目前看来,yolo系列是工程上使用最为广泛的检测模型之一。yolov5检测性能优秀,部署便捷,备受广大开发者好评。但是,当模型在前端运行时,对模型尺寸与推理时间要求苛刻,轻量型模型yolov5s也难以招架。为了提高模型效率,这里与大家分享基于yolov5的模型剪枝方法 github分享连接。
本次使用稀疏训练对channel维度进行剪枝,来自论文Learning Efficient Convolutional Networks Through Network Slimming。其实原理很容易理解,我们知道bn层中存在两个可训练参数
γ
,
β
\gamma,\beta
γ,β,输入经过bn获得归一化后的分布。当
γ
,
β
\gamma,\beta
γ,β趋于0时,输入相当于乘上了0,那么,该channel上的卷积将只能输出0,毫无意义。因此,我们可以认为剔除这样的冗余channel对模型性能影响甚微。普通网络训练时,由于初始化,
γ
\gamma
γ一般分布在1附近。为了使
γ
\gamma
γ趋于0,可以通过添加L1正则来约束,使得系数稀疏化,论文中将添加
γ
\gamma
γL1正则的训练称为稀疏训练。
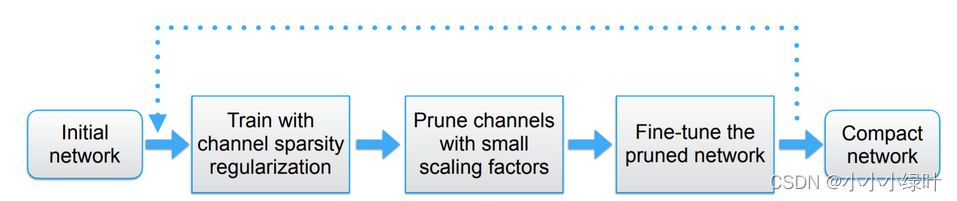
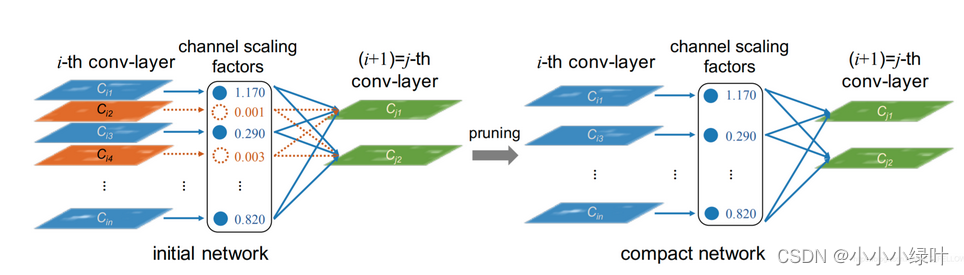 整个剪枝的过程如下图所示,首先初始化网络,对bn层的参数添加L1正则并对网络训练。统计网络中的
γ
\gamma
γ,设置剪枝率对网络进行裁剪。最后,将裁减完的网络finetune,完成剪枝工作。
整个剪枝的过程如下图所示,首先初始化网络,对bn层的参数添加L1正则并对网络训练。统计网络中的
γ
\gamma
γ,设置剪枝率对网络进行裁剪。最后,将裁减完的网络finetune,完成剪枝工作。
1.稀疏训练
上一章介绍了稀疏训练的原理,下面看一下代码是如何实现的。代码如下所示,首先,我们需要设置稀疏系数,稀疏系数对整个网络剪枝性能至关重要,设置太小的系数,
γ
\gamma
γ趋于0的程度不高,无法对网络进行高强度的剪枝,但设置过大,会影响网络性能,大幅降低map。因此,我们需要通过实验找到合适的稀疏系数。
bn层的训练参数包括
γ
,
β
\gamma,\beta
γ,β,即代码中的m.weight,m.bias,loss.backward之后,在这两个参数的梯度上添加L1正则的梯度即可。
srtmp = opt.sr * (1 - 0.9 * epoch/epochs)
for k, m in model.named_modules():
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
2.网络裁剪
上一步获得稀疏训练后的网络,接下来,我们需要将
γ
\gamma
γ趋于0的channel裁剪掉。首先,统计所有BN层的
γ
\gamma
γ,并对齐排序,找到剪枝率对应的阈值thre。
for i, layer in model.named_modules():
if isinstance(layer, nn.BatchNorm2d):
if i not in ignore_bn_list:
model_list[i] = layer
# bnw = layer.state_dict()['weight']
model_list = {k:v for k,v in model_list.items() if k not in ignore_bn_list}
prune_conv_list = [layer.replace("bn", "conv") for layer in model_list.keys()]
bn_weights = gather_bn_weights(model_list)
sorted_bn = torch.sort(bn_weights)[0]
thre_index = int(len(sorted_bn) * opt.percent)
thre = sorted_bn[thre_index]
然后,根据阈值获取每一bn层的mask,这里加了一些逻辑,目的是让剪枝后的channel保证是4的倍数,即复合前端加速要求。
def obtain_bn_mask(bn_module, thre):
thre = thre.cuda()
bn_layer = bn_module.weight.data.abs()
temp = abs(torch.sort(bn_layer)[0][3::4] - thre)
thre_temp = torch.sort(bn_layer)[0][3::4][temp.argmin()]
if int(temp.argmin()) == 0 and thre_temp > thre:
thre = -1
else:
thre = thre_temp
thre_index = int(bn_layer.shape[0] * 0.9)
if thre_index % 4 != 0:
thre_index -= thre_index % 4
thre_perbn = torch.sort(bn_layer)[0][thre_index - 1]
if thre_perbn < thre:
thre = min(thre, thre_perbn)
mask = bn_module.weight.data.abs().gt(thre).float()
return mask
由于,剪枝后的网络与原网络channel不能对齐,因此,我们需要重新定义网络,并解析网络。重构的网络结构需要重新定义,因为需要导入更多的参数。
pruned_yaml["backbone"] =[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3Pruned, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3Pruned, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3Pruned, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3Pruned, [1024]],
[-1, 1, SPPFPruned, [1024, 5]], # 9
]
pruned_yaml["head"] = [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3Pruned, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3Pruned, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3Pruned, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3Pruned, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov5的backbone与neck存在C3结构,C3中存在shortcut,即存在两个卷积相加的形式。为了使网络能够正常add,我们需要对add的两个卷积mask进行merge操作。与此同时,网络存在concate,所以还需要记录concate来自于哪些层以及concate输出的层。
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
named_m_base = "model.{}".format(i)
if m in [Conv]:
named_m_bn = named_m_base + ".bn"
bnc = int(maskbndict[named_m_bn].sum())
c1, c2 = ch[f], bnc
args = [c1, c2, *args[1:]]
layertmp = named_m_bn
if i>0:
from_to_map[layertmp] = fromlayer[f]
fromlayer.append(named_m_bn)
elif m in [C3Pruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
named_m_cv3_bn = named_m_base + ".cv3.bn"
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = fromlayer[f]
fromlayer.append(named_m_cv3_bn)
if len(args) == 1:
temp_mask = maskbndict[named_m_cv1_bn].bool() | maskbndict[named_m_base + '.m.0.cv2.bn'].bool()
maskbndict[named_m_cv1_bn], maskbndict[named_m_base + '.m.0.cv2.bn'] = temp_mask.float(), temp_mask.float()
if n > 1:
for repeat_ind in range(1, n):
temp_mask |= maskbndict[named_m_base + ".m.{}.cv2.bn".format(repeat_ind)].bool()
for re_ind in range(n):
maskbndict[named_m_base + ".m.{}.cv2.bn".format(re_ind)] = temp_mask
maskbndict[named_m_cv1_bn], maskbndict[named_m_base + '.m.0.cv2.bn'] = temp_mask.float(), temp_mask.float()
cv1in = ch[f]
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
cv3out = int(maskbndict[named_m_cv3_bn].sum())
args = [cv1in, cv1out, cv2out, cv3out, n, args[-1]]
bottle_args = []
chin = [cv1out]
c3fromlayer = [named_m_cv1_bn]
for p in range(n):
named_m_bottle_cv1_bn = named_m_base + ".m.{}.cv1.bn".format(p)
named_m_bottle_cv2_bn = named_m_base + ".m.{}.cv2.bn".format(p)
bottle_cv1in = chin[-1]
bottle_cv1out = int(maskbndict[named_m_bottle_cv1_bn].sum())
bottle_cv2out = int(maskbndict[named_m_bottle_cv2_bn].sum())
chin.append(bottle_cv2out)
bottle_args.append([bottle_cv1in, bottle_cv1out, bottle_cv2out])
from_to_map[named_m_bottle_cv1_bn] = c3fromlayer[p]
from_to_map[named_m_bottle_cv2_bn] = named_m_bottle_cv1_bn
c3fromlayer.append(named_m_bottle_cv2_bn)
args.insert(4, bottle_args)
c2 = cv3out
n = 1
from_to_map[named_m_cv3_bn] = [c3fromlayer[-1], named_m_cv2_bn]
elif m in [SPPFPruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
cv1in = ch[f]
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = [named_m_cv1_bn]*4
fromlayer.append(named_m_cv2_bn)
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
args = [cv1in, cv1out, cv2out, *args[1:]]
c2 = cv2out
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
inputtmp = [fromlayer[x] for x in f]
fromlayer.append(inputtmp)
elif m is Detect:
from_to_map[named_m_base + ".m.0"] = fromlayer[f[0]]
from_to_map[named_m_base + ".m.1"] = fromlayer[f[1]]
from_to_map[named_m_base + ".m.2"] = fromlayer[f[2]]
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
fromtmp = fromlayer[-1]
fromlayer.append(fromtmp)
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save), from_to_map
重构并解析网络后,我们需要对解析后的网络填充参数,即找到解析后网络对应于原网络的各层参数,并clone赋值给重构后的网络,代码如下:
for ((layername, layer),(pruned_layername, pruned_layer)) in zip(model.named_modules(), pruned_model.named_modules()):
assert layername == pruned_layername
if isinstance(layer, nn.Conv2d) and not layername.startswith("model.24"):
convname = layername[:-4]+"bn"
if convname in from_to_map.keys():
former = from_to_map[convname]
if isinstance(former, str):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
w = layer.weight.data[:, in_idx, :, :].clone()
if len(w.shape) ==3: # remain only 1 channel.
w = w.unsqueeze(1)
w = w[out_idx, :, :, :].clone()
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(former, list):
orignin = [modelstate[i+".weight"].shape[0] for i in former]
formerin = []
for it in range(len(former)):
name = former[it]
tmp = [i for i in range(maskbndict[name].shape[0]) if maskbndict[name][i] == 1]
if it > 0:
tmp = [k + sum(orignin[:it]) for k in tmp]
formerin.extend(tmp)
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
pruned_layer.weight.data = w[:,formerin, :, :].clone()
changed_state.append(layername + ".weight")
else:
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername[:-4] + "bn"].cpu().numpy())))
w = layer.weight.data[out_idx, :, :, :].clone()
assert len(w.shape) == 4
pruned_layer.weight.data = w.clone()
changed_state.append(layername + ".weight")
if isinstance(layer,nn.BatchNorm2d):
out_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[layername].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[out_idx].clone()
pruned_layer.bias.data = layer.bias.data[out_idx].clone()
pruned_layer.running_mean = layer.running_mean[out_idx].clone()
pruned_layer.running_var = layer.running_var[out_idx].clone()
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
changed_state.append(layername + ".running_mean")
changed_state.append(layername + ".running_var")
changed_state.append(layername + ".num_batches_tracked")
if isinstance(layer, nn.Conv2d) and layername.startswith("model.24"):
former = from_to_map[layername]
in_idx = np.squeeze(np.argwhere(np.asarray(maskbndict[former].cpu().numpy())))
pruned_layer.weight.data = layer.weight.data[:, in_idx, :, :]
pruned_layer.bias.data = layer.bias.data
changed_state.append(layername + ".weight")
changed_state.append(layername + ".bias")
至此,我们完成了剪枝的所有步骤。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序