回主机(域名) |
| location.port | 返回端口号 若没有返回空字符串 |
| location.pathname | 返回路径 |
| location.search | 返回参数 |
| location.hash | 返回片段 |
| location.assign | 和href,用来跳转页面(附带历史记录) |
| location.replace | 和href,用来跳转页面(不附带历史记录) |
| location.reload | 重新加载该页面(ctrl+F5) |
代码展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<--我们希望点击该按键后,出现提示n秒后跳转页面,并在倒计时结束后跳转页面-->
</head>
<body>
<button>点击我5s后跳转页面</button>
<div></div>
<script>
var button = document.querySelector('button');
var div = document.querySelector('div');
button.addEventListener('click',function(){
// 在点击后,出现倒计时:
var time = 5;
setInterval(function(){
if(time == 0){
//在这里我们使用href来跳转页面
location.href = 'https://www.baidu.com/';
} else {
// 这里注意div修改文字用innerHTML
div.innerHTML = '还剩下' + time + '秒后跳转页面';
time--;
}
},1000)
})
</script>
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<--这部分我们来讲解location的三种方法-->
</head>
<body>
<button>assign</button>
<button>replaca</button>
<button>reload</button>
<script>
var buttons = document.querySelectorAll('button');
// assign跳转页面,且保留历史记录
buttons[0].addEventListener('click',function(){
location.assign('https://www.baidu.com/');
})
// replace跳转页面,不保留历史记录
buttons[1].addEventListener('click',function(){
location.replace('https://www.baidu.com/');
})
// reload刷新页面,类似于ctrl+f5
buttons[2].addEventListener('click',function(){
location.reload();
})
</script>
</body>
</html>
navigator对象包含有关浏览器的信息,它有很多属性,我们最常用的是userAgent,该属性可以返回由客户机发给服务器的user-agent头部信息,用来判断你目前使用的机型
我们常用下述代码来判断你打开的网页是电脑端还是手机端:
if(navigator.userAgent.match(各种手机品牌)) {
//如果是手机,就转到手机端页面
window.location.href = "https://www.baidu.com/";
} else {
//如果是电脑,就转到电脑端页面
window.location.href = "http://news.baidu.com/";
}
window对象给我们提供了history对象,与浏览器历史记录进行交互,该对象包含了用户访问过的URL
| history对象方法 | 说明 |
|---|---|
| history.back() | 可以后退网页(类似于浏览器自带后退按键) |
| history.forward() | 可以前进网页(类似于浏览器自带前进按键) |
| history.go(参数) | 可以自定义前进后退页面(参数可以是正负数) |
好的,关于BOM的知识我们就讲解到这里,你是否完全明白了呢?
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我遇到了一个非常奇怪的问题,我很难解决。在我看来,我有一个与data-remote="true"和data-method="delete"的链接。当我单击该链接时,我可以看到对我的Rails服务器的DELETE请求。返回的JS代码会更改此链接的属性,其中包括href和data-method。再次单击此链接后,我的服务器收到了对新href的请求,但使用的是旧的data-method,即使我已将其从DELETE到POST(它仍然发送一个DELETE请求)。但是,如果我刷新页面,HTML与"new"HTML相同(随返回的JS发生变化),但它实际上发送了正确的请求类型。这就是这个问题令我困惑的
我正在尝试提取方括号内的内容。到目前为止,我一直在使用它,它有效,但我想知道我是否可以直接在正则表达式中使用某些东西,而不是使用这个删除功能。a="Thisissuchagreatday[coolawesome]"a[/\[.*?\]/].delete('[]')#=>"coolawesome" 最佳答案 差不多。a="Thisissuchagreatday[coolawesome]"a[/\[(.*?)\]/,1]#=>"coolawesome"a[/(?"coolawesome"第一个依赖于提取组而不是完全匹配;第二个利用前瞻和
使用Ruby1.8.6/Rails2.3.2我注意到在我的任何ActiveRecord模型类上调用的任何方法都返回nil而不是NoMethodError。除了烦人之外,这还破坏了动态查找器(find_by_name、find_by_id等),因为即使存在记录,它们也总是返回nil。不从ActiveRecord::Base派生的标准类不受影响。有没有办法追踪在ActiveRecord::Base之前拦截method_missing的是什么?更新:切换到1.8.7后,我发现(感谢@MichaelKohl)will_paginate插件首先处理method_missing。但是will_pa
我有这个:AccountSummary我想单击该链接,但在使用link_to时出现错误。我试过:bot.click(page.link_with(:href=>/menu_home/))bot.click(page.link_with(:class=>'top_level_active'))bot.click(page.link_with(:href=>/AccountSummary/))我得到的错误是:NoMethodError:nil:NilClass的未定义方法“[]” 最佳答案 那是一个javascript链接。Mechan
我试图像这样在我的测试用例中执行获取:request.env['CONTENT_TYPE']='application/json'get:index,:application_name=>"Heka"虽然,它失败了:ActionView::MissingTemplate:Missingtemplatealarm_events/indexwith{:handlers=>[:builder,:haml,:erb,:rjs,:rhtml,:rxml],:locale=>[:en,:en],:formats=>[:html]尽管在我的Controller中我有:respond_to:html,
我的测试尝试访问网页并验证页面上是否存在某些元素。例如,它访问http://foo.com/homepage.html并检查Logo图像,然后访问http://bar.com/store/blah.html并检查页面上是否出现了某些文本。我的目标是访问经过Kerberos身份验证的网页。我发现Kerberos代码如下:主文件uri=URI.parse(Capybara.app_host)kerberos=Kerberos.new(uri.host)@kerberos_token=kerberos.encoded_tokenkerberos.rb文件classKerberosdefini